







简述
- 极大似然估计(Maximum likelihood estimation, 简称MLE)也称最大似然估计。是一种概率论在统计学的应用,它是参数估计的方法之一。说的是已知某个随机样本满足某种概率分布,但是其中具体的参数不清楚,参数估计就是通过若干次试验,观察其结果,利用结果推出参数的大概值。极大似然估计是建立在这样的思想上:已知某个参数能使这个样本出现的概率最大,我们当然不会再去选择其他小概率的样本,所以干脆就把这个参数作为估计的真实值。
- 最大后验概率估计(Maximum a posteriori estimation, 简称MAP)。在贝叶斯统计学中,“最大后验概率估计”是后验概率分布的众数。利用最大后验概率估计可以获得对实验数据中无法直接观察到的量的点估计。它与最大似然估计中的经典方法有密切关系,但是它使用了一个增广的优化目标,进一步考虑了被估计量的先验概率分布。所以最大后验概率估计可以看作是规则化(regularization)的最大似然估计。
听到这几个名字第一反应是数学,第二反应这些都是什么啊,作为搞机器学习的同学们也是一知半解,那么就花个时间好好掰扯掰扯吧~
先扯几个概念预热一下。。。
贝叶斯公式
学习机器学习和模式识别的人一定都听过贝叶斯公式(Bayes’ Theorem):
P ( A ∣ B ) = P ( B ∣ A ) P ( A ) P ( B ) P(A|B) = \frac{P(B|A)P(A)}{P(B)} P(A∣B)=P(B)P(B∣A)P(A)【式1】
贝叶斯公式看起来很简单,无非是倒了倒条件概率和联合概率的公式。
把B展开,可以写成:
P ( A ∣ B ) = P ( B ∣ A ) P ( A ) P ( B ∣ A ) P ( A ) + P ( B ∣ ∼ A ) P ( ∼ A ) P(A|B) = \frac{P(B|A)P(A)}{P(B|A)P(A) + P(B|\sim A)P(\sim A)} P(A∣B)=P(B∣A)P(A)+P(B∣∼A)P(∼A)P(B∣A)P(A)【式2】( ∼ A \sim A ∼A表示"非A")
概率和统计是什么意思呢?有什么区别?
概率和统计两个词语在中文上看似是一个很相近的意思,但是呢,在研究问题上可是正好相反的。
概率研究的问题是,已知一个模型和参数,怎么去预测这个模型产生的结果的特性(例如均值,方差,协方差等等)。 举个例子,我想研究怎么养猪(模型是猪),我选好了想养的品种、喂养方式、猪棚的设计等等(选择参数),我想知道我养出来的猪大概能有多肥,肉质怎么样(预测结果)。
**统计研究的问题则相反。统计是,有一堆数据,要利用这堆数据去预测模型和参数。**仍以猪为例。现在我买到了一堆肉,通过观察和判断,我确定这是猪肉(这就确定了模型。在实际研究中,也是通过观察数据推测模型是/像高斯分布的、指数分布的、拉普拉斯分布的等等),然后,可以进一步研究,判定这猪的品种、这是圈养猪还是跑山猪还是网易猪,等等(推测模型参数)。
一句话总结:概率是已知模型和参数,推数据。统计是已知数据,推模型和参数。
显然,本文要说的MLE和MAP都是属于统计领域的问题。
在统计学中,似然函数和概率函数的区别
对于这个函数:
P
(
x
∣
θ
)
P(x|\theta)
P(x∣θ)
输入有两个:
x
x
x表示某一个具体的数据;
θ
\theta
θ表示模型的参数。
如果 θ \theta θ是已知确定的, x x x是变量,这个函数叫做概率函数(probability function),它描述对于不同的样本点 x x x,其出现概率是多少。
如果 x x x是已知确定的, θ \theta θ是变量,这个函数叫做似然函数(likelihood function), 它描述对于不同的模型参数,出现 x x x这个样本点的概率是多少。
知道了这个区别后,极大似然函数就好理解啦
极大似然函数
极大似然估计的核心思想是:认为当前发生的事件是概率最大的事件。因此就可以给定数据集,使得该数据集发生的概率最大来求得模型中的参数。
求对数似然函数最大化,可以通过一阶优化算法如SGD或者二阶优化算法如Newton求解。
极大似然估计只关注当前的样本,也就是只关注当前发生的事情,不考虑事情的先验情况。由于计算简单,而且不需要关注先验知识,因此在机器学习中的应用非常广。
插播----MLE和loss function的关系
损失函数是作为模型的优化目标的度量。损失函数比单纯的 MLE 更通用。
MLE 是一种特定类型的概率模型估计,其中损失函数是(对数)似然。MLE 是推导概率模型损失函数的一种方法(例如二元交叉熵可由伯努利分布的最大似然公式求解推导而来,mse可以由高斯分布的最大似然公式求解推导而来)。
但是后深度时代,loss function的概念已经非常复杂了,例如多任务学习下就很难使用MLE来进行推导,因此loss function的定义要比单纯的MLE推导出来的部分loss function的定义要更加通用。
举个栗子说一下极大似然函数
假设有一个造币厂生产某种硬币,现在我们拿到了一枚这种硬币,想试试这硬币是不是均匀的。即想知道抛这枚硬币,正反面出现的概率(记为 θ \theta θ)各是多少?
这是一个统计问题,回想一下,解决统计问题需要什么? 数据!
于是我们拿这枚硬币抛了10次,得到的数据( x 0 x_0 x0)是:反正正正正反正正正反。我们想求的正面概率 θ \theta θ是模型参数,而抛硬币模型我们可以假设是二项分布。
那么,出现实验结果 x 0 x_0 x0(即反正正正正反正正正反)的似然函数是多少呢?
f ( x 0 , θ ) = ( 1 − θ ) × θ × θ × θ × θ × ( 1 − θ ) × θ × θ × θ × ( 1 − θ ) = θ 7 ( 1 − θ ) 3 = f ( θ ) f(x_0 ,\theta) = (1-\theta)\times\theta\times\theta\times\theta\times\theta\times(1-\theta)\times\theta\times\theta\times\theta\times(1-\theta) = \theta ^ 7(1 - \theta)^3 = f(\theta) f(x0,θ)=(1−θ)×θ×θ×θ×θ×(1−θ)×θ×θ×θ×(1−θ)=θ7(1−θ)3=f(θ)
注意,这是个只关于
θ
\theta
θ的函数。而最大似然估计,顾名思义,就是要最大化这个函数。我们可以画出
f
(
θ
)
f(\theta)
f(θ)的图像:
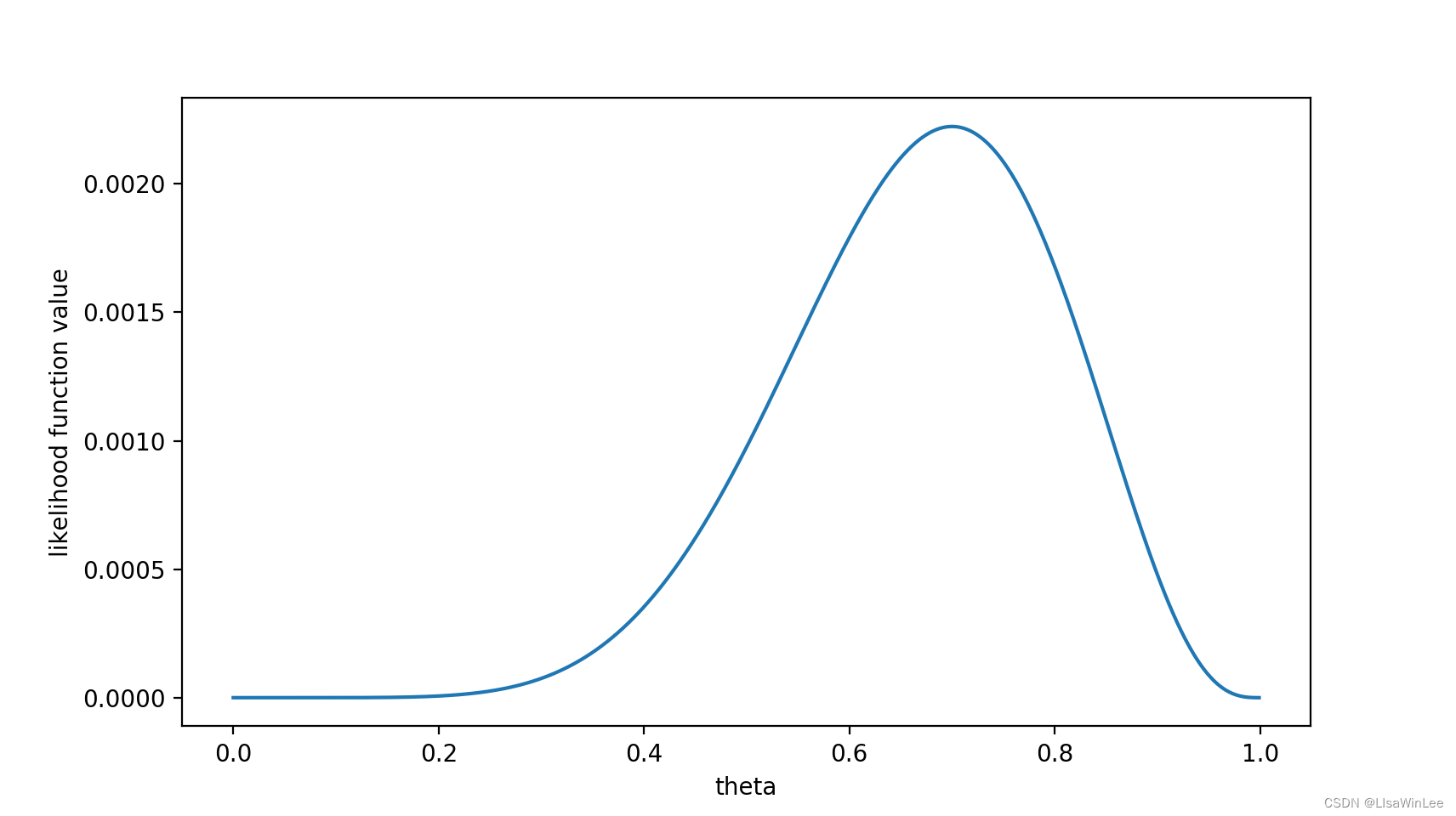
可以看出,在
θ
=
0.7
\theta = 0.7
θ=0.7时,似然函数取得最大值。
这样,我们已经完成了对 θ \theta θ的最大似然估计。即,抛10次硬币,发现7次硬币正面向上,最大似然估计认为正面向上的概率是0.7。(ummm…这非常直观合理,对吧?)
且慢,一些人可能会说,硬币一般都是均匀的啊! 就算你做实验发现结果是“反正正正正反正正正反”,我也不信 θ = 0.7 \theta = 0.7 θ=0.7。
这里就包含了贝叶斯学派的思想了——要考虑先验概率。 为此,引入了最大后验概率估计。
可见,极大似然估计的思想是没有考虑先验概率的啊!!!
最大后验概率估计
最大似然估计是单纯根据出现的事件求参数
θ
θ
θ,使似然函数
P
(
x
∣
θ
)
P(x|θ)
P(x∣θ) 最大。最大后验概率估计在最大似然估计的基础上,求得的
θ
θ
θ 不仅仅是让似然函数最大,也让
θ
θ
θ 自己出现的概率最大。我们可以换个角度来思考这个问题,对于不同的
θ
θ
θ 可以得到不同的似然函数的值,但是
θ
θ
θ 本身出现的概率可以用来对似然函数进行正则化,让似然函数更加合理,本身出现概率小的
θ
θ
θ 会引入惩罚,降低其似然函数的值。但是与损失函数中正则化项一般用加法不同,MAP 里利用乘法引入这个惩罚因子。
定义为:
P
(
θ
∣
x
)
=
P
(
x
∣
θ
)
P
(
θ
)
P
(
x
)
P(θ|x)=\frac{P(x|θ)P(θ)}{P(x)}
P(θ∣x)=P(x)P(x∣θ)P(θ)
因为
x
x
x 是确定的观察事件。因此
P
(
x
)
P(x)
P(x) 是已知值,所以可以去掉分母。
假设”投 10 次硬币“是一次实验,实验做了 1000 次,“反正正正正反正正正反”出现了 n 次,则P(x)=n/1000。总之,这是一个可以由实验观察数据集得到的值。
上述的公式是不是很像贝叶斯定理?最大后验概率的名字由来就是最大化 P ( θ ∣ x ) P(θ|x) P(θ∣x),这其实是一个后验概率。与似然函数 P ( x ∣ θ ) P(x|θ) P(x∣θ) 不同的也仅仅是乘以先验概率 P ( θ ) P(θ) P(θ)。
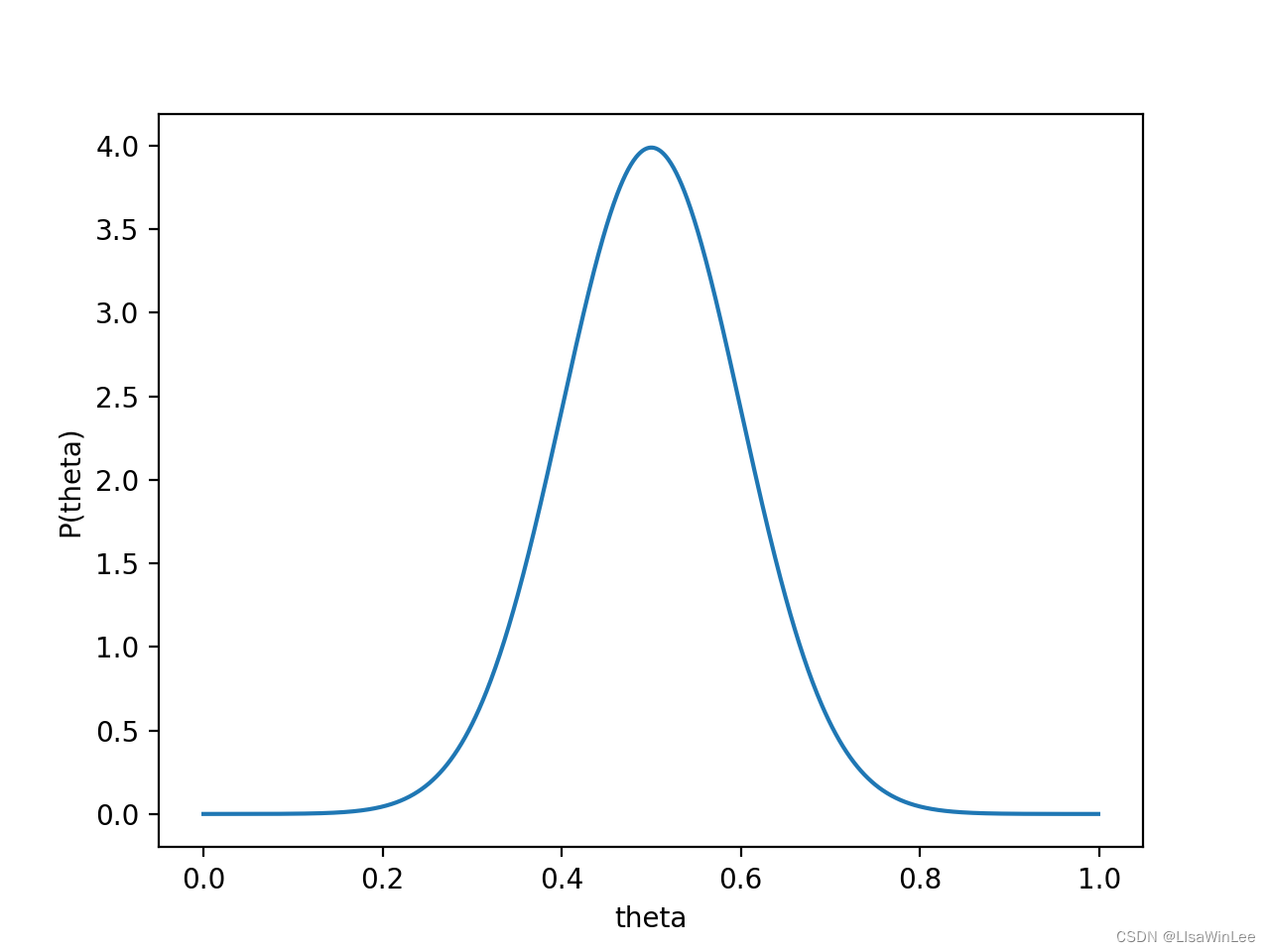
对于投硬币的例子来看,我们认为(”先验地知道“)
θ
\theta
θ取0.5的概率很大,取其他值的概率小一些。我们用一个高斯分布来具体描述我们掌握的这个先验知识,例如假设
P
(
θ
)
P(\theta)
P(θ)为均值0.5,方差0.1的高斯函数,如下图:
则
P
(
x
0
∣
θ
)
P
(
θ
)
P(x_0 | \theta) P(\theta)
P(x0∣θ)P(θ)的函数图像为:
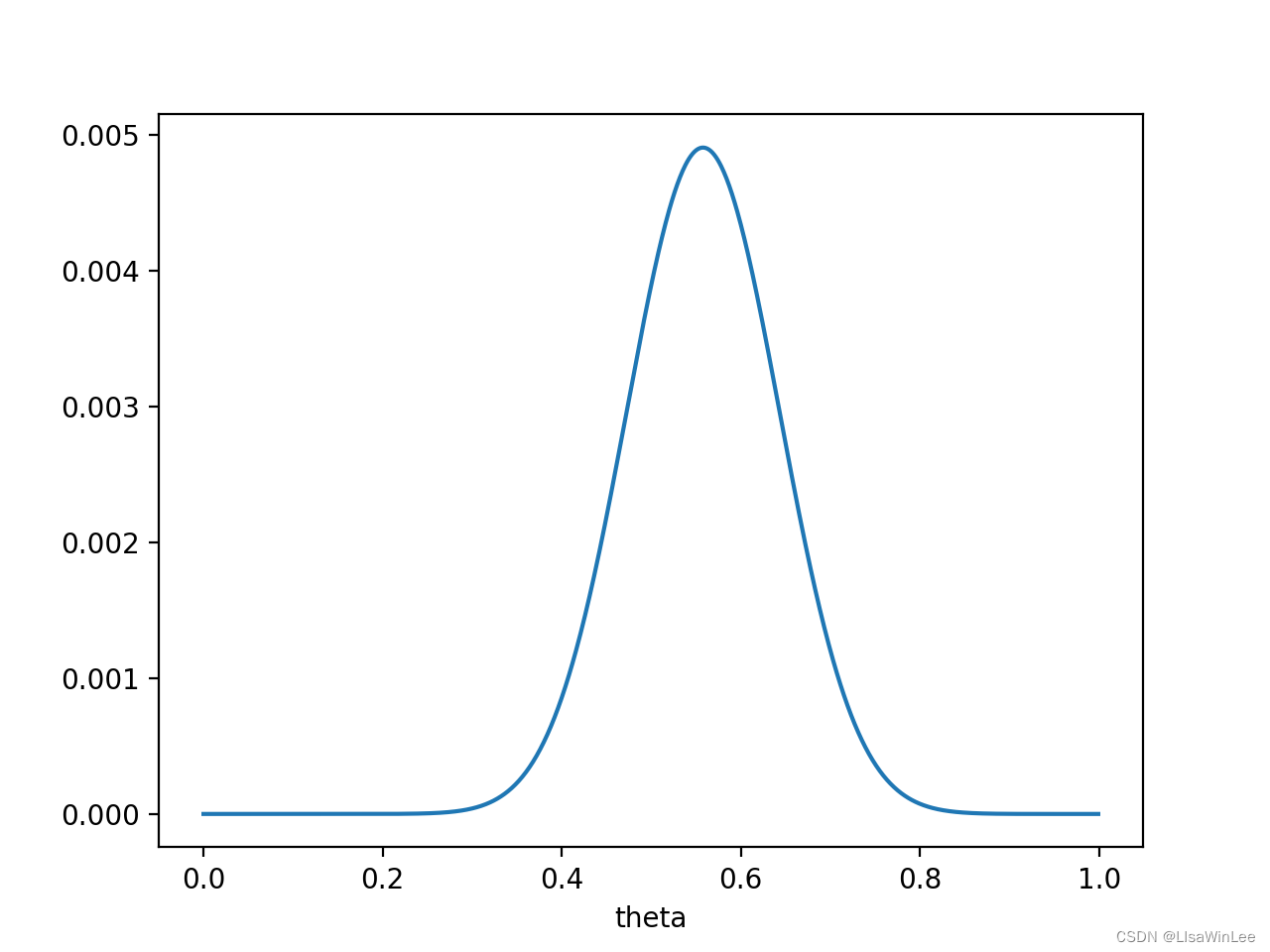
注意,此时函数取最大值时,
θ
\theta
θ取值已向左偏移,不再是0.7。实际上,在
θ
=
0.558
\theta = 0.558
θ=0.558时函数取得了最大值。即,用最大后验概率估计,得到
θ
=
0.558
\theta = 0.558
θ=0.558.
最后,那要怎样才能说服一个贝叶斯派相信
θ
=
0.7
\theta = 0.7
θ=0.7呢?你得多做点实验。。。
如果做了1000次实验,其中700次都是正面向上,这时似然函数为:
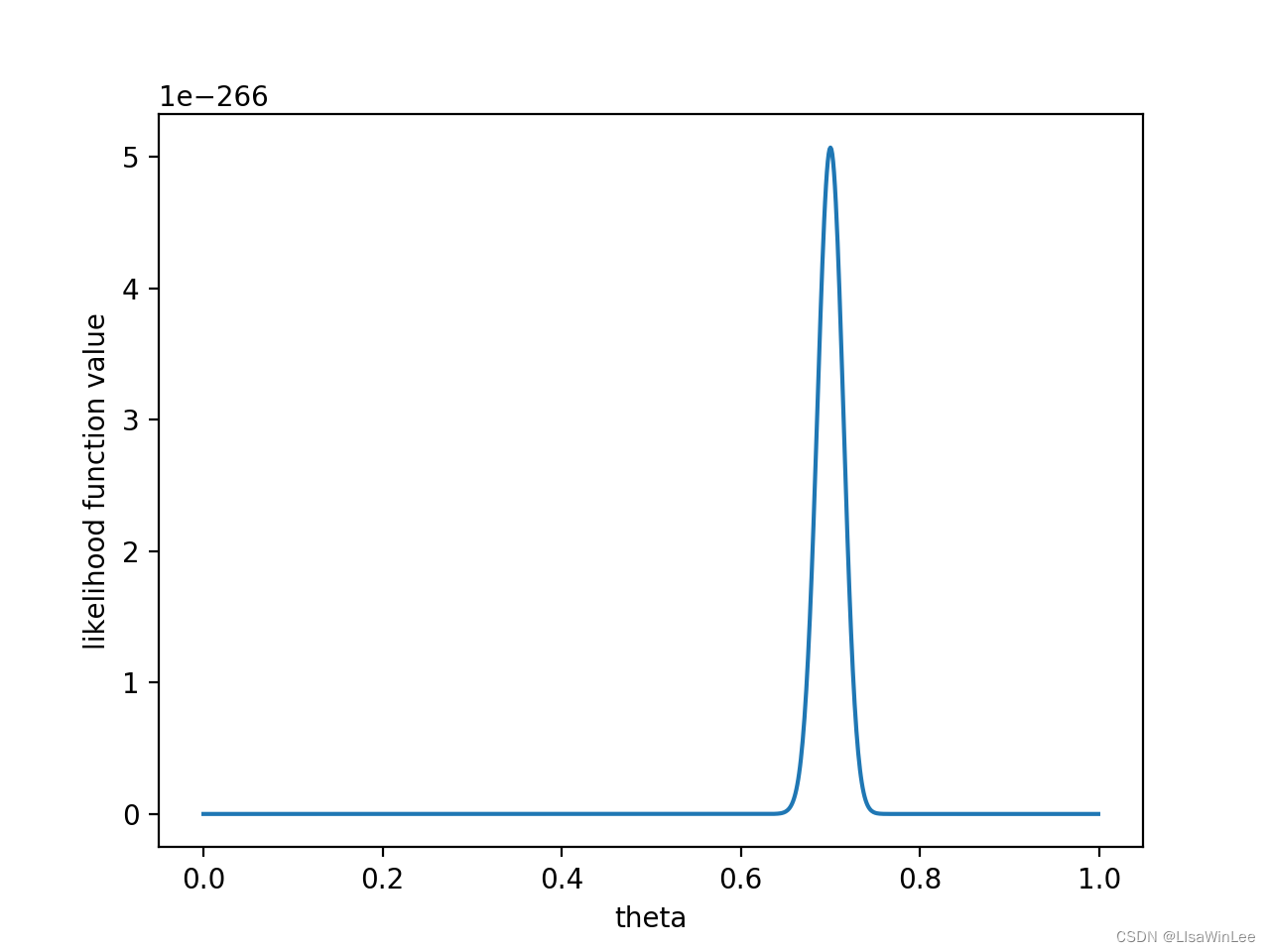
如果仍然假设
P
(
θ
)
P(\theta)
P(θ)为均值0.5,方差0.1的高斯函数,
P
(
x
0
∣
θ
)
P
(
θ
)
P(x_0 | \theta) P(\theta)
P(x0∣θ)P(θ)的函数图像为:
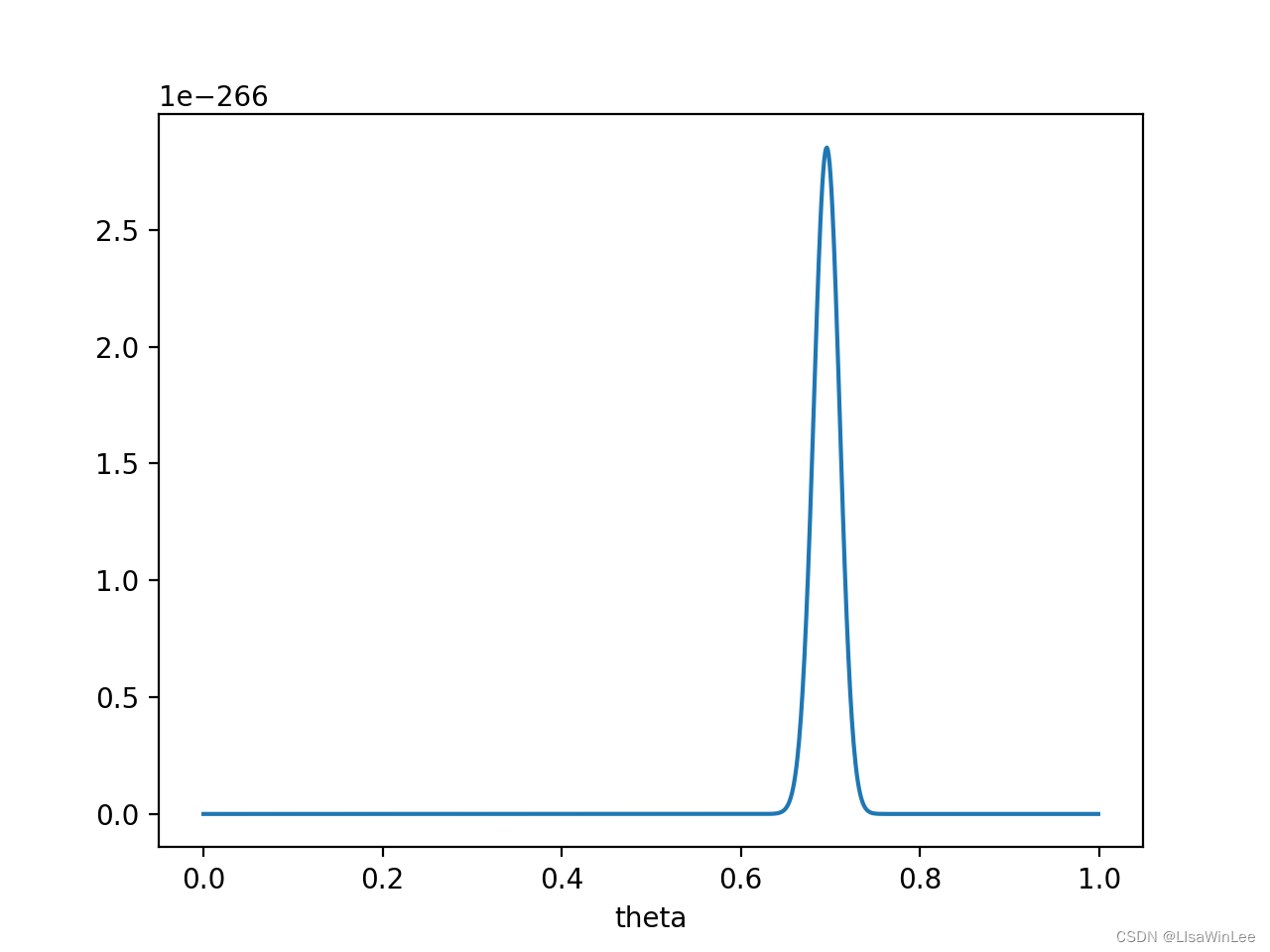
在
θ
=
0.696
\theta = 0.696
θ=0.696处,
P
(
x
0
∣
θ
)
P
(
θ
)
P(x_0 | \theta) P(\theta)
P(x0∣θ)P(θ)取得最大值。
这样,就算一个考虑了先验概率的贝叶斯派,也不得不承认得把 θ \theta θ估计在0.7附近了。
PS. 要是遇上了顽固的贝叶斯派,认为 P ( θ = 0.5 ) = 1 P(\theta = 0.5) = 1 P(θ=0.5)=1,那就没得玩了。。。 无论怎么做实验,使用MAP估计出来都是 θ = 0.5 \theta = 0.5 θ=0.5。这也说明,一个合理的先验概率假设是很重要的。(通常,先验概率能从数据中直接分析得到)
最大似然估计和最大后验概率估计的区别
相信读完上文,MLE和MAP的区别应该是很清楚的了。MAP就是多个作为因子的先验概率 P ( θ ) P(\theta) P(θ)。或者,也可以反过来,认为MLE是把先验概率 P ( θ ) P(\theta) P(θ)认为等于1,即认为 θ \theta θ是均匀分布。
参考资料
万分感谢各位前辈们总结的资料,下列在此,也欢迎各位补充!
https://blog.csdn.net/u011508640/article/details/72815981
https://murphypei.github.io/blog/2020/03/mle-map.html
https://zhuanlan.zhihu.com/p/93416473
https://zhuanlan.zhihu.com/p/72370235














 1215
1215











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









