







1、密度聚类及DBSCAN
密度聚类:密度聚类算法,即基于密度的聚类,此类算法假设聚类结构能通过样本分布的紧密程度确定。通常,密度聚类算法从样本密度的角度来考察样本之间的可连接性,并基于可连接样本不断拓展聚类簇以获得最终的聚类结果。
DBSCAN是典型的密度聚类算法,它基于一组“邻域”参数
(ϵ,MinPts)
来刻画样本分布的紧密程度。邻域参数有何用呢?它其实限定了聚类簇的规模大小至少为MinPts,若样本点
x
的
所以寻找聚类簇的一种朴素方法是:考虑核心对象
x
,由
2、Matlab程序
function [k,C] = DBSCAN(D)
%D = rand(2, 30); %样本集
eps = 0.11; %邻域参数
MinPts = 5; %领域参数
O = zeros(1, size(D, 2)); %核心对象集
C = cell(size(D,2));
d = zeros(size(D, 2), size(D, 2)); %样本之间的距离大于eps元素值为1,反之0
for i = 1:size(D, 2)
for j = size(D, 2):-1:i
if pdist(D(:, [i j])') <= eps
d(i, j) = 1;
end
d(j, i) = d(i, j);
end
%d(i,i) = 0;
if sum(d(i, :)) >= MinPts
O(i) = i;
end
end
k = 0; %初始化聚类簇数
Tau = 1:size(D, 2); %初始化未访问样本集合
while sum(O) ~= 0
Tau_old = Tau; %记录当前未访问样本集合
%随机选取一个核心对象j,找出其密度可达点
j = 1;
while O(j) == 0
j = j+1;
end
%ob = O(j);
Q = zeros(1, size(Tau, 2));
Q(j) = j; %将核心对象j加入队列Q
Tau(j) = 0; %将核心对象j移出Tau
while sum(Q) ~= 0
%取出Q中首个样本m
m = 1;
while Q(m) == 0
m = m+1;
end
Q(m) = 0;
if sum(d(m,:)) >= MinPts
for l = 1:size(d, 2)
if d(m, l) == 1 && Tau(l) ~= 0
Q(l) = l;
Tau(l) = 0;
end
end
end
end
k = k+1;
for i = 1:size(Tau, 2)
if Tau(i) ~= 0
Tau_old(i) = 0;
end
if Tau_old(i) ~= 0
O(i) =0;
end
end
C{k} = Tau_old;
end
for i = 1:k
C{i} = find(C{i}~=0);
C{i}
D1 = D(:,C{i});
scatter(D1(1,:),D1(2,:));
hold on
end运行结果:
当D为西瓜数据集4.0(见周志华老师的《机器学习》
P202
),聚类结果如下:
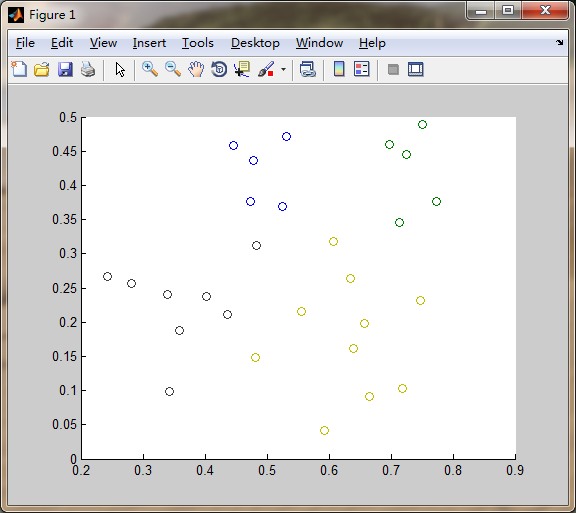
本文参考自周志华老师的《机器学习》.















 891
891

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









