









1、Mean Shift向量
Mean Shift向量:偏移的均值向量。定义如下:对于给定
d
维空间
直观上来看,这
k
个样本点在
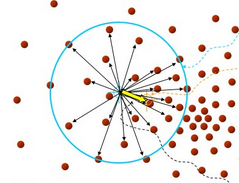
几何解释为:如果样本点 xi 服从一个概率密度函数为 f(x) 的分布,由于非零的概率密度函数的梯度指向概率密度增加最大的方向,因此从平均上来说, Sh 区域内的样本点更多的落在沿着概率密度梯度的方向。因此,Mean Shift向量 Mh(x) 应该指向概率密度梯度的方向。如图(图片来源)所示:
2、Mean Shift算法
Mean Shift算法:指一个迭代的步骤,即先算出当前点的偏移均值,移动该点到其偏移均值,然后以此为新的起始点,继续移动,直到满足一定的条件结束。
结合上图,算法实施过程为:原点是选定的初始迭代点,将蓝色圆(其半径记为h)内所有向量相加,相加的结果如黄色向量所示,其终点指向上图所示的红色点,则下一次迭代以该红色点为圆心,h为半径画圆,然后求这个圆内以圆心为起点所有向量的和。如此迭代下去,圆的中心点为收敛于一个固定的点,也就是概率密度最大的地方。所以 均值漂移算法本质上是一种基于梯度的优化算法。
上述过程即为最初的Mean Shift算法,只不过后来引入 核函数 泛化了该算法。先略过核函数的理论知识,探究OpenCV中meanShift函数的用法,其函数原型如下:
int meanShift(InputArray probImage, Rect& window, TermCriteria criteria)Parameters:
probImage : Back projection of the object histogram. See calcBackProject() for details.
window : Initial search window.
criteria : Stop criteria for the iterative search algorithm.
函数的参数反馈出其输入是反投影直方图,因此该函数总是同API函数calBackProject配合使用。
3、基于核方法的均值漂移算法
在上面Mean Shift向量的计算过程中我们并没有考虑距离因素,即只要两个采样点在均值向量方向上的投影相等,则它们对Mean Shift向量计算的贡献就一样。所以Mean Shift中引入kernel的初衷是:随着样本与被偏移点的距离不同,其偏移量对Mean Shift向量的贡献也不同。
一直以为Mean Shift涉及到的kernel就是平常DL中的kernel,但看到其定义我不确定还是不是我所认识的kernel了,直接贴wiki上的定义:
Let X be the n-dimensional Euclidean space
Rn , A function K: X→R is said to be a kernel if there exists a profile, k:[0,∞]→R , such that K(x)=k(∥x∥2) and
(1)k is non-negative.
(2)k is nonincreasing: k(a)≥k(b) if a<b .
(3)k is piecewise continuous and ∫∞0k(r)dr<∞
常用的两个kernel函数:
Flat kernel:
Gaussian kernel:
此外,在拓展Mean Shift算法的过程中,对每个样本点设定一个权重系数,使得不同的样本点对计算Mean Shift向量的重要性不一样。引入核函数和样本点加权的Mean Shift算法具有如下形式:
其中:
Gh(xi−x)=H−12G(H−12(xi−x)) , G(x) 是一个单位核函数,H是一个对称正定矩阵,称之为带宽矩阵。
w(xi)≥0 是采样点的权重系数。
实际应用中,带宽矩阵
H
常被限制为对角阵,特别地,最为常见的带宽矩阵为
特别地,当 w(xi)=1 , 核函数采用flat kernel时,上式退化为最开始的Mean Shift向量计算公式。
值得说明的是,Mean Shift在统计学中属于无参密度估计的范畴,事实证明Mean Shift向量 Mh(x) 是归一化了的概率密度梯度。这部分有时间再单独总结吧。
Mean Shift算法:
(1)计算 mh(x)=∑n1G(xi−xh)w(xi)xi∑n1G(xi−xh)w(xi) ;
(2)将 mh(x) 赋给 x ;
(3)若||mh(x)−x||≤ϵ 结束,否则返回(1).
虽然Mean Shift的理论知识大概总结完了,但还是觉得有点囫囵吞枣【汗】,为了加深理解,还是从OpenCV中扒meanshift API的源码吧。
#include "precomp.hpp"
/*F///
// Name: cvMeanShift
// Purpose: MeanShift algorithm
// Context:
// Parameters:
// imgProb - 2D object probability distribution
// windowIn - CvRect of CAMSHIFT Window intial size
// numIters - If CAMSHIFT iterates this many times, stop
// windowOut - Location, height and width of converged CAMSHIFT window
// len - If != NULL, return equivalent len
// width - If != NULL, return equivalent width
// Returns:
// Number of iterations CAMSHIFT took to converge
// Notes:
//F*/
CV_IMPL int
cvMeanShift( const void* imgProb, CvRect windowIn,
CvTermCriteria criteria, CvConnectedComp* comp )
{
//CvMoments用来计算矩形的重心,面积等形状特征
CvMoments moments;
int i = 0, eps;
CvMat stub, *mat = (CvMat*)imgProb;
CvMat cur_win;
CvRect cur_rect = windowIn;
//初始化跟踪窗口
if( comp )
comp->rect = windowIn;
//把0阶矩和1阶矩先初始化置零
moments.m00 = moments.m10 = moments.m01 = 0;
mat = cvGetMat( mat, &stub );
//图像颜色通道大于1时报错
if( CV_MAT_CN( mat->type ) > 1 )
CV_Error( CV_BadNumChannels, cvUnsupportedFormat );
//窗口尺寸小于0时报错
if( windowIn.height <= 0 || windowIn.width <= 0 )
CV_Error( CV_StsBadArg, "Input window has non-positive sizes" );
//使窗口尺寸位于图像内
windowIn = cv::Rect(windowIn) & cv::Rect(0, 0, mat->cols, mat->rows);
//迭代的标准,精度=1.0,迭代次数=100
criteria = cvCheckTermCriteria( criteria, 1., 100 );
eps = cvRound( criteria.epsilon * criteria.epsilon );
//最大循环次数=最大迭代次数criteria.max_iter=100
for( i = 0; i < criteria.max_iter; i++ )
{
int dx, dy, nx, ny;
double inv_m00;
cur_rect = cv::Rect(cur_rect) & cv::Rect(0, 0, mat->cols, mat->rows);
if( cv::Rect(cur_rect) == cv::Rect() )
{
cur_rect.x = mat->cols/2;
cur_rect.y = mat->rows/2;
}
cur_rect.width = MAX(cur_rect.width, 1);
cur_rect.height = MAX(cur_rect.height, 1);
cvGetSubRect( mat, &cur_win, cur_rect );
cvMoments( &cur_win, &moments );
/* Calculating center of mass */
if( fabs(moments.m00) < DBL_EPSILON )
break;
//搜索区域的质量m00
inv_m00 = moments.inv_sqrt_m00*moments.inv_sqrt_m00;
//搜索区域的水平重心偏移dx
dx = cvRound( moments.m10 * inv_m00 - windowIn.width*0.5 );
//搜索区域的垂直重心偏移dx
dy = cvRound( moments.m01 * inv_m00 - windowIn.height*0.5 );
//搜索区域的重心坐标(nx,ny)
nx = cur_rect.x + dx;
ny = cur_rect.y + dy;
//跟踪目标处于图像边缘时进行一些相应的处理
if( nx < 0 )
nx = 0;
else if( nx + cur_rect.width > mat->cols )
nx = mat->cols - cur_rect.width;
if( ny < 0 )
ny = 0;
else if( ny + cur_rect.height > mat->rows )
ny = mat->rows - cur_rect.height;
dx = nx - cur_rect.x;
dy = ny - cur_rect.y;
cur_rect.x = nx;
cur_rect.y = ny;
/* Check for coverage centers mass & window */
//精度达到要求时即可退出循环
if( dx*dx + dy*dy < eps )
break;
}
//对meanshift函数的返回值赋值
if( comp )
{
comp->rect = cur_rect;
comp->area = (float)moments.m00;
}
return i;
}
int cv::meanShift( InputArray _probImage, Rect& window, TermCriteria criteria )
{
CvConnectedComp comp;
Mat probImage = _probImage.getMat();
CvMat c_probImage = probImage;
int iters = cvMeanShift(&c_probImage, window, (CvTermCriteria)criteria, &comp );
window = comp.rect;
return iters;
}最后,在理解源码的过程中参考了一下这篇博客,发现博主关于Mean Shift算法的总结甚是明了,在此引用之:
基于均值漂移的目标跟踪算法通过分别计算目标区域和候选区域内像素的特征值概率得到关于目标模型和候选模型的描述,然后利用相似函数度量初始帧目标模型和当前帧的候选模版的相似性,选择使相似函数最大的候选模型并得到关于目标模型的Meanshift向量,这个向量正是目标由初始位置向正确位置移动的向量。由于均值漂移算法的快速收敛性,通过不断迭代计算Meanshift向量,算法最终将收敛到目标的真实位置,达到跟踪的目的。
MeanShift算法就总结到这里,Demo有时间在探究视觉跟踪的时候再整理吧。















 469
469

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









