







👉 点击关注不迷路
👉 点击关注不迷路
👉 点击关注不迷路
-
ultralytics-cfg-models-rtdetr 主要与
Ultralytics 库中 RTDETR(实时目标检测模型,Real-Time Detection with Efficient Transformers)模型相关,涉及到模型的配置、定义和相关功能实现 -
优点
- 高效的检测性能: RTDETR 在各种目标检测任务中表现出较高的准确性,能够精确地定位和识别多种不同类型的目标物体。它采用了先进的神经网络架构和算法,能够学习到丰富的图像特征。
- 实时性好: RTDETR 模型
适用于对实时性要求较高的场景,如视频监控、自动驾驶等,能够及时对视频流中的目标进行检测和响应。 - 灵活的模型配置: Ultralytics 库提供了灵活的配置选项,用户可以根据自己的需求和硬件条件,对 RTDETR 模型进行不同规模和复杂度的配置。例如,可以调整模型的层数、通道数等参数,以在检测精度和推理速度之间进行权衡,满足不同应用场景的需求。
- 易于使用和部署: Ultralytics 库提供了简洁易用的 API,使得用户能够方便地进行模型的训练、推理和评估。同时,RTDETR 模型可以方便地部署到多种不同的平台上,包括 CPU、GPU 以及一些嵌入式设备,具有较好的跨平台性和可移植性。
-
缺点
- 对小目标检测能力有限: 检测小目标局限性。小目标在图像中所占像素较少,特征不明显,容易被模型忽略或误判。这可能导致在
一些包含大量小目标的场景中,检测精度有所下降。 - 对复杂背景适应性不足:
当图像背景较为复杂,例如存在大量干扰物、遮挡或光线变化较大时,RTDETR 模型的性能可能会受到一定影响。复杂的背景可能会干扰模型对目标特征的提取,导致目标定位不准确或漏检。 - 训练数据要求较高: 为了充分发挥 RTDETR 模型的性能,
需要使用大量高质量的标注数据进行训练。如果训练数据的数量不足或质量不高,模型可能无法学习到足够的特征,从而影响检测效果。此外,收集和标注大量高质量的数据需要耗费大量的人力和时间成本。
- 对小目标检测能力有限: 检测小目标局限性。小目标在图像中所占像素较少,特征不明显,容易被模型忽略或误判。这可能导致在
-
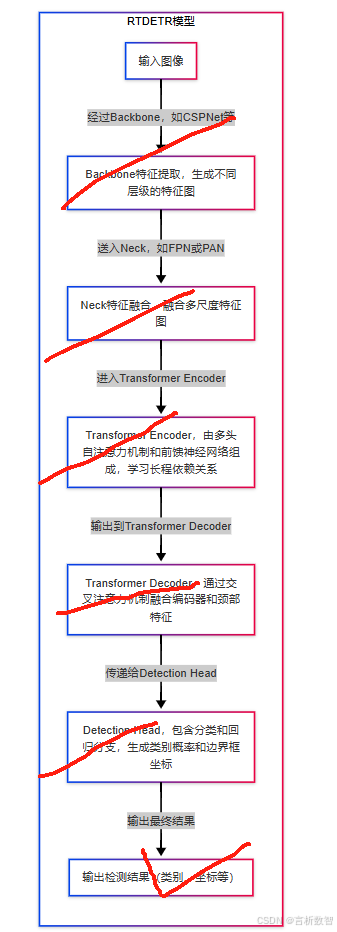
RTDETR模型的网络结构简要流程图
1. init.py
-
# 从当前包的 model 模块中导入 RTDETR 类 # RTDETR 类可能是实现 RTDETR(Real - Time Detection Transformer)模型的核心类, # 用于定义模型的结构、前向传播逻辑等,是整个目标检测模型的基础定义 from .model import RTDETR # 从当前包的 predict 模块中导入 RTDETRPredictor 类 # RTDETRPredictor 类负责使用训练好的 RTDETR 模型进行预测操作, # 它可能包含了对输入数据的预处理、调用模型进行推理以及对输出结果的后处理等功能, # 可以将其理解为一个用于执行预测任务的工具类 from .predict import RTDETRPredictor # 从当前包的 val 模块中导入 RTDETRValidator 类 # RTDETRValidator 类主要用于对 RTDETR 模型进行验证评估, # 它会在验证数据集上运行模型,计算各种评估指标(如 mAP 等), # 以评估模型的性能和泛化能力,帮助开发者了解模型的优劣 from .val import RTDETRValidator # __all__ 是一个特殊的列表,用于控制当使用 from <package> import * 语句时导入的对象 # 这里指定了三个对象,当使用上述导入语句时,会导入 RTDETRPredictor、RTDETRValidator 和 RTDETR 这三个对象 # 这种方式可以明确地控制模块的公共接口,避免不必要的对象被导入 __all__ = "RTDETRPredictor", "RTDETRValidator", "RTDETR"
2. model.py
-
# 从 ultralytics 库的 engine.model 模块导入 Model 类 # Model 类是 ultralytics 框架中模型的基类,提供了模型的基本功能和接口 from ultralytics.engine.model import Model # 从 ultralytics 库的 nn.tasks 模块导入 RTDETRDetectionModel 类 # RTDETRDetectionModel 类是用于目标检测任务的 RTDETR 模型的具体实现 from ultralytics.nn.tasks import RTDETRDetectionModel # 从当前包的 predict 模块导入 RTDETRPredictor 类 # RTDETRPredictor 类用于使用训练好的 RTDETR 模型进行预测操作 from .predict import RTDETRPredictor # 从当前包的 train 模块导入 RTDETRTrainer 类 # RTDETRTrainer 类用于对 RTDETR 模型进行训练 from .train import RTDETRTrainer # 从当前包的 val 模块导入 RTDETRValidator 类 # RTDETRValidator 类用于对 RTDETR 模型进行验证评估 from .val import RTDETRValidator # 定义 RTDETR 类,继承自 Model 类 class RTDETR(Model): def __init__(self, model: str = "rtdetr-l.pt") -> None: """ 初始化 RTDETR 模型。 参数: model (str): 模型文件的路径或名称,默认为 "rtdetr-l.pt" """ # 调用父类 Model 的构造函数,传入模型文件和任务类型 # 这里指定任务类型为 "detect",表示目标检测任务 super().__init__(model=model, task="detect") @property def task_map(self) -> dict: """ 获取任务映射字典,该字典将任务类型映射到相应的预测器、验证器、训练器和模型类。 返回: dict: 任务映射字典 """ return { "detect": { # 预测器类,用于进行预测操作 "predictor": RTDETRPredictor, # 验证器类,用于进行验证评估 "validator": RTDETRValidator, # 训练器类,用于进行模型训练 "trainer": RTDETRTrainer, # 模型类,用于定义 RTDETR 目标检测模型的结构 "model": RTDETRDetectionModel, } }
3. predict.py
LetterBox- 对图像进行填充和缩放操作,使图像符合模型输入的尺寸要求
# 导入 PyTorch 库,用于深度学习中的张量计算和模型操作 import torch # 从 ultralytics 库的 data.augment 模块导入 LetterBox 类 # LetterBox 类用于对图像进行填充和缩放操作,使图像符合模型输入的尺寸要求 from ultralytics.data.augment import LetterBox # 从 ultralytics 库的 engine.predictor 模块导入 BasePredictor 类 # BasePredictor 是预测器的基类,自定义的预测器类可以继承该类并实现特定的预测逻辑 from ultralytics.engine.predictor import BasePredictor # 从 ultralytics 库的 engine.results 模块导入 Results 类 # Results 类用于存储和管理预测结果 from ultralytics.engine.results import Results # 从 ultralytics 库的 utils 模块导入 ops 工具模块 # ops 模块包含了一些常用的操作函数,如坐标转换、张量处理等 from ultralytics.utils import ops # 定义 RTDETRPredictor 类,继承自 BasePredictor 类 class RTDETRPredictor(BasePredictor): def postprocess(self, preds, img, orig_imgs): """ 对模型的预测结果进行后处理,将预测结果转换为最终的检测结果。 参数: preds (list or torch.Tensor): 模型的预测结果,可能是一个列表或张量 img (torch.Tensor): 经过预处理后的输入图像张量 orig_imgs (list or torch.Tensor): 原始输入图像,可能是列表或张量 返回: list: 包含最终检测结果的列表,每个元素是一个 Results 对象 """ # 如果 preds 不是列表或元组类型,将其转换为包含该元素和 None 的列表 # 这是为了统一处理 PyTorch 推理和导出推理的不同输出格式 if not isinstance(preds, (list, tuple)): preds = [preds, None] # 获取预测结果张量最后一个维度的大小 nd = preds[0].shape[-1] # 将预测结果的最后一个维度拆分为两部分,前 4 个元素为边界框坐标,其余为类别分数 bboxes, scores = preds[0].split((4, nd - 4), dim=-1) # 如果原始图像不是列表类型,将其从 PyTorch 张量转换为 NumPy 数组的批量形式 if not isinstance(orig_imgs, list): orig_imgs = ops.convert_torch2numpy_batch(orig_imgs) # 初始化一个空列表,用于存储最终的检测结果 results = [] # 遍历每个预测结果、原始图像和图像路径 for bbox, score, orig_img, img_path in zip(bboxes, scores, orig_imgs, self.batch[0]): # 将边界框坐标从 [x, y, w, h] 格式转换为 [x1, y1, x2, y2] 格式 bbox = ops.xywh2xyxy(bbox) # 获取每个预测框的最大类别分数和对应的类别索引 max_score, cls = score.max(-1, keepdim=True) # 根据置信度阈值筛选出置信度高于阈值的预测框 idx = max_score.squeeze(-1) > self.args.conf # 如果指定了要检测的类别,则进一步筛选出属于指定类别的预测框 if self.args.classes is not None: idx = (cls == torch.tensor(self.args.classes, device=cls.device)).any(1) & idx # 根据筛选条件过滤出符合要求的预测框,将边界框坐标、最大类别分数和类别索引拼接在一起 pred = torch.cat([bbox, max_score, cls], dim=-1)[idx] # 获取原始图像的高度和宽度 oh, ow = orig_img.shape[:2] # 将预测框的坐标缩放回原始图像的尺寸 pred[..., [0, 2]] *= ow pred[..., [1, 3]] *= oh # 创建一个 Results 对象,包含原始图像、图像路径、类别名称和预测框信息 # 并将其添加到结果列表中 results.append(Results(orig_img, path=img_path, names=self.model.names, boxes=pred)) # 返回最终的检测结果列表 return results def pre_transform(self, im): """ 对输入图像进行预处理,主要是进行填充和缩放操作。 参数: im (list): 输入图像列表 返回: list: 经过预处理后的图像列表 """ # 创建一个 LetterBox 对象,指定图像尺寸、不自动调整和使用填充缩放方式 letterbox = LetterBox(self.imgsz, auto=False, scale_fill=True) # 对输入图像列表中的每个图像应用 LetterBox 变换 return [letterbox(image=x) for x in im]
4. train.py
- RANK 通常用于分布式训练中表示当前进程的编号,colorstr 用于给字符串添加颜色,方便日志输出
# 从 copy 模块导入 copy 函数,用于创建对象的浅拷贝 from copy import copy # 从 ultralytics 库的 models.yolo.detect 模块导入 DetectionTrainer 类 # DetectionTrainer 是用于目标检测模型训练的基类,提供了训练的基本流程和方法 from ultralytics.models.yolo.detect import DetectionTrainer # 从 ultralytics 库的 nn.tasks 模块导入 RTDETRDetectionModel 类 # RTDETRDetectionModel 是 RTDETR 目标检测模型的具体实现类 from ultralytics.nn.tasks import RTDETRDetectionModel # 从 ultralytics 库的 utils 模块导入 RANK 和 colorstr # RANK 通常用于分布式训练中表示当前进程的编号 # colorstr 用于给字符串添加颜色,方便日志输出 from ultralytics.utils import RANK, colorstr # 从当前包的 val 模块导入 RTDETRDataset 和 RTDETRValidator 类 # RTDETRDataset 用于构建 RTDETR 模型训练和验证所需的数据集 # RTDETRValidator 用于对 RTDETR 模型进行验证评估 from .val import RTDETRDataset, RTDETRValidator # 定义 RTDETRTrainer 类,继承自 DetectionTrainer 类 class RTDETRTrainer(DetectionTrainer): def get_model(self, cfg=None, weights=None, verbose=True): """ 获取用于训练的 RTDETR 模型。 参数: cfg: 模型配置文件,默认为 None weights: 预训练模型的权重文件路径,默认为 None verbose: 是否打印详细信息,默认为 True 返回: RTDETRDetectionModel: 初始化好的 RTDETR 模型 """ # 创建 RTDETRDetectionModel 实例 # cfg 是模型配置,nc 是类别数量,从数据配置中获取,ch 是输入通道数,同样从数据配置中获取 # verbose 控制是否打印详细信息,只有当 RANK 为 -1 时才打印(通常表示非分布式训练时) model = RTDETRDetectionModel(cfg, nc=self.data["nc"], ch=self.data["channels"], verbose=verbose and RANK == -1) # 如果提供了预训练权重文件路径,则加载权重 if weights: model.load(weights) # 返回初始化好的模型 return model def build_dataset(self, img_path, mode="val", batch=None): """ 构建用于训练或验证的数据集。 参数: img_path: 图像数据的路径 mode: 模式,可选值为 "train" 或 "val",默认为 "val" batch: 批量大小,默认为 None 返回: RTDETRDataset: 构建好的数据集 """ return RTDETRDataset( # 图像数据的路径 img_path=img_path, # 图像的尺寸,从参数配置中获取 imgsz=self.args.imgsz, # 批量大小 batch_size=batch, # 是否进行数据增强,当 mode 为 "train" 时进行增强 augment=mode == "train", # 超参数配置,从参数配置中获取 hyp=self.args, # 是否使用矩形训练,这里设置为 False rect=False, # 是否缓存数据,从参数配置中获取,默认为 None cache=self.args.cache or None, # 是否单类别训练,从参数配置中获取,默认为 False single_cls=self.args.single_cls or False, # 日志前缀,添加颜色,方便区分训练和验证模式 prefix=colorstr(f"{mode}: "), # 要检测的类别,从参数配置中获取 classes=self.args.classes, # 数据配置 data=self.data, # 数据使用比例,训练模式下从参数配置中获取,验证模式下为 1.0 fraction=self.args.fraction if mode == "train" else 1.0, ) def get_validator(self): """ 获取用于验证模型的验证器。 返回: RTDETRValidator: 初始化好的验证器 """ # 定义损失函数的名称,后续在日志中可能会用到 self.loss_names = "giou_loss", "cls_loss", "l1_loss" # 创建 RTDETRValidator 实例 # test_loader 是测试数据加载器,save_dir 是保存结果的目录,args 是参数配置的浅拷贝 return RTDETRValidator(self.test_loader, save_dir=self.save_dir, args=copy(self.args))
5. val.py
v8_transforms是一组预定义的数据增强变换# 导入 PyTorch 库,用于深度学习中的张量计算、模型构建和训练等操作 import torch # 从 ultralytics 库的 data 模块导入 YOLODataset 类 # YOLODataset 是用于处理 YOLO 系列模型数据集的基类 from ultralytics.data import YOLODataset # 从 ultralytics 库的 data.augment 模块导入 Compose、Format 和 v8_transforms # Compose 用于组合多个数据增强操作;Format 用于格式化数据;v8_transforms 是一组预定义的数据增强变换 from ultralytics.data.augment import Compose, Format, v8_transforms # 从 ultralytics 库的 models.yolo.detect 模块导入 DetectionValidator 类 # DetectionValidator 是用于目标检测模型验证的基类 from ultralytics.models.yolo.detect import DetectionValidator # 从 ultralytics 库的 utils 模块导入 colorstr 和 ops # colorstr 用于给字符串添加颜色,便于日志输出;ops 包含一些常用的操作函数,如坐标转换等 from ultralytics.utils import colorstr, ops # 定义 __all__ 变量,指定当使用 from module import * 语句时,要导入的对象 __all__ = ("RTDETRValidator",) # tuple or list # 定义 RTDETRDataset 类,继承自 YOLODataset 类 class RTDETRDataset(YOLODataset): def __init__(self, *args, data=None, **kwargs): """ 初始化 RTDETRDataset 类。 参数: *args: 可变位置参数,传递给父类的构造函数 data: 数据集相关的数据,默认为 None **kwargs: 可变关键字参数,传递给父类的构造函数 """ # 调用父类的构造函数进行初始化 super().__init__(*args, data=data, **kwargs) def load_image(self, i, rect_mode=False): """ 加载指定索引的图像。 参数: i: 图像的索引 rect_mode: 是否使用矩形模式加载图像,默认为 False 返回: 加载好的图像 """ # 调用父类的 load_image 方法加载图像 return super().load_image(i=i, rect_mode=rect_mode) def build_transforms(self, hyp=None): """ 构建数据增强变换。 参数: hyp: 超参数配置,默认为 None 返回: 组合好的数据增强变换 """ if self.augment: # 如果进行数据增强且不是矩形模式,设置 mosaic 和 mixup 的比例 hyp.mosaic = hyp.mosaic if self.augment and not self.rect else 0.0 hyp.mixup = hyp.mixup if self.augment and not self.rect else 0.0 # 使用 v8_transforms 构建数据增强变换,开启拉伸 transforms = v8_transforms(self, self.imgsz, hyp, stretch=True) else: # 如果不进行数据增强,使用空的组合变换 # transforms = Compose([LetterBox(new_shape=(self.imgsz, self.imgsz), auto=False, scale_fill=True)]) transforms = Compose([]) # 在变换列表末尾添加 Format 变换,用于格式化数据 transforms.append( Format( bbox_format="xywh", # 边界框格式为 xywh normalize=True, # 对图像进行归一化 return_mask=self.use_segments, # 是否返回掩码 return_keypoint=self.use_keypoints, # 是否返回关键点 batch_idx=True, # 是否返回批次索引 mask_ratio=hyp.mask_ratio, # 掩码比例 mask_overlap=hyp.overlap_mask # 掩码重叠度 ) ) return transforms # 定义 RTDETRValidator 类,继承自 DetectionValidator 类 class RTDETRValidator(DetectionValidator): def build_dataset(self, img_path, mode="val", batch=None): """ 构建用于验证的数据集。 参数: img_path: 图像数据的路径 mode: 模式,可选值为 "val"(验证),默认为 "val" batch: 批量大小,默认为 None 返回: RTDETRDataset 实例,即构建好的数据集 """ return RTDETRDataset( img_path=img_path, # 图像数据路径 imgsz=self.args.imgsz, # 图像尺寸 batch_size=batch, # 批量大小 augment=False, # 不进行数据增强 hyp=self.args, # 超参数配置 rect=False, # 不使用矩形模式 cache=self.args.cache or None, # 是否缓存数据 prefix=colorstr(f"{mode}: "), # 日志前缀,添加颜色 data=self.data # 数据集相关数据 ) def postprocess(self, preds): """ 对模型的预测结果进行后处理。 参数: preds: 模型的预测结果 返回: 后处理后的预测结果 """ if not isinstance(preds, (list, tuple)): # 如果预测结果不是列表或元组类型,将其转换为包含该元素和 None 的列表 # 以统一处理 PyTorch 推理和导出推理的不同输出格式 preds = [preds, None] # 获取预测结果的批次大小、数量和最后一个维度的大小 bs, _, nd = preds[0].shape # 将预测结果的最后一个维度拆分为边界框坐标和类别分数两部分 bboxes, scores = preds[0].split((4, nd - 4), dim=-1) # 将边界框坐标乘以图像尺寸 bboxes *= self.args.imgsz # 初始化输出列表,每个元素是一个全零张量,用于存储每个样本的预测结果 outputs = [torch.zeros((0, 6), device=bboxes.device)] * bs for i, bbox in enumerate(bboxes): # 将边界框坐标从 xywh 格式转换为 xyxy 格式 bbox = ops.xywh2xyxy(bbox) # 获取每个预测框的最大类别分数和对应的类别索引 score, cls = scores[i].max(-1) # 将边界框坐标、最大类别分数和类别索引拼接在一起 pred = torch.cat([bbox, score[..., None], cls[..., None]], dim=-1) # 按置信度降序排序,以便正确计算内部指标 pred = pred[score.argsort(descending=True)] # 筛选出置信度高于阈值的预测结果 outputs[i] = pred[score > self.args.conf] return outputs def _prepare_batch(self, si, batch): """ 准备一个批次的数据。 参数: si: 样本索引 batch: 批次数据 返回: 准备好的样本数据字典 """ # 根据样本索引筛选出当前样本的数据 idx = batch["batch_idx"] == si cls = batch["cls"][idx].squeeze(-1) # 类别标签 bbox = batch["bboxes"][idx] # 边界框坐标 ori_shape = batch["ori_shape"][si] # 原始图像形状 imgsz = batch["img"].shape[2:] # 图像尺寸 ratio_pad = batch["ratio_pad"][si] # 缩放和填充比例 if len(cls): # 如果有类别标签,将边界框坐标从 xywh 格式转换为 xyxy 格式 bbox = ops.xywh2xyxy(bbox) # 将边界框坐标转换到原始图像空间 bbox[..., [0, 2]] *= ori_shape[1] bbox[..., [1, 3]] *= ori_shape[0] return {"cls": cls, "bbox": bbox, "ori_shape": ori_shape, "imgsz": imgsz, "ratio_pad": ratio_pad} def _prepare_pred(self, pred, pbatch): """ 准备预测结果,将其转换到原始图像空间。 参数: pred: 预测结果 pbatch: 准备好的批次数据 返回: 转换到原始图像空间的预测结果 """ # 克隆预测结果,避免修改原始数据 predn = pred.clone() # 将预测结果的边界框坐标转换到原始图像空间 predn[..., [0, 2]] *= pbatch["ori_shape"][1] / self.args.imgsz predn[..., [1, 3]] *= pbatch["ori_shape"][0] / self.args.imgsz return predn.float()



















 182
182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











