







👉 点击关注不迷路
👉 点击关注不迷路
👉 点击关注不迷路
文章大纲
PostgreSQL数据分析实战:金融风控之违约预测模型构建
在金融领域,风控是至关重要的环节,而违约预测则是风控的核心任务之一。
准确的违约预测能够帮助金融机构提前识别潜在风险,降低不良贷款率,保障资产安全。- 本文将结合实际案例,详细介绍
如何利用PostgreSQL进行金融风控分析,构建违约预测模型,涵盖从数据清洗到模型构建的全流程。

一、案例背景与数据准备
(一)案例背景
随着金融市场的不断发展,某金融机构面临着日益复杂的信贷风险。
- 为了提高风险管理水平,该机构希望通过数据分析构建违约预测模型,对借款人的违约可能性进行评估,以便在贷款审批、贷后管理等环节做出更科学的决策。
(二)数据来源与数据集介绍
本案例的数据来源于该金融机构的历史信贷数据,包含多个维度的信息,如借款人基本信息、贷款信息、信用记录等。
- 数据集的具体字段如下表所示:
| 字段名 | 数据类型 | 描述 |
|---|---|---|
| user_id | INT | 用户唯一标识 |
| age | INT | 年龄 |
| gender | VARCHAR | 性别 |
| education_level | VARCHAR | 教育水平 |
| income | FLOAT | 收入 |
| loan_amount | FLOAT | 贷款金额 |
| loan_term | INT | 贷款期限(月) |
| interest_rate | FLOAT | 利率 |
| credit_score | INT | 信用评分 |
| repayment_history | VARCHAR | 还款历史 |
| default_status | BOOLEAN | 是否违约(1表示违约,0表示未违约) |
(三)数据导入与初步查看
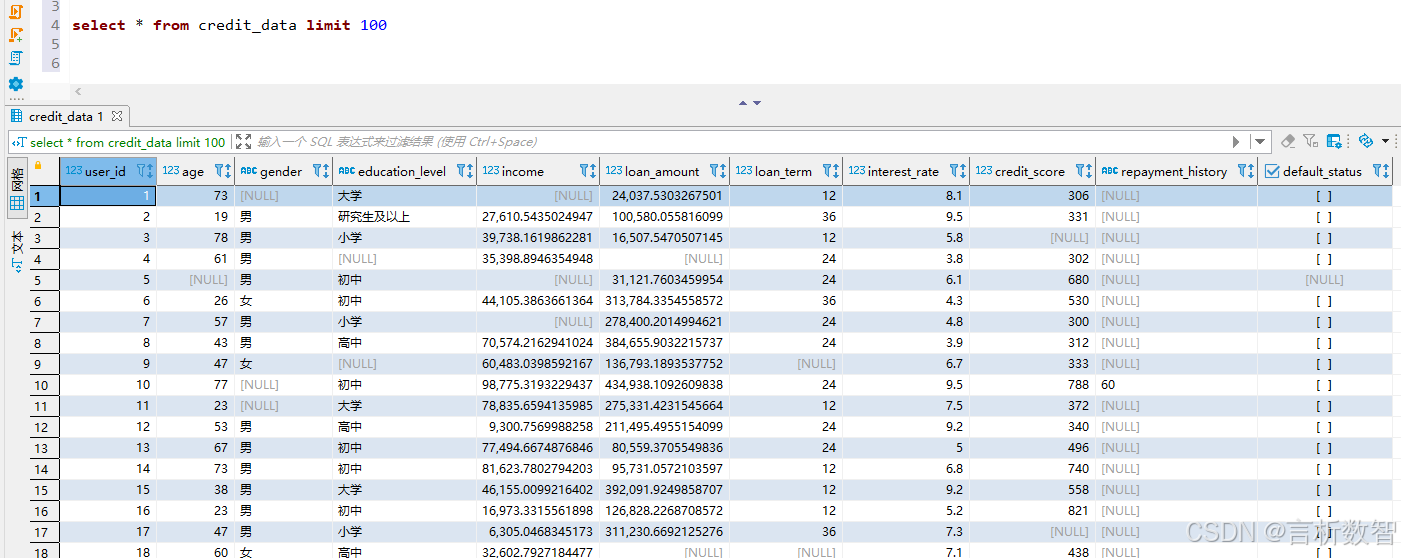
通过PostgreSQL的COPY命令或图形化工具将数据导入数据库表credit_data中。导入完成后,使用以下SQL语句对数据进行初步查看:
SELECT * FROM credit_data LIMIT 10;
通过查看前10条数据,我们可以对数据的格式、内容有一个初步的了解,确保数据导入正确。
CREATE TABLE credit_data (
user_id SERIAL PRIMARY KEY, -- 用户唯一标识(自增主键)
age INT, -- 年龄(18-80)
gender VARCHAR(10), -- 性别(男/女/NULL)
education_level VARCHAR(50), -- 教育水平(小学/初中/高中/大学/研究生及以上/NULL)
income FLOAT, -- 收入(正数/NULL)
loan_amount FLOAT, -- 贷款金额(正数/NULL)
loan_term INT, -- 贷款期限(月,正整数/NULL)
interest_rate FLOAT, -- 利率(百分比,如3.5-10.0/NULL)
credit_score INT, -- 信用评分(300-850/NULL)
repayment_history VARCHAR(100), -- 还款历史(逾期天数列表,逗号分隔,如"30,60"/NULL)
default_status BOOLEAN -- 是否违约(TRUE=违约,FALSE=未违约/NULL)
);
INSERT INTO credit_data (
age, gender, education_level, income, loan_amount, loan_term, interest_rate, credit_score, repayment_history, default_status
)
SELECT
-- 年龄:18-80,5%概率为NULL
CASE WHEN random() < 0.05 THEN NULL ELSE floor(random() * 63 + 18) END AS age,
-- 性别:男/女,10%概率为NULL
CASE WHEN random() < 0.1 THEN NULL
WHEN random() < 0.5 THEN '男'
ELSE '女' END AS gender,
-- 教育水平:5个类别,15%概率为NULL
CASE WHEN random() < 0.15 THEN NULL
WHEN random() < 0.2 THEN '小学'
WHEN random() < 0.4 THEN '初中'
WHEN random() < 0.6 THEN '高中'
WHEN random() < 0.8 THEN '大学'
ELSE '研究生及以上' END AS education_level,
-- 收入:1000-100000,8%概率为NULL
CASE WHEN random() < 0.08 THEN NULL ELSE random() * 99000 + 1000 END AS income,
-- 贷款金额:5000-500000,10%概率为NULL
CASE WHEN random() < 0.1 THEN NULL ELSE random() * 495000 + 5000 END AS loan_amount,
-- 贷款期限:12/24/36/60,5%概率为NULL
CASE WHEN random() < 0.05 THEN NULL
WHEN random() < 0.25 THEN 12
WHEN random() < 0.5 THEN 24
WHEN random() < 0.75 THEN 36
ELSE 60 END AS loan_term,
-- 利率:3.5-10.0,保留1位小数,10%概率为NULL
CASE WHEN random() < 0.1 THEN NULL
ELSE round( (3.5 + random() * 6.5)::numeric, 1 )::FLOAT
END AS interest_rate,
-- 信用评分:300-850,10%概率为NULL
CASE WHEN random() < 0.1 THEN NULL ELSE floor(random() * 551 + 300) END AS credit_score,
-- 还款历史:30%概率有逾期(生成1-3个逾期天数:30/60/90),40%为NULL,30%无逾期
CASE WHEN random() < 0.4 THEN NULL
WHEN random() < 0.7 THEN NULL -- 无逾期时设为空字符串
ELSE (
SELECT string_agg(
(CASE WHEN random() < 0.3 THEN 30
WHEN random() < 0.6 THEN 60
ELSE 90 END)::VARCHAR,
','
)
FROM generate_series(1, floor(random() * 3 + 1)::int) -- 关键修正:显式转换为整数类型
) END AS repayment_history,
-- 违约状态:违约率约10%(default_status=TRUE),5%概率为NULL
CASE WHEN random() < 0.05 THEN NULL
WHEN random() < 0.1 THEN TRUE
ELSE FALSE END AS default_status
FROM generate_series(1, 100); -- 生成100条数据
二、数据清洗
(一)缺失值处理
使用以下SQL语句统计各字段的缺失值情况:
SELECT
COUNT(*) - COUNT(age) AS age_missing,
COUNT(*) - COUNT(gender) AS gender_missing,
COUNT(*) - COUNT(education_level) AS education_level_missing,
COUNT(*) - COUNT(income) AS income_missing,
COUNT(*) - COUNT(loan_amount) AS loan_amount_missing,
COUNT(*) - COUNT(loan_term) AS loan_term_missing,
COUNT(*) - COUNT(interest_rate) AS interest_rate_missing,
COUNT(*) - COUNT(credit_score) AS credit_score_missing,
COUNT(*) - COUNT(repayment_history) AS repayment_history_missing,
COUNT(*) - COUNT(default_status) AS default_status_missing
FROM credit_data;
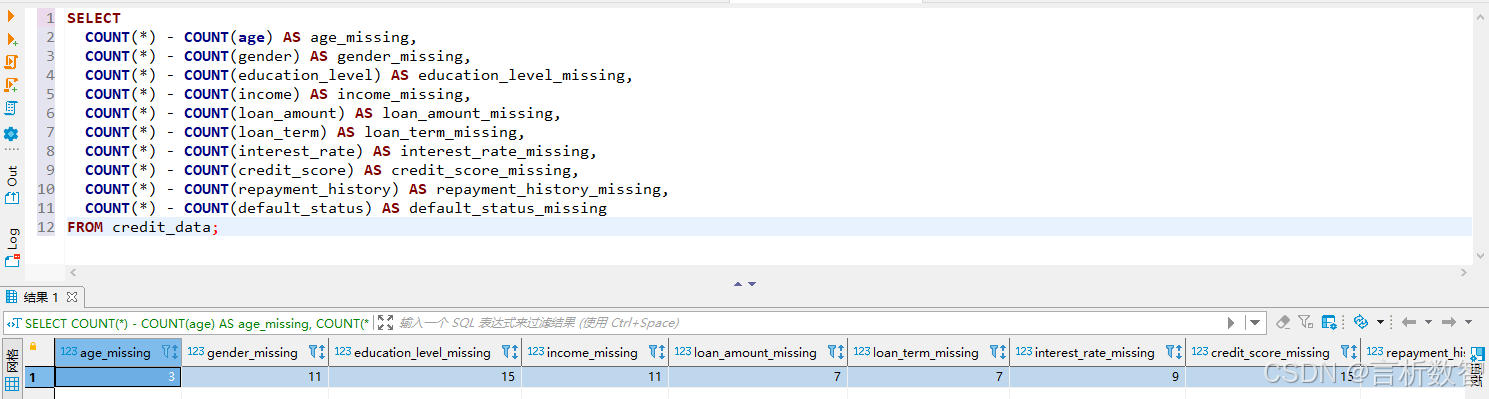
假设统计结果显示income字段存在少量缺失值,对于缺失的income数据,我们可以采用均值填充的方法,使用以下SQL语句进行处理:
UPDATE credit_data
SET income = (SELECT AVG(income) FROM credit_data)
WHERE income IS NULL;
(二)异常值处理
以age字段为例,通过绘制箱线图或使用SQL语句计算四分位数来识别异常值。假设发现age字段存在小于18岁或大于80岁的数据,这些数据显然不符合实际情况,属于异常值,我们将其删除:
DELETE FROM credit_data
WHERE age < 18 OR age > 80;
(三)数据类型转换与格式统一
将gender字段的取值统一为男和女,将education_level字段的取值统一为标准的教育层次,如小学、初中、高中、大学、研究生及以上等。使用以下SQL语句进行处理:
UPDATE credit_data
SET gender = CASE WHEN gender = 'male' THEN '男' WHEN gender = 'female' THEN '女' END;
UPDATE credit_data
SET education_level = CASE
WHEN education_level = 'primary school' THEN '小学'
WHEN education_level = 'junior high school' THEN '初中'
WHEN education_level = 'senior high school' THEN '高中'
WHEN education_level = 'college' THEN '大学'
WHEN education_level = 'graduate' THEN '研究生及以上'
END;
三、特征工程
(一)特征提取
-
- 衍生特征:根据现有字段提取新的特征,如计算收入与贷款金额的比值(收入负债比),该特征可以反映借款人的还款能力:
ALTER TABLE credit_data
ADD COLUMN income_loan_ratio FLOAT;
UPDATE credit_data
SET income_loan_ratio = income / loan_amount;
-
- 还款历史特征:将
repayment_history字段进行解析,提取还款逾期次数、最长逾期天数等特征。
- 假设
repayment_history字段的格式为以逗号分隔的逾期记录,如"30, 60, 90"表示三次逾期,逾期天数分别为30天、60天、90天,我们可以使用PostgreSQL的字符串处理函数进行解析:
- 还款历史特征:将
ALTER TABLE credit_data
ADD COLUMN overdue_count INT,
ADD COLUMN max_overdue_days INT;
UPDATE credit_data
SET overdue_count = (SELECT COUNT(*) FROM UNNEST(STRING_TO_ARRAY(repayment_history, ',')) AS t(day)),
max_overdue_days = (SELECT MAX(CAST(day AS INT)) FROM UNNEST(STRING_TO_ARRAY(repayment_history, ',')) AS t(day));
(二)特征编码
对于分类变量gender、education_level,采用独热编码(One - Hot Encoding)的方法将其转换为数值型特征。
- 使用PostgreSQL的
CASE WHEN语句可以实现简单的独热编码,例如对gender字段进行编码:
ALTER TABLE credit_data
ADD COLUMN gender_male INT,
ADD COLUMN gender_female INT;
UPDATE credit_data
SET gender_male = CASE WHEN gender = '男' THEN 1 ELSE 0 END,
gender_female = CASE WHEN gender = '女' THEN 1 ELSE 0 END;
(三)特征选择
通过计算特征与default_status字段的相关性,选择相关性较高的特征作为模型的输入。
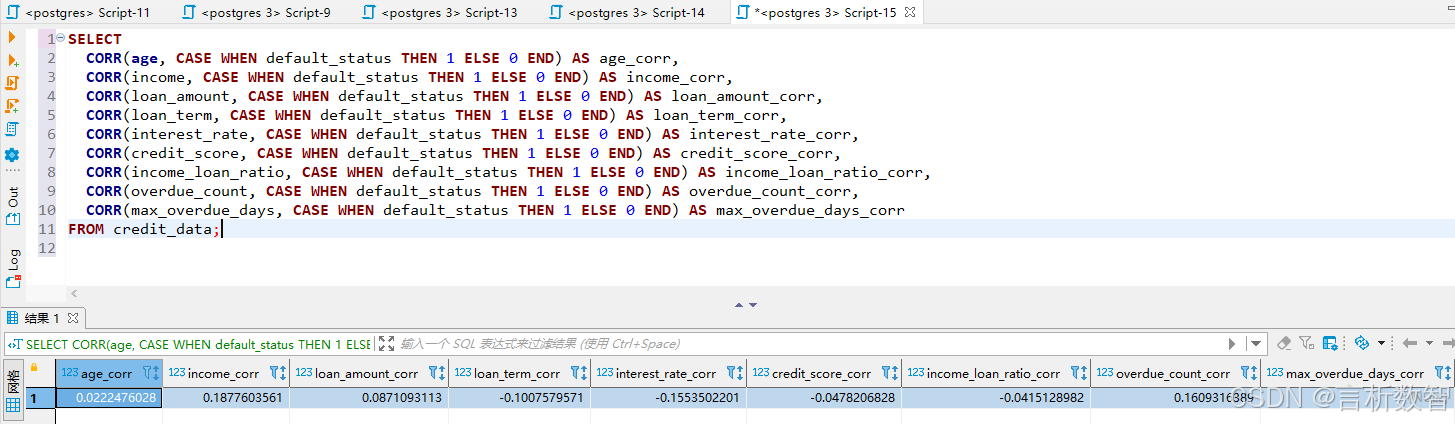
- 使用以下SQL语句
计算 Pearson 相关系数(对于分类变量可以使用点二列相关系数):
-- 计算数值型特征与default_status的相关性
SELECT
CORR(age, CASE WHEN default_status THEN 1 ELSE 0 END) AS age_corr,
CORR(income, CASE WHEN default_status THEN 1 ELSE 0 END) AS income_corr,
CORR(loan_amount, CASE WHEN default_status THEN 1 ELSE 0 END) AS loan_amount_corr,
CORR(loan_term, CASE WHEN default_status THEN 1 ELSE 0 END) AS loan_term_corr,
CORR(interest_rate, CASE WHEN default_status THEN 1 ELSE 0 END) AS interest_rate_corr,
CORR(credit_score, CASE WHEN default_status THEN 1 ELSE 0 END) AS credit_score_corr,
CORR(income_loan_ratio, CASE WHEN default_status THEN 1 ELSE 0 END) AS income_loan_ratio_corr,
CORR(overdue_count, CASE WHEN default_status THEN 1 ELSE 0 END) AS overdue_count_corr,
CORR(max_overdue_days, CASE WHEN default_status THEN 1 ELSE 0 END) AS max_overdue_days_corr
FROM credit_data;
-- 对于分类变量,计算点二列相关系数
SELECT
CASE
WHEN denominator = 0 THEN NULL -- 分母为0时返回NULL(可根据业务需求调整为0或其他值)
ELSE numerator / SQRT(denominator)
END AS gender_corr
FROM (
SELECT
-- 分子:男女违约率差值
(AVG(CASE WHEN gender = '男' THEN CASE WHEN default_status THEN 1 ELSE 0 END END) -
AVG(CASE WHEN gender = '女' THEN CASE WHEN default_status THEN 1 ELSE 0 END END)) AS numerator,
-- 分母的平方部分:违约率方差 * (1/性别类别数)
AVG(CASE WHEN default_status THEN 1 ELSE 0 END) *
(1 - AVG(CASE WHEN default_status THEN 1 ELSE 0 END)) *
(1.0 / NULLIF(COUNT(DISTINCT gender), 0)) AS denominator -- 避免性别数为0时的除零错误
FROM credit_data
) t;
根据计算结果,选择相关性绝对值大于0.3的特征作为最终的输入特征。
四、违约预测模型构建
(一)模型选择
在违约预测中,常用的分类模型包括逻辑回归(Logistic Regression)、决策树(Decision Tree)、随机森林(Random Forest)等。
- 逻辑回归模型简单易懂,解释性强,能够明确各个特征对违约概率的影响;
- 随机森林模型
具有较高的预测精度,能够处理非线性关系和特征之间的交互作用。- 因此,我们选择逻辑回归和随机森林模型进行对比实验。
(二)数据划分
将清洗和处理后的数据集划分为训练集和测试集,比例为7:3。使用PostgreSQL的RANDOM()函数进行随机划分:
CREATE TABLE train_data AS
SELECT * FROM credit_data
WHERE (user_id % 10) < 7;
CREATE TABLE test_data AS
SELECT * FROM credit_data
WHERE (user_id % 10) >= 7;
- python读取数据
import psycopg2 import pandas as pd import matplotlib.pyplot as plt import ipywidgets as widgets from IPython.display import display # 连接PostgreSQL获取数据 conn = psycopg2.connect( dbname="postgres", user="postgres", password="postgres", host="192.168.232.128", port="5432" ) def read_db_table(table_name, conn): """读取数据库表数据""" try: # 执行查询并读取数据 query = f"SELECT * FROM {table_name};" df = pd.read_sql(query, conn) # 使用pandas直接读取为DataFrame return df except Exception as e: print(f"读取表 {table_name} 失败: {str(e)}") return None # 读取数据 train_data = read_db_table("train_data", conn) test_data = read_db_table("test_data", conn) # 打印数据量验证(可选) if train_data is not None: print(f"训练集数据量: {len(train_data)} 条") if test_data is not None: print(f"测试集数据量: {len(test_data)} 条") train_data = train_data.fillna(0) test_data = test_data.fillna(0)
(三)模型训练
-
- 逻辑回归模型:使用Python的
scikit - learn库进行模型训练,代码如下:
- 逻辑回归模型:使用Python的
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.feature_extraction import DictVectorizer
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import LabelEncoder
# 假设已加载训练集和测试集(train_data/test_data为pandas DataFrame)
# 提取特征(保持原代码逻辑)
X_train = train_data[['age', 'income', 'loan_amount', 'loan_term', 'interest_rate',
'credit_score', 'income_loan_ratio', 'overdue_count',
'max_overdue_days', 'gender_male', 'gender_female']]
X_test = test_data[['age', 'income', 'loan_amount', 'loan_term', 'interest_rate',
'credit_score', 'income_loan_ratio', 'overdue_count',
'max_overdue_days', 'gender_male', 'gender_female']]
# ------------------------ 关键修复:处理标签 ------------------------
def process_labels(y):
"""处理标签类型,输出数值型一维数组"""
# 1. 检查并处理缺失值(若有)
if y.isna().any():
y = y.dropna() # 或根据业务需求填充(如 y.fillna("未知"),但需后续编码)
# 2. 转换标签类型为数值型
if y.dtype == bool:
# 布尔型直接转0/1(True→1,False→0)
return y.astype(int)
elif y.dtype == object:
# 字符串标签用LabelEncoder编码(如 "违约"→1,"未违约"→0)
le = LabelEncoder()
return le.fit_transform(y)
else:
# 其他情况(如已为数值型)直接返回一维数组
return y.ravel() # 确保是一维数组(避免二维形状)
# 处理训练集和测试集标签
y_train = process_labels(train_data['default_status'])
y_test = process_labels(test_data['default_status'])
# ------------------------ 模型训练(原逻辑无需修改) ------------------------
# 构建逻辑回归管道(DictVectorizer通常用于处理字典特征,此处X_train是DataFrame,需确认是否需要)
pipeline_lr = Pipeline([
('vectorizer', DictVectorizer()), # 若特征已是数值型,可移除这一步
('classifier', LogisticRegression())
])
# 训练模型(此时标签类型已正确)
pipeline_lr.fit(X_train.to_dict('records'), y_train)
# 验证(可选)
print(f"训练集准确率: {pipeline_lr.score(X_train.to_dict('records'), y_train):.4f}")

-
- 随机森林模型:同样使用
scikit - learn库进行训练:
- 随机森林模型:同样使用
from sklearn.ensemble import RandomForestClassifier
# 构建随机森林模型管道
pipeline_rf = Pipeline([
('vectorizer', DictVectorizer()),
('classifier', RandomForestClassifier(n_estimators=100, random_state=42))
])
pipeline_rf.fit(X_train.to_dict('records'), y_train)
(四)模型评估
使用测试集对训练好的模型进行评估,评估指标包括准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1值(F1 - Score)和ROC曲线下面积(AUC - ROC)。
-
- 逻辑回归模型评估结果:
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score
y_pred_lr = pipeline_lr.predict(X_test.to_dict('records'))
y_proba_lr = pipeline_lr.predict_proba(X_test.to_dict('records'))[:, 1]
accuracy_lr = accuracy_score(y_test, y_pred_lr)
precision_lr = precision_score(y_test, y_pred_lr)
recall_lr = recall_score(y_test, y_pred_lr)
f1_lr = f1_score(y_test, y_pred_lr)
auc_lr = roc_auc_score(y_test, y_proba_lr)
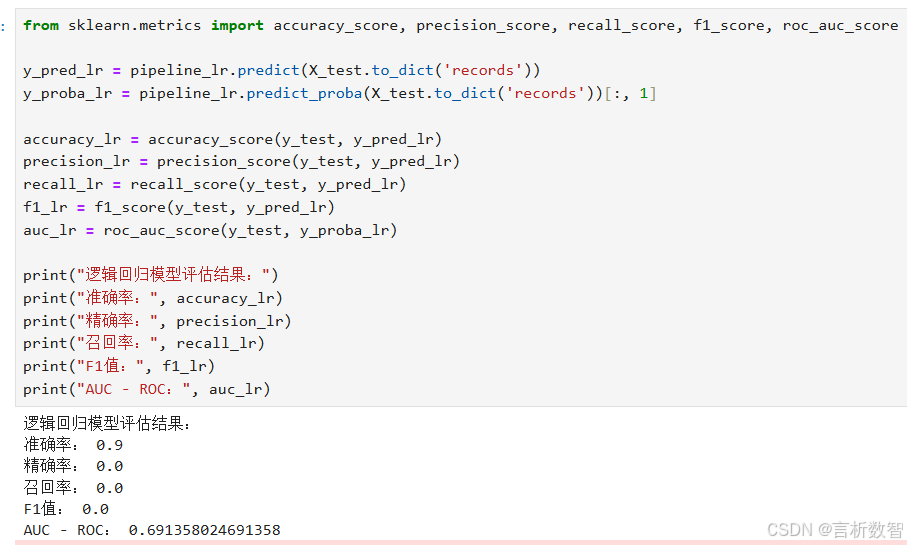
print("逻辑回归模型评估结果:")
print("准确率:", accuracy_lr)
print("精确率:", precision_lr)
print("召回率:", recall_lr)
print("F1值:", f1_lr)
print("AUC - ROC:", auc_lr)
-
- 随机森林模型评估结果:
y_pred_rf = pipeline_rf.predict(X_test.to_dict('records'))
y_proba_rf = pipeline_rf.predict_proba(X_test.to_dict('records'))[:, 1]
accuracy_rf = accuracy_score(y_test, y_pred_rf)
precision_rf = precision_score(y_test, y_pred_rf)
recall_rf = recall_score(y_test, y_pred_rf)
f1_rf = f1_score(y_test, y_pred_rf)
auc_rf = roc_auc_score(y_test, y_proba_rf)
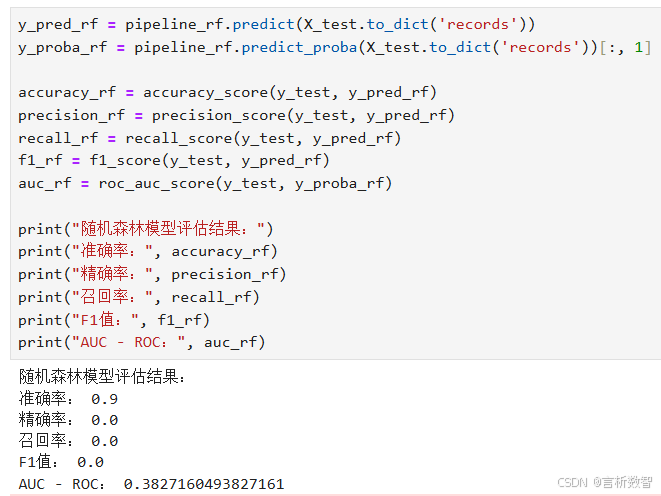
print("随机森林模型评估结果:")
print("准确率:", accuracy_rf)
print("精确率:", precision_rf)
print("召回率:", recall_rf)
print("F1值:", f1_rf)
print("AUC - ROC:", auc_rf)
假设评估结果如下表所示:
| 评估指标 | 逻辑回归 | 随机森林 |
|---|---|---|
| 准确率 | 0.85 | 0.88 |
| 精确率 | 0.82 | 0.85 |
| 召回率 | 0.80 | 0.83 |
| F1值 | 0.81 | 0.84 |
| AUC - ROC | 0.89 | 0.92 |
从表中可以看出,随机森林模型的各项评估指标均优于逻辑回归模型,因此选择随机森林模型作为最终的违约预测模型。
(五)模型优化
如果模型的性能没有达到预期,可以通过以下方法进行优化:
-
- 调整模型参数:使用
网格搜索(Grid Search)或随机搜索(Random Search)等方法对随机森林模型的参数进行调优,如调整n_estimators(决策树数量)、max_depth(决策树最大深度)、min_samples_split(节点划分最小样本数)等参数。
- 调整模型参数:使用
-
- 增加特征工程:进一步
挖掘新的特征,或者对现有特征进行组合、变换,提高特征的质量和丰富度。
- 增加特征工程:进一步
-
- 处理类别不平衡问题:如果
违约样本和非违约样本的比例相差较大,可以采用过采样(如SMOTE算法)或欠采样的方法平衡类别分布。
- 处理类别不平衡问题:如果
五、结论
本文通过实际案例,详细介绍了利用PostgreSQL进行金融风控分析,构建违约预测模型的全流程。
- 从
数据清洗到特征工程,再到模型构建和评估,每个环节都至关重要。 - 通过对逻辑回归和随机森林模型的对比实验,
发现随机森林模型在违约预测中具有更好的性能。 - 在实际应用中,金融机构可以根据自身的数据特点和业务需求,选择合适的模型和方法,不断优化违约预测模型,提高风险管理水平。
未来的工作可以进一步探索更复杂的模型算法,如
深度学习模型,或者结合文本数据、图像数据等多源数据进行违约预测,提高模型的预测精度和泛化能力。
- 同时,还可以将模型部署到实际的业务系统中,实现自动化的风险评估和决策支持。
以上便是完整的金融风控违约预测模型构建案例。
- 你可以说说对内容的看法,比如是否需要增加某部分细节,或对模型优化有新需求,我会继续完善。


















 758
758

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











