







在Flink流式程序设计中,经常需要与外部系统进行交互,很多时候外部系统的性能会成为任务整体吞吐的瓶颈,通常的解决方案会通过提高任务并发度增加对外部系统并发访问,如此会带来Flink额外的资源管理负载以及整体cpu利用率不高的问题。
对于Flink与外部存储交互的场景,可以通过Flink 异步IO和单并发度多线程的机制提高任务吞吐能力,而不需要提高任务并发度从而提升整体资源利用率。
一、 Flink异步IO
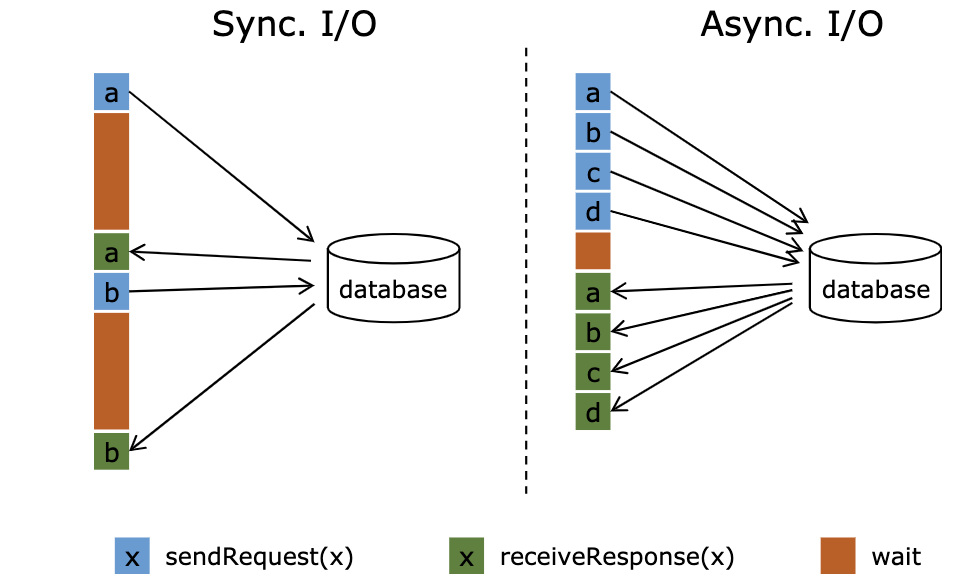
对于Flink程序,通常的交互实现为同步请求,即发送一个请求,直到收到响应,继续处理,很多情况下这种等待占据了函数的绝大多数时间,当外部系统出现性能瓶颈会大幅降低任务的吞吐能力。Flink提供了异步IO机制,可以实现发送请求以后,不用等待结果返回继续发送下一个请求,对于查询结果是异步返回的,返回结果之后会自动进入下一个算子的计算,从而避免外部系统性能对整个计算任务的影响,可以提高整体吞吐和资源利用率。
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.AsyncDataStream;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011;
import java.util.Properties;
import java.util.concurrent.TimeUnit;
public class AsynFlinkMysql {
public static void main(String args[]) throws Exception{
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties props = new Properties();
props.setProperty("bootstrap.servers", "10.xxxx:9092");
props.setProperty("zookeeper.connect", "10.xxxx:2181/kafka_test_1.0_for_upgrade");
props.setProperty("group.id", "flink-kafka");
env.setParallelism(1);
FlinkKafkaConsumer011 consumer = new FlinkKafkaConsumer011("hdp_teu_dpd_test_kafka", new SimpleStringSchema(), props);
DataStream<String> stream = env.addSource(consumer).map(new MapFunction<String,String>() {
@Override
public String map(String o) throws Exception {
System.out.println("input---"+o);
return o;
}
});
DataStream<String> resultStream = null;
if (true) {
//不保证返回顺序与请求顺序一致
resultStream = AsyncDataStream.unorderedWait(stream,
new AsyncMysql(),
300,
TimeUnit.SECONDS,
1000).setParallelism(1);
}
else {
//保证返回顺序与请求顺序一致
resultStream = AsyncDataStream.orderedWait(stream,
new AsyncMysql(),
300,
TimeUnit.SECONDS,
1000).setParallelism(1);
}
resultStream.print();
env.execute("AsynFlinkMysql");
}
}
import com.alibaba.fastjson.JSON;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.async.ResultFuture;
import org.apache.flink.streaming.api.functions.async.RichAsyncFunction;
import java.util.Collections;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* 基于多线程的实现
*/
public class AsyncMysql extends RichAsyncFunction<String, String> {
private transient MysqlClient client;
private transient ExecutorService executorService;
@Override
public void asyncInvoke(String input, ResultFuture<String> resultFuture) throws Exception {
try {
executorService.submit(() -> {
// submit query
String imei = JSON.parseObject(input).get("user_id").toString();
String user = client.query(imei);
resultFuture.complete(Collections.singletonList(user));
});
} catch (Exception e) {
//log.error("get from redis fail", e);
throw new RuntimeException("get from mysql fail", e);
}
}
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
client = new MysqlClient();
client.init();
//线程池大小
executorService = Executors.newFixedThreadPool(30);
}
//异步客户端
@Override
public void close() throws Exception {
super.close();
executorService.shutdown();
}
Flink 异步IO的实现需要外部系统支持异步client,对于不支持异步client的系统,可以采用多线程机制替代实现。
二 、单并发度多线程
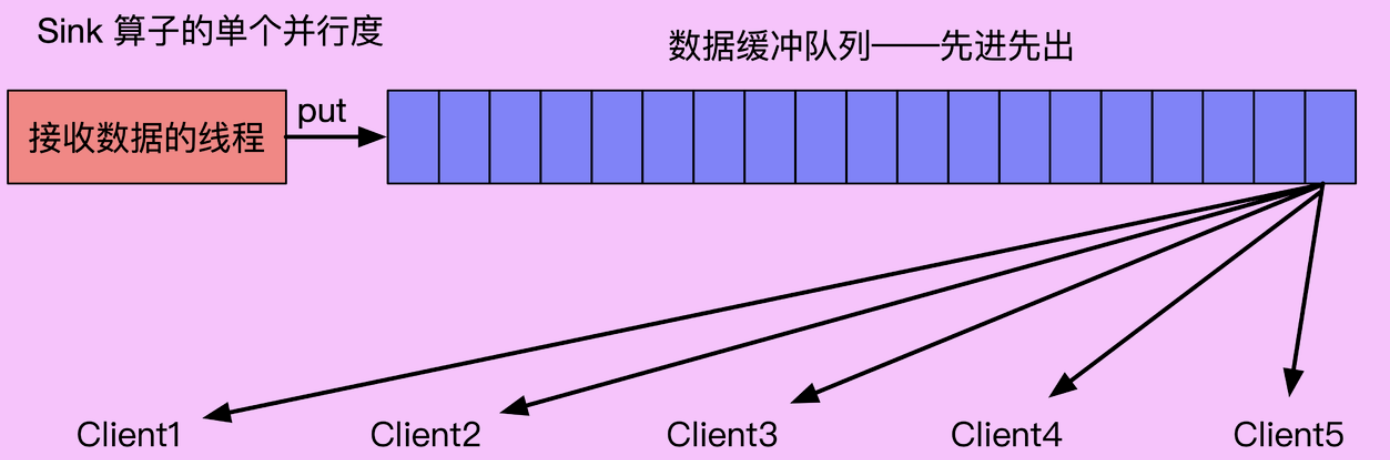
Flink 异步IO主要针对从外部系统读取数据,对于写数据的场景,可以在Sink端实现多线程的方式
三、Flink异步IO性能测试
场景
采用flink实现消费kafka,查询hbase,关联结果写入kafka
一.异步io与同步io对比
任务1:同步io并发度为1

任务2:同步io并发度为4

任务3: 异步io并发度为1

测试数据,分别处理10万/50万/100万
测试结果,三个任务对应的处理时间
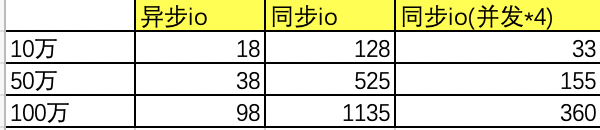
相同并发度情况下异步io吞吐能力相比同步io 提升10倍+,同步io并发度提高可以提升整体吞吐
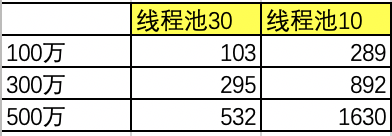
二 异步io多线程版本实现
任务1 线程池30
任务2 线程池10
测试数据,分别处理100万/300万/500万
测试结果
结论
借助异步io机制可以大幅提升任务整体吞吐,提高cpu利用率,多线程版本性能取决于线程池大小















 6397
6397











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











