








学习笔记|Pytorch使用教程08
本学习笔记主要摘自“深度之眼”,做一个总结,方便查阅。
使用Pytorch版本为1.2。
- transforms——图像变换
- transforms——transforms方法操作
- 自定义transforms方法
一.transforms——图像变换
1.Pad
功能:对图片边缘进行填充

- padding:设置填充大小
当为a时,上下左右均填充a个像素。
当为(a,b)时,上下填充b个像素,左右填充a个像素。
当为(a,b,c,d)时,上下左右分别填充a,b,c,d - padding_mode:填充模式,有4种模式,constant,edge,reflect和symmetric
- fill:constant时,设置填充的像数值,(R,G,B)or(Gray)
完整代码:
import os
import numpy as np
import torch
import random
from matplotlib import pyplot as plt
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
from tools.my_dataset import RMBDataset
from tools.common_tools import transform_invert
def set_seed(seed=1):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
set_seed(1) # 设置随机种子
# 参数设置
MAX_EPOCH = 10
BATCH_SIZE = 1
LR = 0.01
log_interval = 10
val_interval = 1
rmb_label = {"1": 0, "100": 1}
# ============================ step 1/5 数据 ============================
split_dir = os.path.join("..", "..", "data", "rmb_split")
train_dir = os.path.join(split_dir, "train")
valid_dir = os.path.join(split_dir, "valid")
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
train_transform = transforms.Compose([
transforms.Resize((224, 224)),
# 1 Pad
# transforms.Pad(padding=32, fill=(255, 0, 0), padding_mode='constant'),
# transforms.Pad(padding=(8, 64), fill=(255, 0, 0), padding_mode='constant'),
# transforms.Pad(padding=(8, 16, 32, 64), fill=(255, 0, 0), padding_mode='constant'),
# transforms.Pad(padding=(8, 16, 32, 64), fill=(255, 0, 0), padding_mode='symmetric'),
# 2 ColorJitter
# transforms.ColorJitter(brightness=0.5),
# transforms.ColorJitter(contrast=0.5),
# transforms.ColorJitter(saturation=0.5),
# transforms.ColorJitter(hue=0.3),
# 3 Grayscale
# transforms.Grayscale(num_output_channels=3),
# 4 Affine
# transforms.RandomAffine(degrees=30),
# transforms.RandomAffine(degrees=0, translate=(0.2, 0.2), fillcolor=(255, 0, 0)),
# transforms.RandomAffine(degrees=0, scale=(0.7, 0.7)),
# transforms.RandomAffine(degrees=0, shear=(0, 0, 0, 45)),
# transforms.RandomAffine(degrees=0, shear=90, fillcolor=(255, 0, 0)),
# 5 Erasing
# transforms.ToTensor(),
# transforms.RandomErasing(p=1, scale=(0.02, 0.33), ratio=(0.3, 3.3), value=(254/255, 0, 0)),
# transforms.RandomErasing(p=1, scale=(0.02, 0.33), ratio=(0.3, 3.3), value='1234'),
# 1 RandomChoice
# transforms.RandomChoice([transforms.RandomVerticalFlip(p=1), transforms.RandomHorizontalFlip(p=1)]),
# 2 RandomApply
# transforms.RandomApply([transforms.RandomAffine(degrees=0, shear=45, fillcolor=(255, 0, 0)),
# transforms.Grayscale(num_output_channels=3)], p=0.5),
# 3 RandomOrder
# transforms.RandomOrder([transforms.RandomRotation(15),
# transforms.Pad(padding=32),
# transforms.RandomAffine(degrees=0, translate=(0.01, 0.1), scale=(0.9, 1.1))]),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
valid_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std)
])
# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
valid_data = RMBDataset(data_dir=valid_dir, transform=valid_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)
# ============================ step 5/5 训练 ============================
for epoch in range(MAX_EPOCH):
for i, data in enumerate(train_loader):
inputs, labels = data # B C H W
img_tensor = inputs[0, ...] # C H W
img = transform_invert(img_tensor, train_transform)
plt.imshow(img)
plt.show()
plt.pause(0.5)
plt.close()
当设置 transforms.Pad(padding=32, fill=(255, 0, 0), padding_mode=‘constant’) 时:

会在图像四周扩充 32 个像素点,其RGB值为**(255,0,0)**。
当设置 transforms.Pad(padding=(8, 64), fill=(255, 0, 0), padding_mode=‘constant’) 时:

图像左右扩充 8 个像素点,上下扩充 64 个像素点,其RGB值为 (255,0,0) 。
当设置 transforms.Pad(padding=(8, 16, 32, 64), fill=(255, 0, 0), padding_mode=‘constant’) 时:

对应位置添加像素点。
当设置 transforms.Pad(padding=(8, 16, 32, 64), fill=(255, 0, 0), padding_mode=‘symmetric’) 时:

当设置成镜像(symmetric)模式时,fill这个参数就不起作用了。
2.ColorJitter
功能:调整亮度、对比度、饱和度和色相

- brightness:亮度调整因子
当为a时,从[max(0, 1 - a), 1 + a]中随机选择。
当为(a,b)时,从[a, b]中选择。 - constant:对比度参数,同brightness。
- saturation:饱和度参数,同brightness。
- hue:色相参数,当为a时,从[-a, a]中选择参数,注:0 <= a <= 0.5
当设置 transforms.ColorJitter(brightness=0.5) 时:
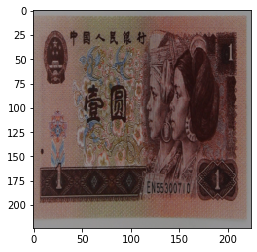
原始图片为:
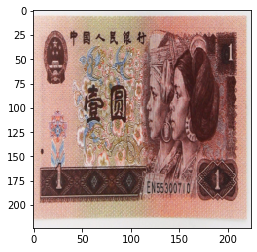
可以看出亮度发生变换,(brightness=0.5<1)会使得图片变暗,如果大于1,则可以变亮。
当设置 transforms.ColorJitter(contrast=0.5) 时:
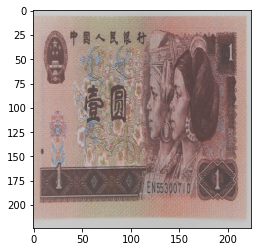
可以参考上述原图,发现对比度已经产生了变换。
当设置成 transforms.ColorJitter(saturation=0.5) 时:
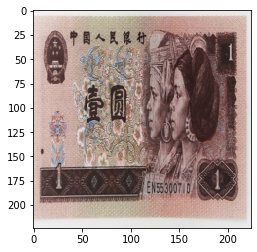
可以参考上述原图,发现饱和度已经产生了变换。
当设置成 transforms.ColorJitter(hue=0.3) 时:
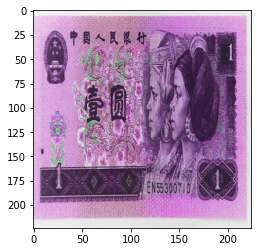
可以参考上述原图,发现色相已经产生了变换。
3.Grayscale
4.RandomGrayscale
功能:依概率将图片转换为灰度图

- num_output_channels:输出通道数,只能设置成1或3
- p:概率值,图像被转换为灰度图的概率
当设置 transforms.Grayscale(num_output_channels=3) 时:
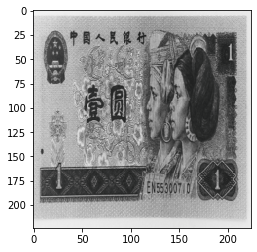
变成灰度图。
5.RandomAffine

功能:对图像进行仿射变换,仿射变换是二维的线性变换,由五种基本原子变换构成,分别是旋转、平移、缩放、错切和翻转。
- degrees:旋转角度设置
- translate:平移区间设置,如(a,b),a设置宽(width),b设置高(height)。
图像在宽维度平移的区间为 -img_width * a < dx < img_width * a 。 - scale:缩放比例(以面积为单位)
- fill_colore:一种填充颜色设置。
- shear:错切角度设置,有水平错切和锤子错切。
若为a,则仅在x轴错切,错切角度在(-a,a)之间
若为(a,b),则a设置x轴角度,b设置y的角度。
若为(a,b,c,d),则a,b设置x轴角度,c,d设置y轴角度。 - resample:采样方式,有NEAREST、BILINEAR 、BICUBIC。
- fill_color:填充的颜色
当设置 transforms.RandomAffine(degrees=30) 时:

随机旋转角度(-30°, +30°)。
当设置 transforms.RandomAffine(degrees=0, translate=(0.2, 0.2), fillcolor=(255, 0, 0)) 时:
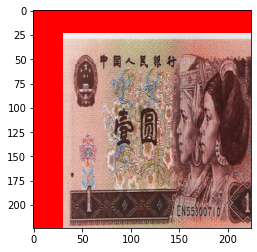
当设置 transforms.RandomAffine(degrees=0, scale=(0.7, 0.7)) 时:

图像会缩小,但图像所占面积不变,会用黑色像素点进行填充。
当设置 transforms.RandomAffine(degrees=0, shear=(0, 0, 0, 45)) 时:

这个是y轴错切。
当设置 transforms.RandomAffine(degrees=0, shear=90, fillcolor=(255, 0, 0)) 时:
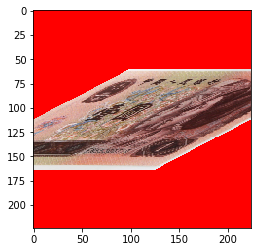
错切也可以设置填充区域。
6.RandomErasing
功能:对图像进行随机遮挡
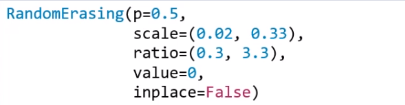
- p:概率值,执行该操作的概率
- scale:遮挡区域的面积
- ratio:遮挡区域的长宽比
- value: 设置遮挡区域的像数值(R,G,B)or(Gray)
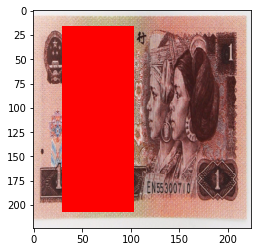
当设置
transforms.ToTensor(),
transforms.RandomErasing(p=1, scale=(0.02, 0.33), ratio=(0.3, 3.3), value=(254/255, 0, 0)),
#transforms.ToTensor(),
#transforms.Normalize(norm_mean, norm_std),
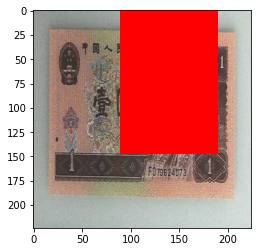
当设置 transforms.RandomErasing(p=1, scale=(0.02, 0.33), ratio=(0.3, 3.3), value=‘1234’) 时:
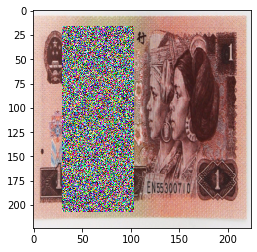
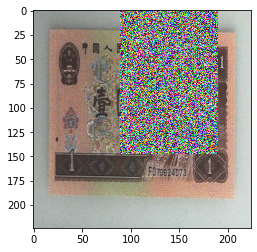
value设置成字符串的进行,就会随机填充。
7.transforms.Lambda
功能:用户自定义lambda方法。

- lambda:lambda匿名函数
lambda[arg1 [,arg2,…, argn]]: expression
eg:

二.transforms——transforms方法操作

设置:
transforms.RandomChoice([transforms.RandomVerticalFlip(p=1), transforms.RandomHorizontalFlip(p=1)])
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
输出:
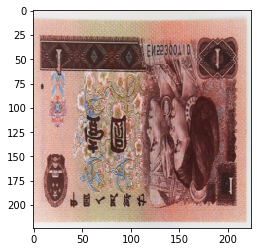
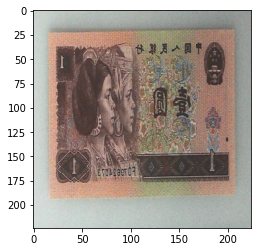
随机选择方法,是垂直翻转,还是水平翻转。
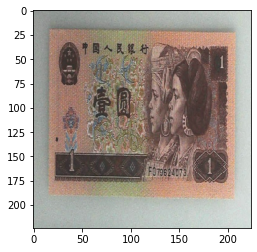
当设置:
transforms.RandomApply([transforms.RandomAffine(degrees=0, shear=45, fillcolor=(255, 0, 0)),
transforms.Grayscale(num_output_channels=3)], p=0.5),
输出:
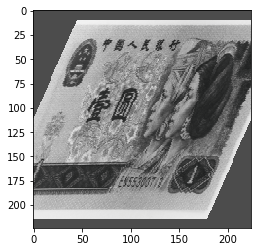
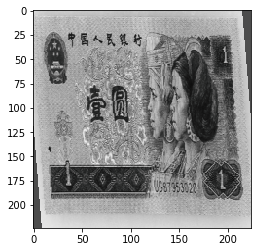
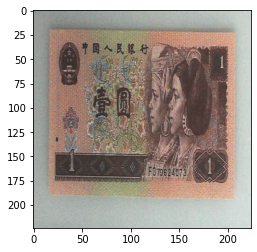
按一定的概率对图像进行操作。
设置:
transforms.RandomOrder([transforms.RandomRotation(15),
transforms.Pad(padding=32),
transforms.RandomAffine(degrees=0, translate=(0.01, 0.1), scale=(0.9, 1.1))]),
输出:


三.自定义transforms方法



测试代码:
import os
import numpy as np
import torch
import random
import torchvision.transforms as transforms
from PIL import Image
from matplotlib import pyplot as plt
from torch.utils.data import DataLoader
from tools.my_dataset import RMBDataset
from tools.common_tools import transform_invert
def set_seed(seed=1):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
set_seed(1) # 设置随机种子
# 参数设置
MAX_EPOCH = 10
BATCH_SIZE = 1
LR = 0.01
log_interval = 10
val_interval = 1
rmb_label = {"1": 0, "100": 1}
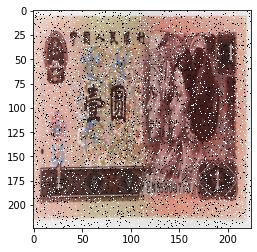
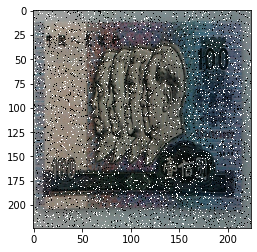
class AddPepperNoise(object):
"""增加椒盐噪声
Args:
snr (float): Signal Noise Rate
p (float): 概率值,依概率执行该操作
"""
def __init__(self, snr, p=0.9):
assert isinstance(snr, float) or (isinstance(p, float))
self.snr = snr
self.p = p
def __call__(self, img):
"""
Args:
img (PIL Image): PIL Image
Returns:
PIL Image: PIL image.
"""
if random.uniform(0, 1) < self.p:
img_ = np.array(img).copy()
h, w, c = img_.shape
signal_pct = self.snr
noise_pct = (1 - self.snr)
mask = np.random.choice((0, 1, 2), size=(h, w, 1), p=[signal_pct, noise_pct/2., noise_pct/2.])
mask = np.repeat(mask, c, axis=2)
img_[mask == 1] = 255 # 盐噪声
img_[mask == 2] = 0 # 椒噪声
return Image.fromarray(img_.astype('uint8')).convert('RGB')
else:
return img
# ============================ step 1/5 数据 ============================
split_dir = os.path.join("..", "..", "data", "rmb_split")
train_dir = os.path.join(split_dir, "train")
valid_dir = os.path.join(split_dir, "valid")
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
train_transform = transforms.Compose([
transforms.Resize((224, 224)),
AddPepperNoise(0.9, p=0.5),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
valid_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std)
])
# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
valid_data = RMBDataset(data_dir=valid_dir, transform=valid_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)
# ============================ step 5/5 训练 ============================
for epoch in range(MAX_EPOCH):
for i, data in enumerate(train_loader):
inputs, labels = data # B C H W
img_tensor = inputs[0, ...] # C H W
img = transform_invert(img_tensor, train_transform)
plt.imshow(img)
plt.show()
plt.pause(0.5)
plt.close()
输出:
四.总结

数据增强实战
- 原则:让训练集与测试集更接近。
- 空间位置:平移
- 色彩:灰度图,色彩抖动
- 形状:仿射变换
- 上下文场景:遮挡、填充
- ...
对第四套人民币分类,能否用到第五套人民币?

测试代码:
import os
import random
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
import torch.optim as optim
from matplotlib import pyplot as plt
from model.lenet import LeNet
from tools.my_dataset import RMBDataset
from tools.common_tools import transform_invert
def set_seed(seed=1):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
set_seed() # 设置随机种子
rmb_label = {"1": 0, "100": 1}
# 参数设置
MAX_EPOCH = 10
BATCH_SIZE = 16
LR = 0.01
log_interval = 10
val_interval = 1
# ============================ step 1/5 数据 ============================
split_dir = os.path.join("..", "..", "data", "rmb_split")
train_dir = os.path.join(split_dir, "train")
valid_dir = os.path.join(split_dir, "valid")
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
train_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.RandomCrop(32, padding=4),
#transforms.RandomGrayscale(p=0.9),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
valid_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
valid_data = RMBDataset(data_dir=valid_dir, transform=valid_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)
# ============================ step 2/5 模型 ============================
net = LeNet(classes=2)
net.initialize_weights()
# ============================ step 3/5 损失函数 ============================
criterion = nn.CrossEntropyLoss() # 选择损失函数
# ============================ step 4/5 优化器 ============================
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9) # 选择优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1) # 设置学习率下降策略
# ============================ step 5/5 训练 ============================
train_curve = list()
valid_curve = list()
for epoch in range(MAX_EPOCH):
loss_mean = 0.
correct = 0.
total = 0.
net.train()
for i, data in enumerate(train_loader):
# forward
inputs, labels = data
outputs = net(inputs)
# backward
optimizer.zero_grad()
loss = criterion(outputs, labels)
loss.backward()
# update weights
optimizer.step()
# 统计分类情况
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).squeeze().sum().numpy()
# 打印训练信息
loss_mean += loss.item()
train_curve.append(loss.item())
if (i+1) % log_interval == 0:
loss_mean = loss_mean / log_interval
print("Training:Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, i+1, len(train_loader), loss_mean, correct / total))
loss_mean = 0.
scheduler.step() # 更新学习率
# validate the model
if (epoch+1) % val_interval == 0:
correct_val = 0.
total_val = 0.
loss_val = 0.
net.eval()
with torch.no_grad():
for j, data in enumerate(valid_loader):
inputs, labels = data
outputs = net(inputs)
loss = criterion(outputs, labels)
_, predicted = torch.max(outputs.data, 1)
total_val += labels.size(0)
correct_val += (predicted == labels).squeeze().sum().numpy()
loss_val += loss.item()
valid_curve.append(loss_val)
print("Valid:\t Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, j+1, len(valid_loader), loss_val, correct / total))
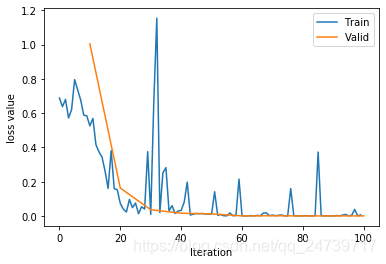
train_x = range(len(train_curve))
train_y = train_curve
train_iters = len(train_loader)
valid_x = np.arange(1, len(valid_curve)+1) * train_iters*val_interval # 由于valid中记录的是epochloss,需要对记录点进行转换到iterations
valid_y = valid_curve
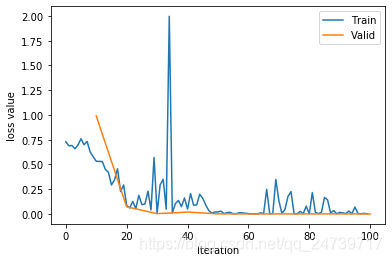
plt.plot(train_x, train_y, label='Train')
plt.plot(valid_x, valid_y, label='Valid')
plt.legend(loc='upper right')
plt.ylabel('loss value')
plt.xlabel('Iteration')
plt.show()
# ============================ inference ============================
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
test_dir = os.path.join(BASE_DIR, "test_data")
test_data = RMBDataset(data_dir=test_dir, transform=valid_transform)
valid_loader = DataLoader(dataset=test_data, batch_size=1)
for i, data in enumerate(valid_loader):
# forward
inputs, labels = data
outputs = net(inputs)
_, predicted = torch.max(outputs.data, 1)
rmb = 1 if predicted.numpy()[0] == 0 else 100
img_tensor = inputs[0, ...] # C H W
img = transform_invert(img_tensor, train_transform)
plt.imshow(img)
plt.title("LeNet got {} Yuan".format(rmb))
plt.show()
plt.pause(0.5)
plt.close()
输出:
Training:Epoch[000/010] Iteration[010/010] Loss: 0.6578 Acc:56.88%
Valid: Epoch[000/010] Iteration[002/002] Loss: 1.0045 Acc:56.88%
Training:Epoch[001/010] Iteration[010/010] Loss: 0.3343 Acc:89.38%
Valid: Epoch[001/010] Iteration[002/002] Loss: 0.1628 Acc:89.38%
Training:Epoch[002/010] Iteration[010/010] Loss: 0.0836 Acc:98.75%
Valid: Epoch[002/010] Iteration[002/002] Loss: 0.0362 Acc:98.75%
Training:Epoch[003/010] Iteration[010/010] Loss: 0.2507 Acc:95.00%
Valid: Epoch[003/010] Iteration[002/002] Loss: 0.0157 Acc:95.00%
Training:Epoch[004/010] Iteration[010/010] Loss: 0.0389 Acc:98.75%
Valid: Epoch[004/010] Iteration[002/002] Loss: 0.0119 Acc:98.75%
Training:Epoch[005/010] Iteration[010/010] Loss: 0.0402 Acc:98.75%
Valid: Epoch[005/010] Iteration[002/002] Loss: 0.0001 Acc:98.75%
Training:Epoch[006/010] Iteration[010/010] Loss: 0.0043 Acc:100.00%
Valid: Epoch[006/010] Iteration[002/002] Loss: 0.0008 Acc:100.00%
Training:Epoch[007/010] Iteration[010/010] Loss: 0.0178 Acc:99.38%
Valid: Epoch[007/010] Iteration[002/002] Loss: 0.0000 Acc:99.38%
Training:Epoch[008/010] Iteration[010/010] Loss: 0.0381 Acc:99.38%
Valid: Epoch[008/010] Iteration[002/002] Loss: 0.0000 Acc:99.38%
Training:Epoch[009/010] Iteration[010/010] Loss: 0.0065 Acc:100.00%
Valid: Epoch[009/010] Iteration[002/002] Loss: 0.0001 Acc:100.00%
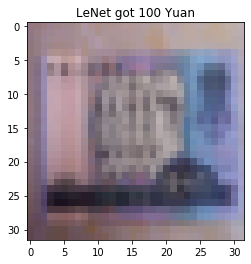
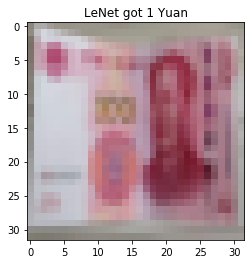
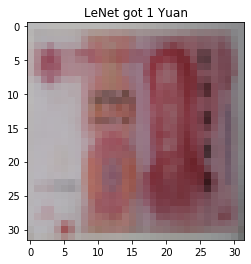
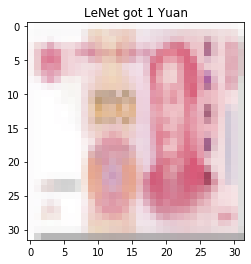
发现对第五套RMB分类错误,但发现第五套和第四套RMB在形态上相似,只是第五套RMB色调偏红,因此在色彩上进行变换(数据增强),设置transforms.RandomGrayscale(p=0.9)
输出:
Training:Epoch[000/010] Iteration[010/010] Loss: 0.6856 Acc:52.50%
Valid: Epoch[000/010] Iteration[002/002] Loss: 0.9902 Acc:52.50%
Training:Epoch[001/010] Iteration[010/010] Loss: 0.4071 Acc:85.00%
Valid: Epoch[001/010] Iteration[002/002] Loss: 0.0719 Acc:85.00%
Training:Epoch[002/010] Iteration[010/010] Loss: 0.1547 Acc:93.75%
Valid: Epoch[002/010] Iteration[002/002] Loss: 0.0026 Acc:93.75%
Training:Epoch[003/010] Iteration[010/010] Loss: 0.3176 Acc:90.62%
Valid: Epoch[003/010] Iteration[002/002] Loss: 0.0187 Acc:90.62%
Training:Epoch[004/010] Iteration[010/010] Loss: 0.0939 Acc:96.25%
Valid: Epoch[004/010] Iteration[002/002] Loss: 0.0008 Acc:96.25%
Training:Epoch[005/010] Iteration[010/010] Loss: 0.0115 Acc:100.00%
Valid: Epoch[005/010] Iteration[002/002] Loss: 0.0000 Acc:100.00%
Training:Epoch[006/010] Iteration[010/010] Loss: 0.0621 Acc:98.75%
Valid: Epoch[006/010] Iteration[002/002] Loss: 0.0000 Acc:98.75%
Training:Epoch[007/010] Iteration[010/010] Loss: 0.0696 Acc:95.62%
Valid: Epoch[007/010] Iteration[002/002] Loss: 0.0001 Acc:95.62%
Training:Epoch[008/010] Iteration[010/010] Loss: 0.0609 Acc:96.88%
Valid: Epoch[008/010] Iteration[002/002] Loss: 0.0001 Acc:96.88%
Training:Epoch[009/010] Iteration[010/010] Loss: 0.0143 Acc:99.38%
Valid: Epoch[009/010] Iteration[002/002] Loss: 0.0000 Acc:99.38%
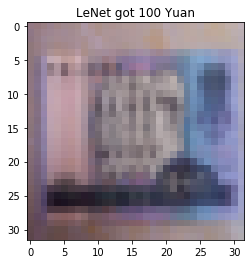
















 4409
4409











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









