







KDD 2018, August 19-23, 2018, London, United Kingdom
Mihajlo Grbovic;Airbnb, Inc;San Francisco, California, USA
Haibin Cheng Airbnb, Inc. San Francisco, California, USA
摘要
爱彼迎是一个双边市场,需要同时优化租户和房东的偏好。本文中我们为了在搜索过程中达到实时的个性化,使用了相似列表推荐和用户嵌入技术。该嵌入模型专门为爱彼迎市场设计,能够捕捉用户的短期和长期兴趣,从而提供有效的住房推荐。
介绍
在过去十年中,机器学习已经开始出现在基于传统信息检索的搜索架构中,特别是在搜索序列。造成这个趋势的原因是能搜集和分析的搜索数据不断增长,这些数据为在个性化特定用户的搜索使用机器学习提供了可能性。
任何搜索算法的目标都可能因平台而异。 虽然一些平台旨在增加网站参与度(例如点击次数和在搜索的新闻文章上花费的时间),但其他平台旨在最大化转换(例如购买正在搜索的商品或服务),以及双边市场的情况 我们经常需要优化市场双方的搜索结果,即卖家和买家。在许多现实应用中,双边市场已经成为一个可行的商业模式。我们将社会网络范式转化为具有供需两种不同类型的参与者。相似的结构有爱彼迎,uber,lyft,etsy等。这种类型的市场的内容发现和搜索排序需要同时满足供需双方。
在爱彼迎中,需要得到地点、价格、风格和评论等的排序列表以吸引客户,同时还需要确定旅行时间和起始时间是否与房东匹配。此外,还需要检测可能因拒绝评论,宠物,逗留时间,团体规模或任何其他因素而拒绝客人的列表。为了做到这一点,我们使用排序学习(leanring to rank)。我们将问题表示为成对回归,其中包含预测的正实用程序和拒绝的负实用程序,我们使用修改后的Lambda Rank [4]模型进行优化,该模型共同优化了市场双方的排名。
由于客人通常在预订前进行多次搜索,即点击多个列表并在搜索会话期间联系多个房东,我们可以使用这些会话中的信号,即点击,联系房东等,以实现实时个性化 目的是向客人展示更多类似于我们认为他们喜欢的列表,因为他们正在开始搜索会话。同时我们可以使用负信号,例如 跳过高排名的房源,向客人展示与我们认为不喜欢的房源相似的房源。 为了能够计算客人与之交互的列表与需要排名的候选列表之间的相似性,我们建议使用列表嵌入,从搜索会话中学习的低维向量表示。 我们利用这些相似之处为我们的搜索排名模型创建个性化功能,并推动我们的类似上市建议,这两个平台推动了爱彼迎99%的预订。
为了解决某些不活跃用户的长尾问题,我们建议在用户类型级别而不是特定用户ID上训练嵌入,其中使用利用已知用户属性的多对一规则映射来确定类型。同时,我们在与用户类型嵌入相同的向量空间中学习列表类型嵌入。这使我们能够计算进行搜索的用户的用户类型嵌入与需要排名的候选列表的列表类型嵌入之间的相似性。
本文的创新点在于:
- 实时个性化:以前使用个性化和项目建议大多通过形成用户项目和项目项目推荐的表格,然后在推荐时从它们读取来部署到生产中。 我们实施了一种解决方案,将用户最近使用的项目的嵌入以在线方式组合,以计算与需要排名的项目的相似性。
- 采用集中搜索的训练:和网页搜索不同,旅游平台的搜索通常较为集中,例如巴黎。我们采用嵌入式训练算法,在进行负抽样时将其考虑在内,从而获得更好的市场内列表相似性
- 利用转换作为全球背景:我们认识到最终转换的点击会话的重要性, 在学习列表嵌入时,我们将预订列表视为全局上下文,当窗口在会话上移动时,该上下文始终被预测。
- 用户类型嵌入:之前训练用户嵌入的工作都是为了捕捉他们的长期兴趣,从而为每一个用户训练一个单独的嵌入。当目标信号稀疏,就没有足够的数据为每个用户训练嵌入。出于这个原因,我们建议在用户类型的级别上训练嵌入,其中具有相同类型的用户组将具有相同的嵌入。
- 拒绝作为明确的否定:为了减少被拒绝的推荐,我们在训练中将房东的明确拒绝作为否定来编码到用户和列表类型嵌入中。
对于短期兴趣个性化,我们使用超过8亿次搜索点击会话培训列表嵌入,从而获得高质量的列表表示。 我们在真实搜索流量上使用了大量的在线评估,这表明在排名模型中添加嵌入功能可以获得显着的预订收益。 除了搜索排名算法之外,列表嵌入已成功测试并针对类似的列表建议启动,其中它们的性能优于现有算法点击通过率(CTR)20%。
对于长期兴趣个性化,我们使用5000万用户使用预订列表的序列来训练用户类型和列表类型嵌入。 用户和列表类型嵌入都是在相同的向量空间中学习的,这样我们就可以计算用户类型和需要排序的列表的列表类型之间的相似性。 相似性被用作搜索排名模型的附加功能,并且还成功测试并启动。
相关工作
在一些NLP应用中,传统的语言模型算法中将词作为高维稀疏向量已经被词嵌入模型取代,即通过使用神经网络用低维向量表示词。该网络通过直接考虑词序和共现训练而成,其基于一个假设:经常在句子中一起出现的词语具有统计相关性。随着表示学习中CBOW(highly scalable
continuous bag-of-words)和SG(skip-gram)的发展,嵌入模型在很多传统的语言任务中有着高水平的表现。
最近,嵌入式的概念已经从单词表示扩展到NLP领域之外的其他应用领域。网页搜索、电商以及市场等领域迅速意识到就像可以通过将句子中的单词序列作为上下文来训练单词嵌入一样,也可以训练用户操作的嵌入,例如通过将用户操作序列作为上下文来处理被单击或购买的项目、被单击的查询和广告。自此,我们看到嵌入被用于Web上各种类型的推荐,包括音乐推荐,工作搜索,应用推荐,电影推荐等。此外,还表明可以利用与用户交互的项直接精益用户嵌入到与项嵌入相同的功能空间中,这样就可以直接提出用户项建议。对于冷启动建议特别有用的另一种方法是仍然使用文本嵌入(例如,可以在https://code.google.com/p/word2vec上公开获取),并利用项和/或用户元数据(例如标题和描述)来计算它们的嵌入。最后,类似的嵌入方法的扩展也被提出用于社交网络分析,利用图上的随机游动学习节点在图结构中的嵌入。
嵌入方法对学术界和工业界都产生了重大影响。 最近的行业会议出版物和出版物表明,它们已成功部署在各大网络公司的各种个性化,推荐和排名引擎中,例如雅虎、etsy,criteo ,linkedin,facebook等。
算法
在下文中,我们介绍了在Airbnb上搜索推荐和列出排名的任务的建议方法。 我们描述了两种不同的方法,即分别列出用于短期实时个性化的嵌入和用于长期个性化的用户类型和列表类型嵌入。
列表嵌入
我们假设从N个用户中获得了s点击回话的一个集合S,其中 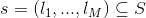
该模型的目标是通过在整个搜索会话集合S中最大化目标函数L来学习使用skip-gram模型的列表表示,定义如下

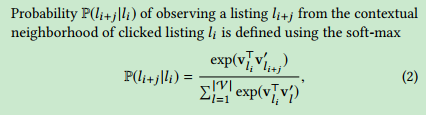
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 284
284











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









