







1、HIVE的计算引擎
- hive的引擎mapreduce、tez和spark三者比较
- hive sql执行方式对比(tez,mapreduce,spark,storm)
- TEZ和MapReduce区别
- Flink on Hive构建流批一体数仓
- MR引擎在HIVE 2中将被弃用,官方推荐使用TEZ或SPARK等引擎,在实际应用中如果使用TEZ或者SPARK计算时出现内存溢出的问题(TEZ和SPARK都是内存式计算),可以考虑使用MR进行运算,虽然慢但是肯定会出结果。
- Flink使用HiveCatalog可以通过批或者流的方式来处理Hive中的表。这就意味着Flink既可以作为Hive的一个批处理引擎,也可以通过流处理的方式来读写Hive中的表,从而为实时数仓的应用和流批一体的落地实践奠定了坚实的基础。
2、配置Hive on TEZ
tez-0.10.1-SNAPSHOT-minimal.tar.gz
tez-0.10.1-SNAPSHOT.tar.gz
安装包下载地址:https://pan.baidu.com/s/1PePN7BXvQGheJxqT5bYYjQ 提取码:i9yb
# 解压TEZ安装包
[atguigu@hadoop102 software]$ tar -zxvf tez-0.10.1-SNAPSHOT-minimal.tar.gz -C /opt/module/tez/
# HDFS上创建TEZ依赖文件夹
[atguigu@hadoop102 software]$ hdfs dfs -mkdir /tez
# 上传tez依赖到HDFS
[atguigu@hadoop102 software]$ hdfs dfs -put tez-0.10.1-SNAPSHOT.tar.gz /tez
2022-01-17 22:39:04,937 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
# 新建tez-site.xml
[atguigu@hadoop102 software]$ cat $HADOOP_HOME/etc/hadoop/tez-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>tez.lib.uris</name>
<value>${fs.defaultFS}/tez/tez-0.10.1-SNAPSHOT.tar.gz</value>
</property>
<property>
<name>tez.use.cluster.hadoop-libs</name>
<value>true</value>
</property>
<property>
<name>tez.am.resource.memory.mb</name>
<value>1024</value>
</property>
<property>
<name>tez.am.resource.cpu.vcores</name>
<value>1</value>
</property>
<property>
<name>tez.container.max.java.heap.fraction</name>
<value>0.4</value>
</property>
<property>
<name>tez.task.resource.memory.mb</name>
<value>1024</value>
</property>
<property>
<name>tez.task.resource.cpu.vcores</name>
<value>1</value>
</property>
</configuration>
# 修改Hadoop环境变量,添加Tez的Jar包相关信息
[atguigu@hadoop102 software]$ cat $HADOOP_HOME/etc/hadoop/shellprofile.d/tez.sh
hadoop_add_profile tez
function _tez_hadoop_classpath
{
hadoop_add_classpath "$HADOOP_HOME/etc/hadoop" after
hadoop_add_classpath "/opt/module/tez/*" after
hadoop_add_classpath "/opt/module/tez/lib/*" after
}
# 修改Hive的计算引擎
[atguigu@hadoop102 software]$ cat $HIVE_HOME/conf/hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 修改Hive的计算引擎 -->
<property>
<name>hive.execution.engine</name>
<value>tez</value>
</property>
<property>
<name>hive.tez.container.size</name>
<value>1024</value>
</property>
<!-- hive窗口打印默认库和表头 -->
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<!-- 指定hiveserver2连接的host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop102</value>
</property>
<!-- 指定hiveserver2连接的端口号 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<!-- jdbc连接的URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value>
</property>
<!-- jdbc连接的Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc连接的username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc连接的password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
<!-- Hive默认在HDFS的工作目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<!-- Hive元数据存储的验证 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!-- 元数据存储授权 -->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
</configuration>
# 解决日志Jar包冲突
[atguigu@hadoop102 software]$ rm /opt/module/tez/lib/slf4j-log4j12-1.7.10.jar
DBeaver、beeline 举例,试运行
set tez.queue.name=hive;
set hive.execution.engine=tez;
SELECT
videoId,
views
FROM
gulivideo_orc
ORDER BY
views DESC
LIMIT 10;
3、TEZ使用心得
- 真正让你明白Hive参数调优系列2:如何控制reduce个数与参数调优
- DataGrip连接hive建表时报cannot recognize input near ‘show‘ ‘indexes‘ ‘on‘ in ddl statement错误
- Hive JDBC连接Tez(AM)容器长期不释放问题的解决方法
- YARN Capacity Scheduler(容量调度器)
集群资源不足情况下的TEZ使用心得:
- HIVE on TEZ时,任务运行完成并不会释放TEZ获取的资源,若不手动释放(yarn application -kill 任务名),将持续占用;
- 同一个队列有多个TEZ SESSION时,后来者挂起,直至前者释放资源,后者才可以获取资源;(原因参考PS)
- [set tez.queue.name=hive]设置TEZ使用的队列,[mapreduce.job.queuename=hive]设置MR使用的队列;
- 多个TEZ SESSION各自占用不同的队列时,多个TEZ SESSION可以并行执行, [set tez.queue.name=default];
PS:maximum-am-resource-percent:集群中用于运行应用程序ApplicationMaster的资源比例上限,该参数通常用于限制处于活动状态的应用程序数目。所有队列的ApplicationMaster资源比例上限可通过参数yarn.scheduler.capacity.maximum-am-resource-percent设置,而单个队列可通过参数yarn.scheduler.capacity.<queue-path>.maximum-am-resource-percent设置适合自己的值。
# 表示不人为设置reduce的个数
set mapred.reduce.tasks=-1;
# 设置HIVE的不同引擎
set hive.execution.engine=mr;
set hive.execution.engine=spark;
set hive.execution.engine=tez;
# 如果使用的引擎是mr(设置队列(hive为队列名称,默认为default))
set mapreduce.job.queuename=hive;
# 如果使用的引擎是tez(设置队列(hive为队列名称,默认为default))
set tez.queue.name=hive;
# 打印yarn任务,杀掉yarn任务
yarn application -list
yarn application -kill 任务名
hive on spark 相关参数设置
#设置计算引擎
set hive.execution.engine=spark;
#设置spark提交模式
set spark.master=yarn-cluster;
#设置作业提交队列
set spark.yarn.queue=queue_name;
#设置作业名称
set spark.app.name=job_name;
#该参数用于设置Spark作业总共要用多少个Executor进程来执行
set spark.executor.instances=25;
#设置执行器计算核个数
set spark.executor.cores=4;
#设置执行器内存
set spark.executor.memory=8g
#设置每个executor的jvm堆外内存
set spark.yarn.executor.memoryOverhead=2048;
#设置内存比例(spark2.0+)
set spark.memory.fraction=0.8;
#设置对象序列化方式
set spark.serializer=org.apache.serializer.KyroSerializer;
4、Hive优化(和Hadoop优化是对应的)
4.1、查看SQL的执行计划
搞定Hive执行计划(备用)
Hive性能调优之Fetch抓取、本地模式
读懂简单的hive执行计划-explain计划
hive执行计划分析(join详解)
万字长文详解HiveSQL执行计划 (含定位数据倾斜方法)
hive sql将编译成MapReduce任务去执行的,编译可以分为六个阶段:
① Antlr定义SQL的语法规则,完成SQL词法、语法解析,将SQL转化为抽象语法树AST Tree
② 遍历AST Tree,抽象出查询的基本组成单元QueryBlock
③ 遍历QueryBlock,翻译为执行操作树OperatorTree
④ 逻辑层优化器进行OperatorTree变换,合并不必要的ReduceSinkOperator,减少shuffle数据量
⑤ 遍历OperatorTree,翻译为MapReduce任务
⑥ 物理层优化器进行MapReduce任务的变换,生成最终的执行计划
# 查看执行计划,添加extended关键字可以查看更加详细的执行计划
explain [extended] query
hive (default)> select count(1) from emp group by empno;
Query ID = atguigu_20220708064339_67dd9bdc-363a-456d-967e-ca80a858f957
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1657233056128_0002, Tracking URL = http://hadoop103:8088/proxy/application_1657233056128_0002/
Kill Command = /opt/module/hadoop-3.1.3/bin/mapred job -kill job_1657233056128_0002
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2022-07-08 06:43:47,778 Stage-1 map = 0%, reduce = 0%
2022-07-08 06:43:54,966 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.46 sec
2022-07-08 06:44:05,223 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 6.02 sec
MapReduce Total cumulative CPU time: 6 seconds 20 msec
Ended Job = job_1657233056128_0002
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 6.02 sec HDFS Read: 14581 HDFS Write: 283 SUCCESS
Total MapReduce CPU Time Spent: 6 seconds 20 msec
OK
_c0
1
hive (default)> explain select count(1) from emp group by empno;
OK
Explain
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: emp
Statistics: Num rows: 1 Data size: 6570 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: empno (type: int)
outputColumnNames: empno
Statistics: Num rows: 1 Data size: 6570 Basic stats: COMPLETE Column stats: NONE
Group By Operator
aggregations: count()
keys: empno (type: int)
mode: hash
outputColumnNames: _col0, _col1
Statistics: Num rows: 1 Data size: 6570 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: int)
sort order: +
Map-reduce partition columns: _col0 (type: int)
Statistics: Num rows: 1 Data size: 6570 Basic stats: COMPLETE Column stats: NONE
value expressions: _col1 (type: bigint)
Execution mode: vectorized
Reduce Operator Tree:
Group By Operator
aggregations: count(VALUE._col0)
keys: KEY._col0 (type: int)
mode: mergepartial
outputColumnNames: _col0, _col1
Statistics: Num rows: 1 Data size: 6570 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col1 (type: bigint)
outputColumnNames: _col0
Statistics: Num rows: 1 Data size: 6570 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 1 Data size: 6570 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
Time taken: 0.259 seconds, Fetched: 53 row(s)
Map-Reduce Framework
# 所有map task从HDFS读取的文件总行数
Map input records=14
# map task的直接输出record是多少,就是在map方法中调用context.write的次数,也就是未经过Combine时的原生输出条数
Map output records=14
# Map的输出结果key/value都会被序列化到内存缓冲区中,所以这里的bytes指序列化后的最终字节之和
Map output bytes=224
Map output materialized bytes=258
Input split bytes=207
# Combiner是为了减少尽量减少需要拉取和移动的数据,所以combine输入条数与map的输出条数是一致的。
Combine input records=0
# 经过Combiner后,相同key的数据经过压缩,在map端自己解决了很多重复数据,表示最终在map端中间文件中的所有条目数
# Combine output records
Spilled Records=14
# copy线程在抓取map端中间数据时,如果因为网络连接异常或是IO异常,所引起的shuffle错误次数
Failed Shuffles=0
# 记录着shuffle过程中总共经历了多少次merge动作
Merged Map outputs=0
# 通过JMX获取到执行map与reduce的子JVM总共的GC时间消耗
GC time elapsed (ms)=109
CPU time spent (ms)=2460
Physical memory (bytes) snapshot=388427776
Virtual memory (bytes) snapshot=2601951232
Total committed heap usage (bytes)=317718528
Peak Map Physical memory (bytes)=388427776
Peak Map Virtual memory (bytes)=2601951232
Map-Reduce Framework
Combine input records=0
Combine output records=0
# Reduce总共读取了多少个这样的groups
Reduce input groups=14
# Reduce端的copy线程总共从map端抓取了多少的中间数据,表示各个map task最终的中间文件总和
Reduce shuffle bytes=258
# 如果有Combiner的话,那么这里的数值就等于map端Combiner运算后的最后条数,如果没有,那么就应该等于map的输出条数
Reduce input records=14
# 所有reduce执行后输出的总条目数
Reduce output records=0
# spill过程在map和reduce端都会发生,这里统计在总共从内存往磁盘中spill了多少条数据
Spilled Records=14
# 每个reduce几乎都得从所有map端拉取数据,每个copy线程拉取成功一个map的数据,那么增1,所以它的总数基本等于 reduce number * map number
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=391
CPU time spent (ms)=3560
Physical memory (bytes) snapshot=306245632
Virtual memory (bytes) snapshot=2607038464
Total committed heap usage (bytes)=241172480
Peak Reduce Physical memory (bytes)=306245632
Peak Reduce Virtual memory (bytes)=2607038464
4.2、设置合适的参数
009 Hadoop 优化&新特性&HA
013 大数据之HIVE压缩和存储
MapReduce优化方法
### 以下参数是在用户自己的MR应用程序中配置就可以生效(mapred-default.xml)
# 一个MapTask可使用的资源上限(单位:MB),默认为1024。如果MapTask实际使用的资源量超过该值,则会被强制杀死。
hive (default)> set mapreduce.map.memory.mb;
mapreduce.map.memory.mb=-1
# 一个ReduceTask可使用的资源上限(单位:MB),默认为1024。如果ReduceTask实际使用的资源量超过该值,则会被强制杀死。
hive (default)> set mapreduce.reduce.memory.mb;
mapreduce.reduce.memory.mb=-1
# 每个MapTask可使用的最多cpu core数目,默认值: 1
hive (default)> set mapreduce.map.cpu.vcores;
mapreduce.map.cpu.vcores=1
# 每个ReduceTask可使用的最多cpu core数目,默认值: 1
hive (default)> set mapreduce.reduce.cpu.vcores;
mapreduce.reduce.cpu.vcores=1
# 每个Reduce去Map中取数据的并行数。默认值是5
hive (default)> set mapreduce.reduce.shuffle.parallelcopies;
mapreduce.reduce.shuffle.parallelcopies=5
# Buffer中的数据达到多少比例开始写入磁盘。默认值0.66
hive (default)> set mapreduce.reduce.shuffle.merge.percent;
mapreduce.reduce.shuffle.merge.percentBuffer is undefined
# Buffer大小占Reduce可用内存的比例。默认值0.7
hive (default)> set mapreduce.reduce.shuffle.input.buffer.percent;
mapreduce.reduce.shuffle.input.buffer.percentBuffer is undefined
# 指定多少比例的内存用来存放Buffer中的数据,默认值是0.0
hive (default)> set mapreduce.reduce.input.buffer.percent;
mapreduce.reduce.input.buffer.percent=0.0
### 应该在YARN启动之前就配置在服务器的配置文件中才能生效(yarn-default.xml)
# 给应用程序Container分配的最小内存
hive (default)> set yarn.scheduler.minimum-allocation-mb;
yarn.scheduler.minimum-allocation-mb=512
# 给应用程序Container分配的最大内存
hive (default)> set yarn.scheduler.maximum-allocation-mb;
yarn.scheduler.maximum-allocation-mb=4096
# 每个Container申请的最小CPU核数
hive (default)> set yarn.scheduler.minimum-allocation-vcores;
yarn.scheduler.minimum-allocation-vcores=1
# 每个Container申请的最大CPU核数
hive (default)> set yarn.scheduler.maximum-allocation-vcores;
yarn.scheduler.maximum-allocation-vcores=4
# 节点最大可用内存,实际给Containers分配的最大物理内存,默认值:8192
hive (default)> set yarn.nodemanager.resource.memory-mb;
yarn.nodemanager.resource.memory-mb=4096
### Shuffle性能优化的关键参数,应在YARN启动之前就配置好(mapred-default.xml)
# Shuffle的环形缓冲区大小,默认100m
hive (default)> set mapreduce.task.io.sort.mb;
mapreduce.task.io.sort.mb=100
# 环形缓冲区溢出的阈值,默认80%
hive (default)> set mapreduce.map.sort.spill.percent;
mapreduce.map.sort.spill.percent=0.80
### 容错相关参数(MapReduce性能优化)
hive (default)> set mapreduce.map.maxattempts;
mapreduce.map.maxattempts=4
hive (default)> set mapreduce.reduce.maxattempts;
mapreduce.reduce.maxattempts=4
hive (default)> set mapreduce.task.timeoutTask;
mapreduce.task.timeoutTask is undefined
默认情况下,数据达到一个阈值时,Buffer中的数据就会写入磁盘,然后Reduce会从磁盘中获得所有得数据,也就是说Buffer和Reduce是没有直接得关联得,可以通过设置参数,使Buffer中得一部分数据可以直接输送到Reduce,从而减少I/O开销,mapreduce.reduce.input.buffer.percent默认为0.0,当大于0时,会保留指定比例得内存读Buffer中得数据直接拿给Reduce使用。
# 列裁剪,取数只取查询中需要用到的列,默认是true
# Hive 在读数据的时候,可以只读取查询中所需要用到的列,而忽略其他的列。
# 这样做可以节省读取开销:中间表存储开销和数据整合开销。
set hive.optimize.cp = true;
# 分区裁剪,在查询的过程中只选择需要的分区,默认是true
set hive.optimize.pruner=true;
# 举例
select * from student where department = "AAAA";
# 将 SQL 语句中的 where 谓词逻辑都尽可能提前执行,减少下游处理的数据量。默认是true
set hive.optimize.ppd=true;
# 举例
select a.*, b.* from a join b on a.id = b.id where b.age > 20;
select a.*, c.* from a join (select * from b where age > 20) c on a.id = c.id;
# 合并小文件,Map 输入合并
# Map端输入、合并文件之后按照block的大小分割(默认)
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
# Map端输入,不合并
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
# 合并小文件,Map/Reduce输出合并
# 是否合并Map输出文件, 默认值为true
set hive.merge.mapfiles=true;
# 是否合并Reduce端输出文件,默认值为false
set hive.merge.mapredfiles=true;
# 合并文件的大小,默认值为256000000
set hive.merge.size.per.task=256000000; -----
# 每个Map 最大分割大小
set mapred.max.split.size=256000000;
# 一个服务器节点上split的最少值
set mapred.min.split.size.per.node=1; -----
# 一个服务器机架上split的最少值
set mapred.min.split.size.per.rack=1;
4.3、合理设置MapTask并行度
一个MapReduce Job 的 MapTask 数量是由输入分片InputSplit 决定的。而输入分片是由 FileInputFormat.getSplit() 决定的。一个输入分片对应一个MapTask,而输入分片是由三个参数决定。
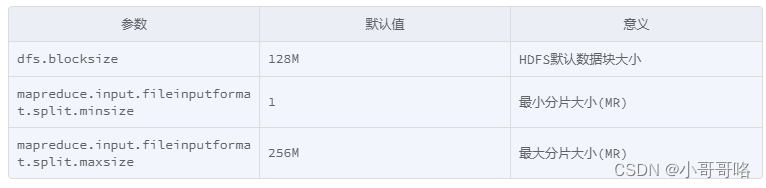
输入分片大小的计算是这么计算出来的:
long splitSize = Math.max(minSize, Math.min(maxSize, blockSize))
输入文件总大小:total_size
HDFS 设置的数据块大小:dfs_block_size # 默认情况下,splitSize 和 dfs_block_size 大小一致
default_mapper_num = total_size / dfs_block_size # MapTask 数量
PS:默认情况下,输入分片大小和 HDFS 集群默认数据块大小一致,也就是默认一个数据块,启用一个MapTask 进行处理,这样做的好处是避免了服务器节点之间的数据传输,提高 job 处理效率
set mapred.map.tasks=10; # 参数值大于 default_mapper_num 的时候才会生效
据上得以下公式,若需要减少 MapTask 数量,设置 minSize 大于blockSize;若需要增加 MapTask 数量,设置 maxSize小于blockSize,或者设置 mapred.map.tasks大于default_mapper_num
default_mapper_num = total_size / Math.max(minSize, Math.min(maxSize, blockSize))
PS:如果想要调整 mapper 个数,在调整之前,需要确定处理的文件大概大小以及文件的存在形式(是大量小文件,还是单个大文件),然后再设置合适的参数。
4.4、合理设置ReduceTask并行度
Hive 的估计机制很弱,不指定ReducerTask 个数的情况下,Hive 会猜测确定一个ReducerTask 个数,基于以下两个设定:
参数1:hive.exec.reducers.bytes.per.reducer (默认256M)
参数2:hive.exec.reducers.max (默认为1009)
参数3:mapreduce.job.reduces (默认值为-1,表示没有设置,那么就按照以上两个参数进行设置)
ReduceTask 的计算公式为:
N = Math.min(参数2,总输入数据大小 / 参数1)
4.5、Join优化
4.5.1、Join优化整体原则:
1、优先过滤后再进行Join操作,最大限度的减少参与join的数据量
2、小表join大表,最好启动mapjoin,hive自动启用mapjoin, 小表不能超过25M,可以更改
3、Join on的条件相同的话,最好放入同一个job,并且join表的排列顺序从小到大:
select a., b., c.* from a join b on a.id = b.id join c on a.id = c.i
4、如果多张表做join, 如果多个链接条件都相同,会转换成一个JOb
能够提前过滤的数据尽量提前过滤掉,减少参加处理的数据量;Hive中进行join的表从左到右一次增大,因为左边的表会被加载进内存,可以有效减少内存溢出的几率;join条件相同的表,会被合并成一个MapReduce Job;尽量避免SQL包含复杂的逻辑,可以使用中间表来实现;某些key对应的数据太多时,可以过滤掉或者进行转换,以使得数据均匀的分布到不同的reducer上;
启用 MapJoin,大表 join 小表,小表满足需求: 小表数据小于控制条件时
--是否自动转换为mapjoin
set hive.auto.convert.join = true;
--小表的最大文件大小,默认为25000000,即25M
set hive.mapjoin.smalltable.filesize = 25000000;
--是否将多个mapjoin合并为一个,减少读写次数
set hive.auto.convert.join.noconditionaltask = true;
--多个mapjoin转换为1个时,所有小表的文件大小总和的最大值
set hive.auto.convert.join.noconditionaltask.size = 10000000;
4.5.2、Sort-Merge-Bucket(SMB) Map Join,这个技术的前提是所有的表都必须是分桶表(bucket)和分桶排序的(sort)。具体实现:
1、针对参与join的这两张做相同的hash散列,每个桶里面的数据还要排序
2、这两张表的分桶个数要成倍数。
3、开启 SMB join 的开关!
# 当用户执行bucket map join的时候,发现不能执行时,禁止查询
set hive.enforce.sortmergebucketmapjoin=false;
# 如果join的表通过sort merge join的条件,join是否会自动转换为sort merge join
set hive.auto.convert.sortmerge.join=true;
# 当两个分桶表 join 时,如果 join on的是分桶字段,小表的分桶数是大表的倍数时,可以启用mapjoin 来提高效率。
# bucket map join优化,默认值是 false
set hive.optimize.bucketmapjoin=false;
# bucket map join 优化,默认值是 false
set hive.optimize.bucketmapjoin.sortedmerge=false;
4.5.3、Join数据倾斜优化
# join的键对应的记录条数超过这个值则会进行分拆,值根据具体数据量设置
set hive.skewjoin.key=100000;
# 如果是join过程出现倾斜应该设置为true
set hive.optimize.skewjoin=false;
如果开启了,在 Join 过程中 Hive 会将计数超过阈值 hive.skewjoin.key(默认100000)的倾斜 key 对应的行临时写进文件中,然后再启动另一个 job 做 map join 生成结果。通过 hive.skewjoin.mapjoin.map.tasks 参数还可以控制第二个 job 的 mapper 数量,默认10000。
4.5.4、CBO优化
Hive 在提供最终执行前,优化每个查询的执行逻辑和物理执行计划。要使用基于成本的优化(也称为CBO),请在查询开始设置以下参数
set hive.cbo.enable=true;
set hive.compute.query.using.stats=true;
set hive.stats.fetch.column.stats=true;
set hive.stats.fetch.partition.stats=true;
4.5.5、笛卡尔积
小表join大表时,使用map join,在 Map 端完成 Join 操作;若不能使用map join 那就使用reduce join,小表增加一列 join key,复制n份,每一份的 join key都不同,接着大表也添加一个 join key,且值域就是小表 join key的值域,这样就会有n个reduce同时处理数据。
4.5.6、Group By优化
Map端部分聚合
# 开启Map端聚合参数设置
set hive.map.aggr=true;
# 设置map端预聚合的行数阈值,超过该值就会分拆job,默认值100000
set hive.groupby.mapaggr.checkinterval=100000
有数据倾斜时进行负载均衡
# 自动优化,有数据倾斜的时候进行负载均衡(默认是false)
# 把 MapReduce 任务拆分成两个:第一个先做预汇总,第二个再做最终汇总
set hive.groupby.skewindata=false;
当选项设定为 true 时,生成的查询计划有两个 MapReduce 任务
1、在第一个 MapReduce 任务中,map 的输出结果会随机分布到 reduce 中,每个 reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的group by key有可能分发到不同的 reduce 中,从而达到负载均衡的目的;
2、第二个 MapReduce 任务再根据预处理的数据结果按照 group by key 分布到各个 reduce 中,最后完成最终的聚合操作
4.5.7、union与union all再group by的性能对比
union写法每两份数据都要先合并去重一次,再和另一份数据合并去重,会产生较多次的reduce
union all再group by的法直接将所有数据合并再一次性去重
4.5.8、Order By优化
在Hive中,关于数据排序,提供了四种语法,一定要区分这四种排序的使用方式和适用场景。
1、order by:全局排序,缺陷是只能使用一个reduce。
2、sort by:单机排序,单个reduce结果有序。
3、cluster by:对同一字段分桶并排序,不能和sort by连用。
4、distribute by + sort by:分桶,保证同一字段值只存在一个结果文件当中,结合sort by保证每个reduceTask结果有序;实现top N:取每一个reduceTask(distribute by + sort by)的Top N到下一个Reduce中完成取全局Top N的目标。
实现全局排序举例:
create table if not exists student(
id int,
name string,
sex string,
age int,
department string)
row format delimited fields terminated by ",";
-- 直接使用order by来做。如果结果数据量很大,这个任务的执行效率会非常低
select id,name,age from student order by age desc limit 3;
-- 使用distribute by + sort by 多个reduceTask,每个reduceTask分别有序
set mapreduce.job.reduces=3;
drop table student_orderby_result;
-- 范围分桶 0 < 18 < 1 < 20 < 2
-- 关于分界值的确定,使用采样的方式,来估计数据分布规律
create table student_orderby_result
as
select * from student
distribute by (case when age > 20 then 0 when age < 18 then 2 else 1 end) sort by (age desc)
4.5.9、Count Distinct优化
当要统计某一列去重数时,如果数据量很大,count(distinct) 就会非常慢,原因与 order by 类似,count(distinct) 逻辑只会有很少的 reducer 来处理。
-- 优化后(启动两个job,一个job负责子查询(可以有多个reduce),另一个job负责count(1)):
select count(1) from (select distinct id from tablename) tmp;
select count(1) from (select id from tablename group by id) tmp; -- 推荐使用这种
4.5.10、优化in/exists语句
-- in / exists 实现;使用left semi join进行优化
select a.id, a.name from a where a.id in (select b.id from b);
select a.id, a.name from a where exists (select id from b where a.id = b.id);
-- 可以使用join来改写,参加join表的所有字段都进入map;使用left semi join进行优化
select a.id, a.name from a join b on a.id = b.id;
-- left semi join 实现,IN/EXISTS 子查询的一种更高效的实现,右表只有on后面的字段进入map
select a.id, a.name from a left semi join b on a.id = b.id;
4.5.11、多重模式
多重插入就是一个非常实用的技能,一次读取,多次插入,有些场景是从一张表读取数据后,要多次利用,这时可以使用 multi insert 语法
FROM from_statement
INSERT OVERWRITE | INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)]
select_statement1 [FROM from_statement]
[INSERT OVERWRITE | INTO TABLE tablename2 [PARTITION (partcol1=val3, partcol2=val4 ...)]
select_statement2 [FROM from_statement]]
说明:
① 一般情况下,单个SQL中最多可以写256路输出,超过256路,则报语法错误。
② 在一个multi insert中:对于分区表,同一个目标分区不允许出现多次;对于未分区表,该表不能出现多次。
③ 对于同一张分区表的不同分区,不能同时有Insert overwrite和Insert into操作,否则报错返回。
示例如下:
create table sale_detail_multi like sale_detail;
from sale_detail
insert overwrite table sale_detail_multi partition (sale_date='2010', region='china' )
select shop_name, customer_id, total_price where .....
insert overwrite table sale_detail_multi partition (sale_date='2011', region='china' )
select shop_name, customer_id, total_price where .....;
-- 成功返回,将sale_detail的数据插入到sales里的 2010 年及2011年中国大区的销售记录中。
from sale_detail
insert overwrite table sale_detail_multi partition (sale_date='2010', region='china' )
select shop_name, customer_id, total_price
insert overwrite table sale_detail_multi partition (sale_date='2010', region='china' )
select shop_name, customer_id, total_price;
-- 出错返回,同一分区出现多次。
from sale_detail
insert overwrite table sale_detail_multi partition (sale_date='2010', region='china' )
select shop_name, customer_id, total_price
insert into table sale_detail_multi partition (sale_date='2011', region='china' )
select shop_name, customer_id, total_price;
-- 出错返回,同一张表的不同分区,不能同时有insert overwrite和insert into操作。
Multi-Group by 是 Hive 的一个非常好的特性,它使得 Hive 中利用中间结果变得非常方便。例如
FROM (SELECT a.status, b.school, b.gender FROM status_updates a JOIN profiles b ON (a.userid = b.userid and a.ds='2019-03-20' )) subq1
INSERT OVERWRITE TABLE gender_summary PARTITION(ds='2019-03-20')
SELECT subq1.gender, COUNT(1) GROUP BY subq1.gender
INSERT OVERWRITE TABLE school_summary PARTITION(ds='2019-03-20')
SELECT subq1.school, COUNT(1) GROUP BY subq1.school;
上述查询语句使用了 Multi-Group by 特性连续 group by 了 2 次数据,使用不同的 Multi-Group by。这一特性可以减少一次 MapReduce 操作。
4.5.12、启用本地抓取
# 默认more
set hive.fetch.task.conversion=more;
请看 hive-default.xml 中关于这个参数的解释:
<property>
<name>hive.fetch.task.conversion</name>
<value>more</value>
<description>
Expects one of [none, minimal, more].
Some select queries can be converted to single FETCH task minimizing latency.
Currently the query should be single sourced not having any subquery and should not have
any aggregations or distincts (which incurs RS), lateral views and joins.
0. none : disable hive.fetch.task.conversion
1. minimal : SELECT STAR, FILTER on partition columns, LIMIT only
2. more : SELECT, FILTER, LIMIT only (support TABLESAMPLE and virtual columns)
</description>
</property>
4.5.13、本地执行优化
Hive 在集群上查询时,默认是在集群上多台机器上运行,需要多个机器进行协调运行,这种方式很好的解决了大数据量的查询问题。但是在 Hive 查询处理的数据量比较小的时候,其实没有必要启动分布式模式去执行,因为以分布式方式执行设计到跨网络传输、多节点协调等,并且消耗资源。对于小数据集,可以通过本地模式,在单台机器上处理所有任务,执行时间明显被缩短。
# 开启本地mr,默认是关闭false。
set hive.exec.mode.local.auto=true;
# 设置local mr的最大输入数据量,当输入数据量小于这个值时采用local mr的方式,默认为134217728,即128M。
# 现在设置其值为50000000,不必为128Mb的整数倍
set hive.exec.mode.local.auto.inputbytes.max=50000000;
# 设置local mr的最大输入文件个数,当输入文件个数小于这个值时采用local mr的方式,默认为4
set hive.exec.mode.local.auto.input.files.max=10;
4.5.14、JVM重用
Hive 语句最终会转换为一系列的 MapReduce 任务,每一个MapReduce 任务是由一系列的 MapTask和 ReduceTask 组成的,默认情况下,MapReduce 中一个 MapTask 或者 ReduceTask 就会启动一个JVM 进程,一个 Task 执行完毕后,JVM 进程就会退出。这样如果任务花费时间很短,又要多次启动JVM 的情况下,JVM 的启动时间会变成一个比较大的消耗,这时,可以通过重用 JVM 来解决。
set mapred.job.reuse.jvm.num.tasks=5;
JVM也是有缺点的,开启JVM重用会一直占用使用到的 task 的插槽,以便进行重用,直到任务完成后才会释放。如果某个 不平衡的job 中有几个 reduce task 执行的时间要比其他的 reduce task 消耗的时间要多得多的话,那么保留的插槽就会一直空闲却无法被其他的 job 使用,直到所有的 task 都结束了才会释放。
根据经验,一般来说可以使用一个 cpu core 启动一个 JVM,假如服务器有 16 个 cpu core ,但是这个节点,可能会启动 32 个mapTask,完全可以考虑:启动一个JVM,执行两个Task 。
4.5.15、并行执行
有的查询语句,Hive 会将其转化为一个或多个阶段,包括:MapReduce 阶段、抽样阶段、合并阶段、limit 阶段等。默认情况下,一次只执行一个阶段。但是,如果某些阶段不是互相依赖,是可以并行执行的。多阶段并行是比较耗系统资源的。
一个 Hive SQL 语句可能会转为多个 MapReduce Job,每一个 job 就是一个 stage,这些 Job 顺序执行,这个在 cli 的运行日志中也可以看到。但是有时候这些任务之间并不是是相互依赖的,如果集群资源允许的话,可以让多个并不相互依赖 stage 并发执行,这样就节约了时间,提高了执行速度,但是如果集群资源匮乏时,启用并行化反倒是会导致各个 Job 相互抢占资源而导致整体执行性能的下降。
启用并行化:
# 可以开启并发执行。
set hive.exec.parallel=true;
# 同一个sql允许最大并行度,默认为8。
set hive.exec.parallel.thread.number=16;
4.5.16、推测执行
在分布式集群环境下,因为程序Bug(包括Hadoop本身的bug),负载不均衡或者资源分布不均等原因,会造成同一个作业的多个任务之间运行速度不一致,有些任务的运行速度可能明显慢于其他任务(比如一个作业的某个任务进度只有50%,而其他所有任务已经运行完毕),则这些任务会拖慢作业的整体执行进度。
为了避免这种情况发生,Hadoop采用了推测执行(Speculative Execution)机制,它根据一定的法则推测出“拖后腿”的任务,并为这样的任务启动一个备份任务,让该任务与原始任务同时处理同一份数据,并最终选用最先成功运行完成任务的计算结果作为最终结果。
# 启动mapper阶段的推测执行机制
set mapreduce.map.speculative=true;
# 启动reducer阶段的推测执行机制
set mapreduce.reduce.speculative=true;
如果用户对于运行时的偏差非常敏感的话,那么可以将这些功能关闭掉。如果用户因为输入数据量很大而需要执行长时间的MapTask或者ReduceTask的话,那么启动推测执行造成的浪费是非常巨大大。
4.5.17、Hive严格模式
所谓严格模式,就是强制不允许用户执行有风险的 HiveQL 语句,一旦执行会直接失败。但是Hive中为了提高SQL语句的执行效率,可以设置严格模式,充分利用Hive的某些特点。
# 设置Hive的严格模式
set hive.mapred.mode=strict;
set hive.exec.dynamic.partition.mode=nostrict;
注意:当设置严格模式之后,会有如下限制:
1、对于分区表,必须添加where对于分区字段的条件过滤
select * from student_ptn where age > 25
2、order by语句必须包含limit输出限制
select * from student order by age limit 100;
3、限制执行笛卡尔积的查询
select a., b. from a, b;
4、在hive的动态分区模式下,如果为严格模式,则必须需要一个分区列式静态分区
4.6、总结
1、资源不够时才需要调优
资源足够的时候,只需要调大一些资源用量
2、业务优先,运行效率靠后
首先实现业务,有多余精力再考虑调优
3、单个作业最优不如整体最优
全局最优
4、调优不能影响业务运行结果
业务正确性最重要(combiner: avg )
5、调优关注点
架构方面
业务方面
开发方面
资源方面














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









