







导读:什么是JVM? JVM涉及哪些知识点?我们需要掌握到什么程度?
JDK & JRE & JVM
讲JVM那就不得不提JDK和JRE了。
JDK: java development kit 翻译:java开发工具包
JRE: java runtime environment 翻译:java运行时环境
JDK是包含JRE的。简单来讲,我们运行一个java程序,只需要有JRE就够了。
但是对于日常开发,由于需要用到一些工具、底层库等,所以通常需要安装JDK。
那么什么是JVM呢?直译过来就是:java虚拟机。
为什么需要JVM?
我们知道,java是一个编译型语言。也就是说,我们编写完java代码程序后,要想运行,首先需要将java代码编译成JVM能够识别的class。然后类加载器再将class加载至JVM中,class最终其实会被转化成00 01 这样的机器码在操作系统上运行。[个人理解]
类的生命周期
一个类从编写到运行,经历了什么?
加载 > 验证 > 准备 > 解析 > 初始化 > 使用 > 卸载
加载 [查找和导入class文件]
- 通过一个类的全限定名获取定义此类的二进制字节流
- 将该字节流代表的静态存储结构转化为方法区的运行时数据结构
- 在Java堆中生成一个java.lang.Class对象,作为对方法区中的这些数据的访问入口
验证 [保证被加载类的正确性]
- 文件格式
- 元数据
- 字节码
- 符号引用
准备
- 为类的静态变量分配内存,并初始化为默认值
解析
- 符号引用转换为直接引用
初始化
- 对类的静态变量、静态代码块执行初始化操作
类加载器
上面讲了类需要先加载。那么加载是由谁来加载的呢?
答案是:类加载器
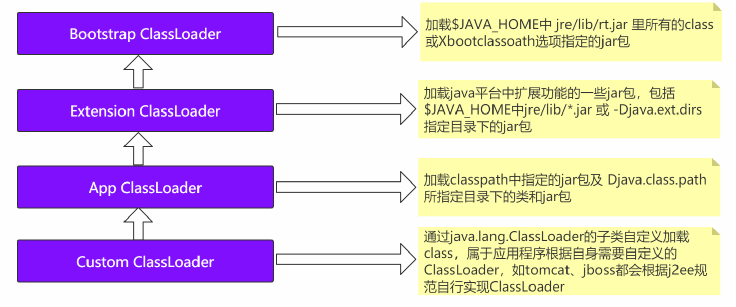
类加载器分类
类加载器分为以下几种:
Bootstrap Classloader
- 负责加载$JAVA_HOME中 jre/lib/rt.jar 里所有的class或Xbootclassoath选项指定的jar包。由C++实现,不是ClassLoader子类
Extension Classloader
- 负责加载java平台中扩展功能的一些jar包,包括$JAVA_HOME中jre/lib/*.jar 或 -Djava.ext.dirs指定目录下的jar包
App Classloader
- 负责加载classpath中指定的jar包及 Djava.class.path 所指定目录下的类和jar包。
Customer Classloader
- 通过java.lang.ClassLoader的子类自定义加载class,属于应用程序根据自身需要自定义的ClassLoader,如tomcat、jboss都会根据j2ee规范自行实现ClassLoader
用一张图总结,如下:
加载原则
检查一个类是否已被加载,从Custom ClassLoader到Bootstrap ClassLoader逐层往上检查,只要某个ClassLoader加载过此类,就视为已被加载,保证此类只被一个ClassLoader加载过一次。
加载的顺序是自顶向下开始加载的。
双亲委派机制
定义: 如果一个类加载器在接到加载类的请求时,它首先不会自己尝试去加载这个类,而是把
这个请求任务委托给父类加载器去完成,依次递归,如果父类加载器可以完成类加载任务,就
成功返回;只有父类加载器无法完成此加载任务时,才自己去加载。
优势: Java类随着加载它的类加载器一起具备了一种带有优先级的层次关系。比如,Java中的
Object类,它存放在rt.jar之中,无论哪一个类加载器要加载这个类,最终都是委派给处于模型
最顶端的启动类加载器进行加载,因此Object在各种类加载环境中都是同一个类。如果不采用
双亲委派模型,那么由各个类加载器自己取加载的话,那么系统中会存在多种不同的Object
类。
破坏: 可以继承ClassLoader类,然后重写其中的loadClass方法,其他方式大家可以自己了解
拓展一下。
运行时数据区
运行时数据区是 java程序运行过程的载体。怎么说呢?程序运行肯定需要内存,运行时数据区就是这里的内存。
当然,对于内存的使用需要合理的划分,运行时数据区的内存划分如下:
方法区
存放class信息、常量、静态变量等信息
堆
内存最大的一块。主要存放java对象
虚拟机栈
线程执行的区域,保存着线程中方法的执行状态。为线程私有。
线程中每个方法即为栈中的一个栈帧。
调用一个方法,就会往栈中压入一个栈帧,调用完成后再弹出
本地方法栈
native方法执行的区域
程序计数器
Java虚拟机中的多线程是通过线程切换轮流执行的,同一时刻,一个cpu只会处理一条线层中的一个指令。为了保证线层切换回来后能正确的接着之前执行的位置继续执行,每个线层需要有一个独立的计数器,记录这上次Java虚拟机执行的字节码的位置。
Java对象的内存布局
我们知道,类加载的时候,是在堆内生成一个java.lang.Class对象,指向方法区中的类信息。
那么,我们程序中new出的对象,怎么知道它属于哪个Class呢?
一个对象在内存中包含3个部分:
对象头、实例数据、对齐填充
对象头
mark world[8字节] 一系列的标记位,包括:分代年龄、锁标志、哈希码
class pointer[8字节] 指向对象对应class的元数据的内存地址
数组长度[4字节] 数组对象持有
实例数据
对象的属性占用空间大小,具体大小由属性决定
对齐填充
填充字节,保证对象大小为8的整数倍

内存模型
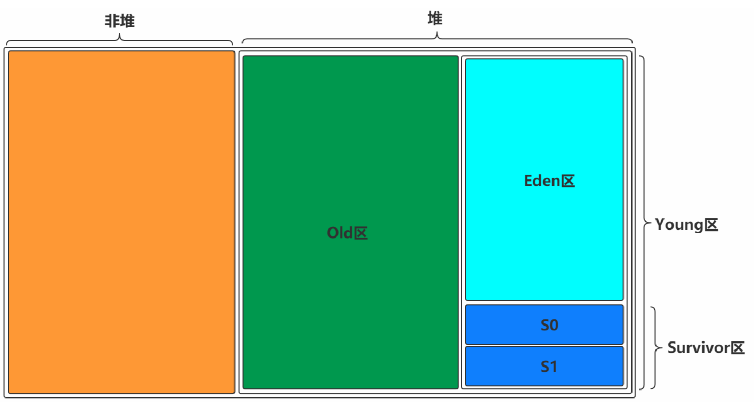
堆分为old区和young区,young区又分为Eden区和Suvior区(s0 + s1)。
为什么堆要划分为老年代和新生代?
程序运行过程中,会不断的new新对象,new出来的对象都会存储在内存中。当内存满了后,就要进行垃圾回收。而对整个堆进行垃圾回收是非常耗性能的一个事,最直观的影响就是,导致业务线程暂停(stw=stop the world)。而程序运行中产生的对象大多有一个特点,就是生命周期非常短,大部分就是方法执行完后,就用不上了。
经过上面的分析,这里把堆分为老年代和新生代其实非常合理。
老年代: 垃圾回收16次仍然存活的对象,这种对象一般业务频繁使用。
新生代: 新分配的对象,首先进入新生代,随着一次次的垃圾回收,对象的年龄不断增长,最终存活下来的对象会进入老年代。
一般老年代和新生代的大小比例为:4:1。新生代的垃圾回收,每次只回收1/4的内存,相对full gc来说,效率很高。
新生代为什么分为eden、s0、s1?
新生代发生gc的频率很高,为了尽可能的提升gc效率不影响业务线程,我们需要高效率的垃圾回收方案。
而新生代的垃圾回收一般都采用 复制算法。 复制算法就意味着需要两块内存,也就产生了s0和s1。
垃圾收集
垃圾对象
在垃圾收集前,我们得先确定什么对象是垃圾。
引用计数法
对于一个对象来说,如果程序中持有该对象的引用,该对象就不是垃圾。
缺点:存在循环引用
比如对象A的属性a=B,对象B的属性b=A,那么,这两个对象就永远无法回收。
可达性分析
从GC ROOT对象开始往下寻找,看某个对象是否可达
什么对象可以作为GC ROOT对象?
那些不能被回收的对象,包括:
垃圾收集器、常量、静态变量、虚拟机栈&本地方法栈的本地变量表(也就是运行中的方法的变量引用的对象)
垃圾收集算法
标记清除算法
- 标记
- 清除
缺点:会产生内存碎片
复制算法
- 内存分为两块
- 标记
- 清除
- 将剩余对象复制到另一块内存中
缺点:内存利用率低
标记整理算法
- 标记
- 清除
- 将剩余对象移动到内存一端
分代收集算法
老年代:标记整理或标记清除算法
新生代:复制算法
垃圾收集器
垃圾收集器是垃圾收集算法的具体实现。
垃圾收集器主要有如下几种:
新生代: Serial、ParNew、Parallel Scavenge
老年代: Serial Old、Parallel Old、CMS
新生代&老年代: G1
下面分别对每种垃圾收集器进行介绍。
Serial
作用于新生代的单线程垃圾收集器。采用复制算法。
ParNew
作用于新生代的多线程垃圾收集器。采用复制算法。
Parallel Scavenge
作用于新生代的多线程垃圾收集器。采用复制算法。和ParNew类似,更注重于吞吐量。
Serial Old
作用于老年代的单线程垃圾收集器。采用标记整理算法。
Parallel Old
作用于老年代的多线程垃圾收集器。采用标记整理算法。
CMS
作用于老年代的多线程垃圾收集器。采用标记清除算法。
缺点:标记清除算法产生内存碎片
G1
作用于新生代和老年代的垃圾收集器。采用标记整理算法。
G1收集器对堆内存做了重新划分,划分为一个个的Region区域。没有了所谓的新生代和老年代。
吞吐量&停顿时间
垃圾回收过程中,会暂停用户线层(stw:stop the world)。对于线上业务来说,如果业务线层暂停导致响应慢,这对用户来说是很不好的用户体验。所以,评判一个垃圾收集器的好坏,主要关注这两个指标。
停顿时间=垃圾回收时,业务暂停的时间
吞吐量=业务运行时间/(业务运行时间+垃圾回收时间)
我是这样理解的:
停顿时间越短就越适合需要和用户交互的程序,良好的响应速度能提升用户体验;
高吞吐量则可以高效地利用CPU时间,尽快完成程序的运算任务,主要适合在后台运算而不需要太多交互的任
务。
如何选择合适的垃圾收集器
官网 :https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/collectors.html#sthref28
-
优先调整堆的大小让服务器自己来选择
-
如果内存小于100M,使用串行收集器
-
如果是单核,并且没有停顿时间要求,使用串行或JVM自己选
-
如果允许停顿时间超过1秒,选择并行或JVM自己选
-
如果响应时间最重要,并且不能超过1秒,使用并发收集器
-
对于G1收集
- (1)50%以上的堆被存活对象占用
- (2)对象分配和晋升的速度变化非常大
- (3)垃圾回收时间比较长
开启垃圾收集器
- 串行
-XX:+UseSerialGC
-XX:+UseSerialOldGC
- 并行(吞吐量优先):
-XX:+UseParallelGC
-XX:+UseParallelOldGC
- 并发收集器(响应时间优先)
-XX:+UseConcMarkSweepGC
-XX:+UseG1GC
JVM实战
JVM参数
-XX参数
使用得最多的参数类型
非标准化参数,相对不稳定,主要用于JVM调优和Debug
- Boolean类型
格式:-XX:[±]
+ 或 - 表示启用或者禁用name属性
比如:-XX:+UseConcMarkSweepGC表示启用CMS类型的垃圾回收器,-XX:+UseG1GC表示启用G1类型的垃圾回器
- 非Boolean类型
格式:-XX=表示name属性的值是value
比如:-XX:MaxGCPauseMillis=500
其他参数
-Xms1000等价于-XX:InitialHeapSize=1000
-Xmx1000等价于-XX:MaxHeapSize=1000
-Xss100等价于-XX:ThreadStackSize=100
查看参数
java -XX:+PrintFlagsFinal -version > flags.txt
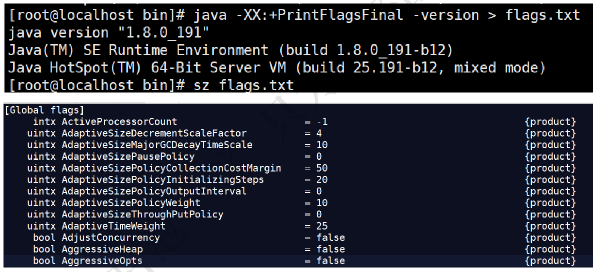
值得注意的是"=“表示默认值,”:="表示被用户或JVM修改后的值。
常用参数含义

常用命令
jps
查看java进程
jps 或 jps -l
jinfo
- 查看和调整JVM配置参数
jinfo -flag name PID 查看PIDjava进程name属性配置的值。示例如下:
jinfo -flag MaxHeapSize PID
jinfo -flag UseG1GC PID
- 修改参数
jinfo -flag [+|-] PID
- 查看曾经赋值过的参数
jinfo -flags PID
jstat
查看JVM性能统计信息
- 查看类装载信息
jstat -class PID 1000 10 查看某个java进程的类装载信息,每1000毫秒输出一次,共输出10次
- 查看垃圾收集信息
jstat -gc PID 1000 10
jstack
查看线层堆栈信息
jstack PID
jmap
生成堆转储快照
- 打印堆内存相关信息
jmap -heap PID
- dump堆内存相关信息
jmap -dump:format=b,file=heap.hprof PID
常用工具
工具的使用,需要平时积累
监控工具
jconsole、jprofile、Arthas
堆分析工具
jprofile、MAT
gc日志分析工具
gceasy、grviewer
JVM调优
其实jvm我们一般只需要设置堆大小、指定垃圾收集器、内存溢出时自动dump堆转储快照、记录gc日志这几步即可,其它交给JVM自动做。示例:
JAVA_OPTS="$JAVA_OPTS -XX:+UseG1GC -Xmx8G -Xms6G -XX:-OmitStackTraceInFastThrow -Dthin.root=/data/app/titan-java-lib/deploy/ -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/data/titan-logs/java/ms-srv/dump -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:/data/titan-logs/java/ms-srv/gc_%t_%p.log"
引申:强、软、弱、虚引用
- 强引用
new出来的对象都是强引用,特点:垃圾回收时,即使内存不足outofmemory,也不回收对象
- 软引用
new SoftRefrense(obj),特点:垃圾回收时,只有在内存不足时,才回收此对象
- 弱引用
new WeakRefrense(obj), 特点:只要发生垃圾回收,不管内存够不够,都回收此对象
- 虚引用
虚引用引用的对象,不论何时,get到的都是null。
那么,它存在的意义是什么呢?
在回收时做一些后续处理的动作,相当于可以对垃圾回收动作增加一个扩展点。
总结
本篇文章介绍了JVM相关的大部分知识,限于能力有限,目前只能总结到此了。对于实战部分,我只简单的列举了一些工具,因为工具的使用只有经过自己动手实践,才能深入理解,剩下的就交给大家自己摸索了!















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









