







深度强化学习cs294 Lecture6: Actor-Critic Algorithms
复习一下上节课的策略梯度算法。主要就是对目标函数的定义以及梯度的计算。还有一些减小方差的方法以及Importance Sampling的方法。
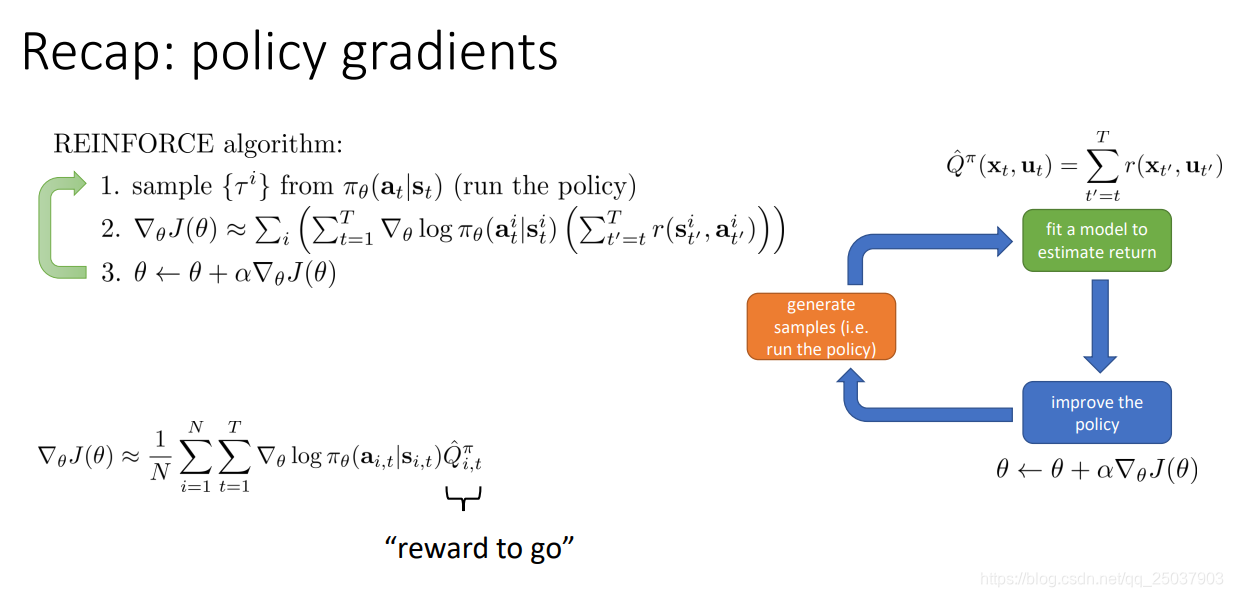
1. Improving the policy gradient with a critic
在公式里从当前开始得到的反馈值之和 Q ^ i , t π \widehat{Q}^{\pi}_{i,t} Q
i,tπ有一个更好的估计方式:
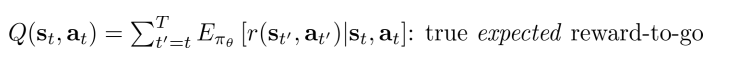
这表示当前状态 s t s_{t} st采取了动作 a t a_{t} at之后后面会得到的所有反馈和的期望值。对应的有一个在当前状态 s t s_{t} st的期望值,就是对Q进行在 a t a_{t} at上求期望:

在policy gradient方法中使用一个常数b作为一个baseline来减小梯度的方差。这里的b就是对Q值的一个平均,那么就可以使用V来替代,而原本的 Q ^ i , t π \widehat{Q}^{\pi}_{i,t} Q
i,tπ也可以用新的期望值 Q π ( s t , a t ) Q^{\pi}(s_{t},a_{t}) Qπ(st,at)替代。这样就得到了两个期望值的差值,我们把这个值叫做advantage函数。

使用了advantage函数的梯度求导,如果advantage函数估计得越准确,那么梯度的方差就会越小。而原来的使用一个序列的反馈值之和减去b的方式,方差更大。不过是一个无偏估计。
因此使用新的期望函数来计算梯度,但是需要计算三个不同的值 Q , V , A Q, V,A Q,V,A比较麻烦,可以看一下它们之间的关系。因为 Q π ( s t , a t )
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2431
2431











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









