







机器学习技法 作业二
1 分别对A和B求导即可,记得其中
f
(
x
)
=
s
i
g
m
o
i
d
(
x
)
f(x)=sigmoid(x)
f(x)=sigmoid(x)的倒数是
f
(
x
)
∗
(
1
−
f
(
x
)
)
f(x)*(1-f(x))
f(x)∗(1−f(x))。选第一个:

2 在第一题的基础上继续求导,选第四个:

3 在鞍回归里被求逆的矩阵为:

所以是NxN。

4 将平方形式的loss对应回max形式的,大致画一下就知道了,稍微麻烦的初等变化。选第三个。
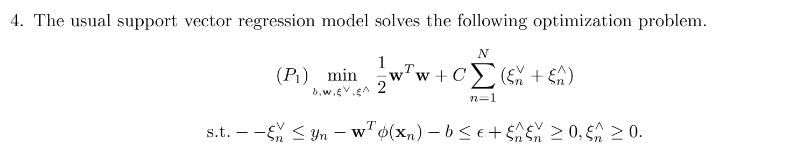

5 对第四题里面的结果进行求导。还是比较繁琐的初等变化。选第一个。

6 几个不同的error表示之间的关系。把
e
t
e_{t}
et式子里的括号展开即可。第三个。

7 第一眼看上去是个理论推导,但没有想出来怎么推。然后写程序模拟了一下得到结果是第三个。

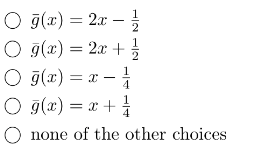
代码如下:
import numpy as np
data = np.random.rand(2,1000)
w = 0
b = 0
for i in range(1000):
w0 = data[0][i]+data[1][i]
b0 = -data[0][i]*data[1][i]
w += w0
b += b0
print(w/1000, b/1000)
8 这题的题目要求看不出是啥意思,大概是说普通的
E
i
n
E_{in}
Ein与题干中的weighted
E
i
n
E_{in}
Ein等同的样例是哪个,第二个。

9 正确率是99%的第一轮之后更新完权重,正负样例的权重比,99。按adaboost权重更新的式子计算一下即可。

10 这题题目看起来有些复杂,不过大致就是用stump函数作为映射函数,观察一些这个设定下的选项。
第一项不对,如果只是一维的stump这一项也不对,多维下更不对。
第二项,取值只能是有范围的整数,因此X是有限的。
第三项是对的。对于每一维来说不同的stump的个数为2*(R-L+1),在这里应该是12。但是多维下不能直接每一维结果乘以维数d,因为每一维里都包含了全正或者全负的分类,是有重复的。如果每一维里去掉全正全负两类,那么就有2*(R-L)个,再乘以维度d,最后加上全正全负两个,在这里就是22的结果。
第四项第一眼看上去是不同维度的分类不应该比较,但实际上 两个都是全正的分类,因此正确。
第五项正确。

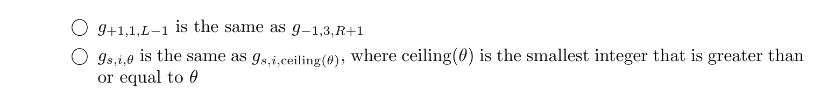
11 接上一题,稍微有些复杂。根据stump作为映射函数得到一个映射后的向量,然后计算内积。把每一项先乘起来,结果为
∑
i
=
1
∣
G
∣
g
i
∗
g
i
\sum_{i=1}^{|G|}g_{i}*g_{i}
∑i=1∣G∣gi∗gi,也就是
∑
i
=
1
∣
G
∣
s
i
g
n
(
x
d
i
m
i
−
θ
i
n
d
e
x
i
)
∗
s
i
g
n
(
x
d
i
m
i
′
−
θ
i
n
d
e
x
i
)
\sum_{i=1}^{|G|}sign(x_{dim_{i}}-\theta_{index_{i}})*sign(x'_{dim_{i}}-\theta_{index_{i}})
∑i=1∣G∣sign(xdimi−θindexi)∗sign(xdimi′−θindexi)。每一项乘积结果为1或-1。因此先假设全为1,再减掉-1对应的个数乘2就是最终的结果。全为1的话结果为
∣
G
∣
|G|
∣G∣,也就是
2
d
(
R
−
L
)
+
2
2d(R-L)+2
2d(R−L)+2,上题里有解释。重点就是-1的项的计算。眼光放到每一个维度上,只有当
θ
\theta
θ取值在x与x‘之间时结果为-1。每个维度都是这样也就是
∣
∣
x
−
x
′
∣
∣
1
||x-x'||_{1}
∣∣x−x′∣∣1这个值。根据stump的特性还要乘以2。而每个-1都抵消了一个1需要再乘以2。结果是第三项。

12 实现一个adaboost,基函数是一个多维的stump。话不多说,实现就完了。代码放在18题后面。选第一项。

13 选第五项。
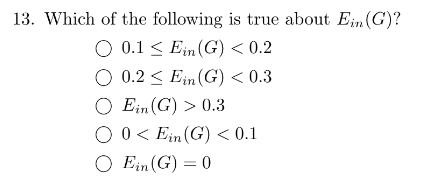
14 第五项

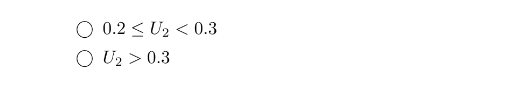
15 第二项。

16 这个选项有点奇怪,应该是0.178
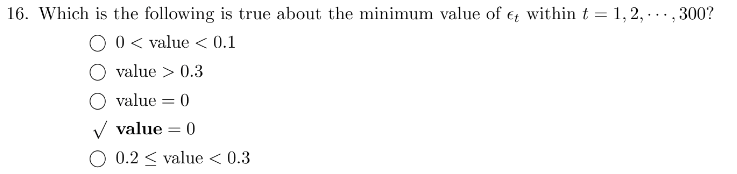
17 0.29

18 0.129
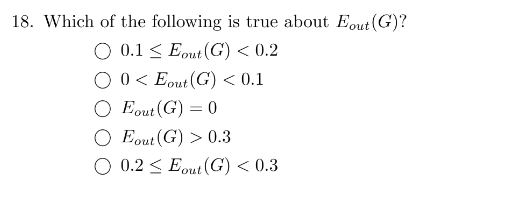
代码:
import numpy as np
def getData(file):
f = open(file)
data = f.readlines()
xs = []
ys = []
for line in data:
d = line.split()
x = np.array([float(d[0]),float(d[1])])
y = float(d[2])
xs.append(x)
ys.append(y)
return np.array(xs),np.array(ys)
def weightedErrorRate(x,y,s,theta,h,dimension,weights):
error = 0
for i in range(len(x)):
if y[i] != h(x[i][dimension],s,theta):
error += weights[i]
return error/np.sum(weights)
def hFunc(x,s,theta):
if s:
return sign(x-theta)
else:
return -sign(x-theta)
def sign(v):
if v < 0:
return -1
else:
return 1
def updateWeights(x,y,s,theta,dim,epsilon,h,weights):
for i in range(len(x)):
if y[i] != h(x[i][dim],s,theta):
weights[i] *= epsilon
else:
weights[i] /= epsilon
def trainDecisionStump(x,y,weights):
dimensions = len(x[0])
E_in = 1
best_s = True
best_theta = 0
best_dim = 0
for dim in range(dimensions):
thetas = np.sort(x[:,dim]) #排序x用来作为备选的theta
ss = [True,False] #先遍历s是正的时候
for theta in thetas:
for s in ss:
E = weightedErrorRate(x,y,s,theta,hFunc,dim,weights)
if E < E_in:
E_in = E
best_s = s
best_theta = theta
best_dim = dim
return best_s,best_theta,best_dim,E_in
def adaboostStump(trainX, trainY, trainFunc, weights, T):
alphas = []
g_funcs = []
min_error = 10000
for i in range(T):
s,theta,dim,error = trainFunc(trainX,trainY,weights)
g_funcs.append([s,theta,dim])
epsilon = np.sqrt((1-error)/error)
alphas.append(np.log(epsilon))
# if i %50 == 49:
# print('iteration:',i+1)
min_error = min(error,min_error)
print('iteration ',i+1,':','sum of weights:',np.sum(weights))
print('error:',error)
updateWeights(trainX,trainY,s,theta,dim,epsilon,hFunc,weights)
print('minimum of error is:',min_error)
return alphas,g_funcs
def applyRes(alphas,g_funcs,h,x):
res = 0
for i in range(len(alphas)):
s,theta,dim = g_funcs[i]
res += alphas[i]*h(x[dim],s,theta)
return sign(res)
def boostedError(alphas,g_funcs,h,x,y):
err = 0
for i in range(len(x)):
if applyRes(alphas,g_funcs,h,x[i]) != y[i]:
err += 1
return err/len(y)
def gError(x,y,h,s,theta,dim):
err = 0
for i in range(len(y)):
if h(x[i][dim],s,theta) != y[i]:
err += 1
return err/len(y)
def main():
trainX, trainY = getData('hw2_adaboost_train.dat')
testX, testY = getData('hw2_adaboost_test.dat')
weights = [1/len(trainY)]*len(trainY)
weights = np.array(weights)
T = 300
alphas,g_funcs = adaboostStump(trainX,trainY,trainDecisionStump,weights,T)
g1_e_in = gError(trainX,trainY,hFunc,g_funcs[0][0],g_funcs[0][1],g_funcs[0][2])
print('E_in of g1:',g1_e_in)
g1_e_out = gError(testX,testY,hFunc,g_funcs[0][0],g_funcs[0][1],g_funcs[0][2])
print('E_out of g1:',g1_e_out)
gt_e_in = boostedError(alphas,g_funcs,hFunc,trainX,trainY)
print('E_in of gT:',gt_e_in)
gt_e_out = boostedError(alphas,g_funcs,hFunc,testX,testY)
print('E_out of gT:',gt_e_out)
if __name__ == '__main__':
main()
19 实现一个核函数下的ridge 回归,直接根据公式计算即可。最好的是0.

20 对应的
E
o
u
t
=
0.39
E_{out}=0.39
Eout=0.39

代码:
import numpy as np
def getData(file):
f = open(file)
data = f.readlines()
xs = []
ys = []
for line in data:
d = line.split()
nums = np.array([float(num) for num in d])
xs.append([1]+nums[:-1])
ys.append(nums[-1])
return np.array(xs),np.array(ys)
def kernel(x1,x2,gamma):
delta = x1-x2
res = np.sqrt(np.sum(delta*delta))
return np.exp(-gamma*res)
def kernelMatrix(X1,X2,gamma):
N = len(X1)
M = len(X2)
K_matrix = np.zeros((N,M))
for i in range(N):
for j in range(M):
K_matrix[i][j] = kernel(X1[i],X2[j],gamma)
return K_matrix
def solveBeta(K,lamda,y):
N = len(K)
iden = np.identity(N)
tmp = np.linalg.inv(K + lamda*iden)
# assert tmp.size == N
# print(tmp.shape)
return tmp.dot(y)
def sign(v):
if v < 0:
return -1
else:
return 1
def errorRate(beta,K,y):
res = K.T.dot(beta)
# print(res.shape)
res = list(map(sign,res))
# print(res.shape)
return np.sum(res!=y)/len(y)
# def main():
X,Y = getData('hw2_lssvm_all.dat')
trainX = X[:400]
trainY = Y[:400]
testX = X[400:]
testY = Y[400:]
gammas = [32,2,0.125]
lamdas = [0.001,1,1000]
best_gamma = 1
best_lamda = 1
best_Ein = 1
best_beta = None
for gamma in gammas:
K = kernelMatrix(trainX,trainX,gamma)
for lamda in lamdas:
beta = solveBeta(K,lamda,trainY)
E = errorRate(beta,K,trainY)
if E < best_Ein:
best_Ein = E
best_gamma = gamma
best_lamda = lamda
best_beta = beta
print('best E_in:',best_Ein)
print('gamma:',gamma,'lamda:',lamda)
K2 = kernelMatrix(trainX,testX,gamma)
Eout = errorRate(beta,K2,testY)
print('E_out:',Eout)














 865
865











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









