







Hybrid Malware Detection Based on Bi-LSTM and SPP-Net for Smart IoT(基于Bi-LSTM和SPP-Net的智能物联网混合恶意软件检测)
这篇文章和物联网关系不大
IEEE Transactions on Industrial Informatics:中科院分区:中科院一区(基础班和升级版均为一区)影响因子IF:9.112,TOP期刊,非OA期刊
名词:: Bi-LSTM:双向长短期记忆
名词:: SPP-Net:空间金字塔池网络
名词:: JSON:JavaScript 对象表示法
JavaScript Object Notation,JSON 教程 | 菜鸟教程
名词:: Shannon entropy:信息熵(香农熵)
名词:: TF-IDF:一种用于信息检索与数据挖掘的常用加权技术
摘要
在本文中,我们提出了具有双向长短期记忆(Bi-LSTM)和空间金字塔池网络(SPP-Net)的混合恶意软件检测方案 HyMalD。其目的是保护物联网 (IoT) 设备,并最大限度地减少混淆恶意软件感染造成的损害。 HyMalD 在逻辑上同时执行静态和动态分析,以检测混淆的恶意软件,而仅使用静态分析是不可能做到的。首先,它使用根据混淆重建的数据集提取操作码序列的静态特征,并动态提取应用程序编程接口(API)调用序列。提取的特征通过 Bi-LSTM 和 SPP-Net 模型进行训练,HyMalD 使用这些模型来检测和分类物联网恶意软件。对HyMalD的性能进行了评估,其检测准确率为92.5%。 HyMalD 的假阴性率为 7.67%。因此,与静态分析相比,HyMalD 能够更准确地检测 IoT 恶意软件,且 FNR 更低,静态分析的检测准确率为 92.09%,FNR 为 9.97%。
文章结构:
- 第一部分:介绍
- 第二部分:介绍恶意软件检测方面的相关研究。
- 第三部分:给出了本研究提出的HyMalD模型的总体方案。
- 第四部分:设计HyMalD模型,
- 第五部分:实现HyMalD模型。
- 第六部分:给出了模型的性能评价结果。
- 第七部分:对本文进行总结。
第一部分 介绍
恶意软件分析技术有三类:静态分析、动态分析和混合分析。在静态分析中,不直接执行文件;相反,逆向工程是针对源代码执行的,从而验证文件的整体结构。这种技术可以快速分析文件,但在检测被打包或加密混淆的恶意软件方面存在困难。另一方面,动态分析直接在沙盒或模拟器等虚拟环境中执行文件,从而监控系统的变化并分析其行为。它检测混淆的恶意软件,因为它分析的是实时行为,但它比静态分析需要更多的时间。最后,混合分析同时利用静态和动态分析来克服两者的缺点。
然而,物联网设备针对特定目的进行了优化,并且是小型化的。因此,它们的硬件规格(例如电池和内存)通常比一般设备更受限制。因此,由于硬件的限制,物联网设备很难对大量恶意软件进行分析和检测。
这篇文章提出混合恶意软件检测基于双向长短期记忆(Bi-LSTM)和空间金字塔池网络(SPP-Net)的分析方法,在嵌套虚拟环境中检测各种恶意软件。根据是否存在混淆,利用分类和重构的数据集,逻辑地同时执行静态和动态分析,以克服静态分析的缺点(检测混淆恶意软件的困难)。HyMalD模型进行静态分析的部分提取操作码序列作为特征,然后由Bi-LSTM模型进行学习。另一方面,HyMalD的动态分析部分通过在嵌套的虚拟环境中执行混淆文件,实时分析和监视与应用程序编程接口(API)调用序列特性相关的行为。大量的API调用序列特征被转换成图像,用于基于深度学习的混淆恶意软件检测。在这里通过在SPP-Net模型中使用各种大小的图像作为输入数据进行训练来检测混淆的恶意软件。
HyMalD通过动态分析提高了静态分析难以检测的模糊恶意软件的检出率。从动态分析中创建的图像的大小不是通过裁剪或调整大小来固定的,从而消除了重要恶意软件功能的任何遗漏或扭曲,因此HyMalD可以检测具有过时操作系统的物联网设备中的混淆恶意软件。
第二部分 相关工作
A. Static Analysis for Malware Detection:介绍两个静态分析检测方法
- Zhu等人提出了DroidDet,用于利用各种类型的静态信息来检测Android恶意软件。DroidDet首先提取4类静态信息,然后利用词频-逆文档频率( TF-IDF )和余弦相似度确定顶层特征。然后利用筛选出的特征通过旋转森林分类器对Android恶意软件进行分类检测。
B. Dynamic Analysis for Malware Detection:介绍两个动态分析检测方法
C. Hybrid Analysis for Malware Detection:介绍三个混合分析检测方法
第三部分 HyMalD模型
本文提出了HyMalD模型,该模型在逻辑上同时执行基于静态和动态分析的恶意软件检测,以检测混淆的恶意软件。HyMalD模型总体方案如下图所示。
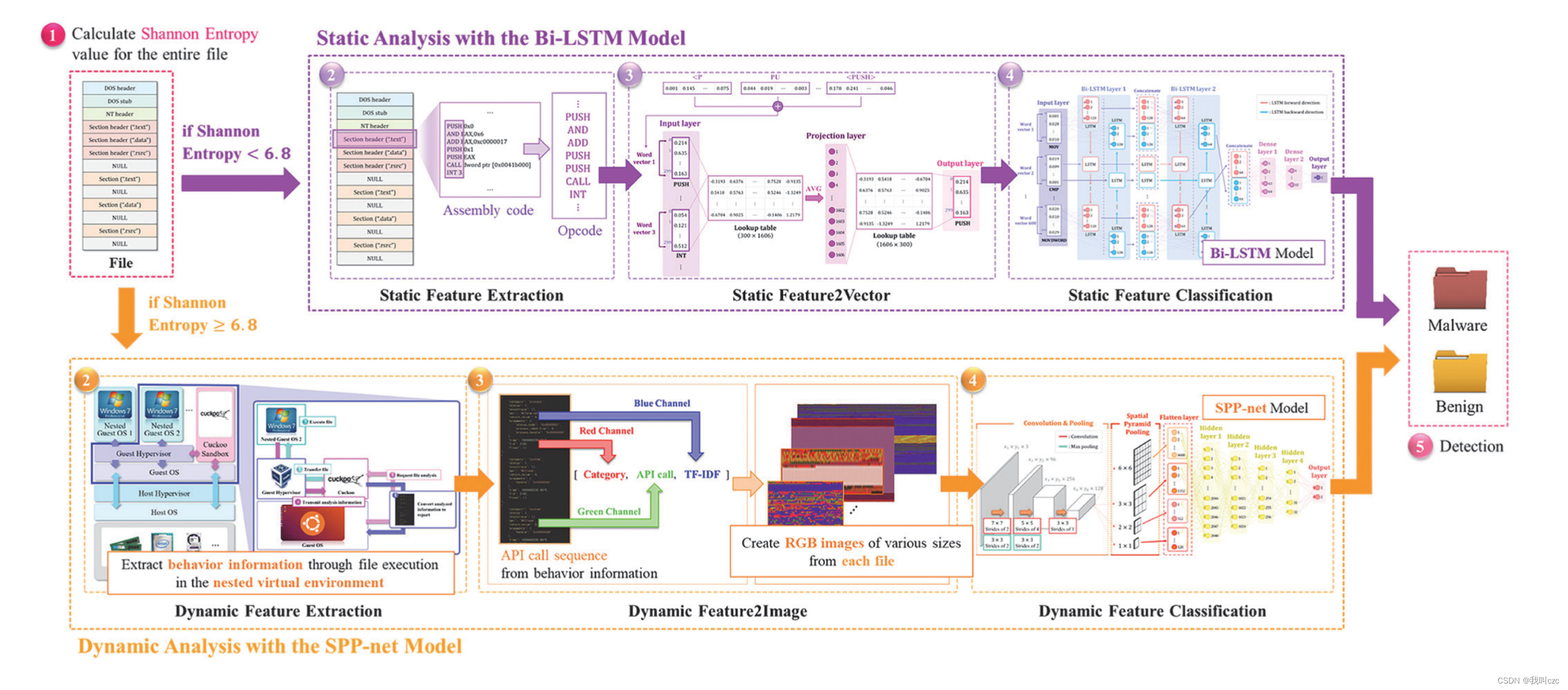

恶意软件的作者喜欢通过使用混淆技术来避免检测,例如压缩,加密或打包。混淆后的恶意软件增加了随机性,从而增加了文件熵。Hy Mal D使用信息熵作为混淆恶意软件的指标。Shannon entropy:信息熵(香农熵)。信息熵计算公式
H
(
x
)
=
−
∑
i
=
1
n
P
(
i
)
×
log
2
P
(
i
)
H(x)=-\sum_{i=1}^nP(i)\times\log_2P(i)
H(x)=−i=1∑nP(i)×log2P(i)
其中P ( i )表示信息发生在第i个块中的概率。计算得到的熵H ( x )的值在0到8之间
本文总结了这篇文献总结的正常熵的范围:( R. Lyda and J. Hamrock, “Using entropy analysis to find encrypted and packed malware,” IEEE Secur. Privacy, vol. 5, no. 2, pp. 40–45, Mar./Apr. 2007.)
,例如,打包的可执行文件的平均熵约为6.8,最高熵约为7.2。相应地,对于数据集重新配置,如果HyMalD中文件的信息熵大于6.8,则确定该文件被混淆。否则,则认为该文件未被混淆。
使用的数据集是KISA-data challenge 2019-Malware.04,由韩国网络安全振兴院提供,其中使用了38166个文件,但文件格式不是可移植可执行文件(PE)的数据除外。根据香农熵值6.8,有23 634个文件被归类为未混淆,14 532个文件被确定为混淆。
重建的数据集在虚拟环境中执行2分钟,并通过布谷鸟沙盒(CuckooSandbox)监控行为并生成报告。一些恶意软件识别出它是在虚拟环境中被分析,没有任何行为,具有这种反调试功能的恶意软件有2623个,作者把它们从数据集中被删除了。
A.采用Bi - Lstm模型的静态分析
使用Bi-LSTM模型的静态分析分析和训练代码语义和文件类型,执行以下三个步骤:静态特征提取、静态特征向量化和静态特征分类。
- 首先,静态特征提取步骤执行反汇编以将机器码转换为汇编代码。转换后的汇编码由一个操作码和一个或多个操作数组成。汇编语言笔记。HyMalD使用操作码作为一个特性。
- 静态特征向量化(feature2vector)步骤执行词嵌入,将操作码序列转换为向量。它使用FastText技术,这个技术使用单词的内部结构来改进向量表示。在FastText技术中,如果存在具有相同基的操作码,例如MOV、MOVSB和MOVSW,它们就有相似的向量。
- 最后,在静态特征分类阶段,使用Bi - LSTM模型对操作码序列进行学习。Bi - LSTM是一种基于上下文进行双向序列分析的深度学习模型。学习速度快,解决了当前LSTM模型中上下文联系不足的问题。
Bi-LSTM的结构如下图所示
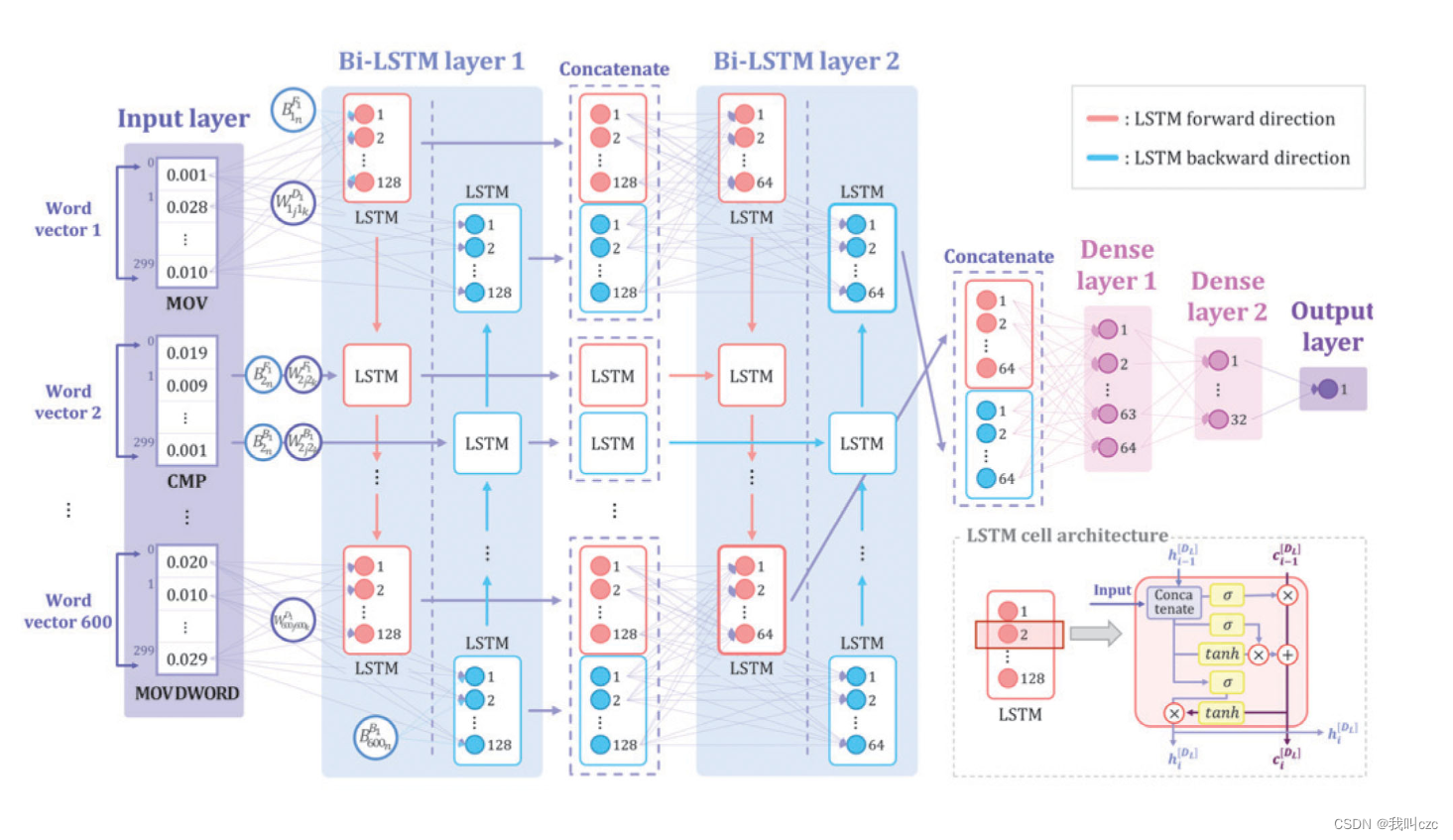
- 向量化的操作码序列的静态特征被用作输入。在Bi - LSTM层中,双向选择重要性高的特征。输出层判断文件是否为恶意软件。
- 使用权重 W i j i k D L W^{D_L}_{{i_j}{i_k}} WijikDL来表示输入层、Bi - LSTM层和输出层中分配给每个值的重要性。偏置 b i n D L b^{D_L}_{i_n} binDL用于防止特定单元中的输出值被偏置到0。
- 使用上一时刻LSTM产生的值 h i − 1 D L h^{D_L}_{i-1} hi−1DL和上一时刻细胞状态值 c i − 1 D L c^{D_L}_{i-1} ci−1DL。在 D L D_L DL中,D是指Bi - LSTM中的网络方向,其中前向和后向分别标记为F和D。L是指层索引。i为当前时刻,j为上一层的索引,k和n为下一层的索引。
采用Bi-LSTM模型进行静态分析,利用18908个训练数据集构建基于静态分析的恶意软件检测模型。共使用2363个验证数据集对所构建的模型进行验证。此外,总共使用了2363个测试数据集来测试模型。为了进行静态特征提取,使用Pydasm(一种基于python的静态分析工具)分析PE文件,并提取操作码。在提取的操作码序列中,重复的操作码被移除(为了避免在某些恶意软件中进行分析,重复了“add”等无意义的操作码)。
根据研究中使用的计算机规格,在将单个文件的操作码序列长度固定为600之后,通过执行静态feature2vector,从操作码序列中为所有数据集生成了一个1607个单词的词汇表,包括<PAD>。在这种情况下,使用了由十个操作码组成的输入层、一个1606维的投影层和一个300维的输出层的FastText结构。
最后,在静态特征分类步骤中,用于恶意软件检测的Bi-LSTM模型具有一个300维嵌入层、两个256维和128维Bi-LSTM层、两个密集层和一个输出层。
Bi-LSTM模型的训练结果对未混淆恶意软件的平均检测准确率为94.12%。验证所建Bi-LSTM模型的准确率为91.90%,测试准确率为91.59%。
B.用SPP-Net模型进行动态分析
SPP - Net模型的动态分析包括动态特征提取、动态特征图像化和动态特征分类。它执行混淆的文件,分析和训练他们的行为。
- 动态特征提取步骤:在嵌套的虚拟环境中执行文件。然后通过Cuckoo Sandbox实时监控网络、进程、文件和注册表中的行为。然后生成JSON格式的报告,并提取API调用序列和有关API调用的信息。
- 动态特征图像化步骤:对API调用序列及其信息进行信道化处理,将特征转换为 RGB 图像。每个通道的高度根据具有固定宽度的文件大小来确定。
- 将API调用相关信息片段之一的类别匹配到红色通道中,将动态特征转换为图像。包括
_ notening _、Certificate、Crypto、File、Network、Process和Register等17个类别,并将其调整为像素值在0 ~ 255之间。 - 将API调用归一化到0到255之间的值,然后匹配到绿色通道中。
- 最后,计算TF - IDF,将每个文件中API调用的重要性表示为一个数值,并与蓝色通道进行匹配。 w i , j = t f i , j × log ( N / d f i ) w_{i,j}=tf_{i,j}\times\log({N}/{df_i}) wi,j=tfi,j×log(N/dfi)其中 w i , j w_{i,j} wi,j,j表示第i个API调用在第j个文件中的重要性, t f i j tf_{i_j} tfij表示第i个API调用在第j个文件中的频率。N表示文件总数, d f i df_i dfi表示包含第i个API调用的文件数。
- 把三个通道的信息通过通道化过程生成的红、绿、蓝RGB图像。
- 将API调用相关信息片段之一的类别匹配到红色通道中,将动态特征转换为图像。包括
- 动态特征分类步骤:利用SPP - Net模型对RGB图像进行训练,从而检测出混淆的恶意软件。下面这张图是SPP - Net模型的结构。在卷积层中计算图像的卷积特征图。SPP层进行各种大小的池化,创建单一的特征向量。利用生成的特征向量将执行恶意行为的文件分类检测为恶意软件。
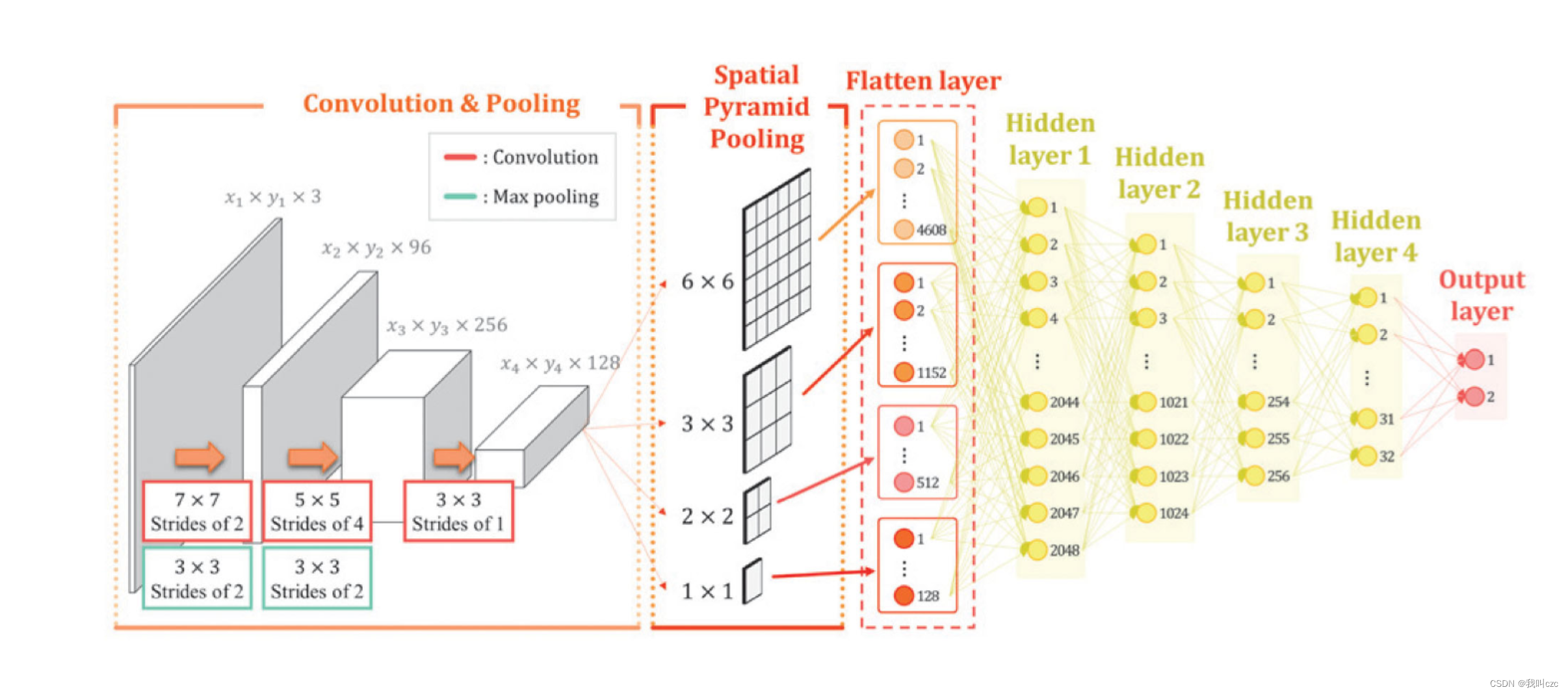
SPP - Net模型通过各种尺寸的特征组成的图像训练,从而防止恶意软件中重要特征的丢失。
将与Bi - LSTM模型的静态分析的结果和与SPP - Net模型的动态分析的结果结合,预测Hy Mal D对恶意软件的检测结果。
动态特征提取获得了显示报告中文件行为的API调用序列。整个数据集有303个API调用类型,API调用序列最长的文件有2818616个API调用。
动态feature2image通过通道化APl调用序列和APl调用的信息来创建RGB图像。生成的图像大小不一,最大的为1024×1325,最小的为32×5。
在动态特征分类中,SPP-Net模型有3个卷积层、2个池化层、4个金字塔层、4个全连接层和1个输出层,利用图像检测被混淆的恶意软件。经过SPP-Net模型的训练,平均准确率为91.23%;而对构建的模型进行验证时,平均准确率为89.93%。进行测试的结果是检测混淆恶意软件的准确率为93.31%。
第四部分 HyMalD设计 没意思,不讲
本文使用杜鹃沙盒(Cuckoo Sandbox)提供的功能(auxiliary, machinery, processing, signature, and reporting modules)来分析和提取虚拟环境中恶意软件的实时行为。此外,设计了HyMalD模型,使用混合分析和深度学习技术对恶意软件进行分析和检测。Sandbox中的辅助模块在虚拟机执行前清理虚拟环境,或者在虚拟机执行时捕获网络流量,起到辅助作用。当杜鹃通过Cuckoo .conf文件运行时,machinery模块管理所有虚拟机的执行和终止。处理模块使用23个模块(包括静态、字符串、procmon、调试和网络)分析从虚拟机收集的行为结果。在签名和报告模块中,将它们结构成可用的数据。签名模块提供各种操作系统的行为模式,并将模式与处理模块中分析的内容进行匹配。最后,报告模块将处理和签名模块生成的分析结果以JSON文件格式存储,并提供给用户。
HyMalD由一个嵌套的虚拟环境、Bi-LSTM的静态分析、SPP-Net的动态分析和一个数据库组成。嵌套虚拟环境为动态分析提供了一个安全的虚拟环境。Bi-LSTM的静态分析包括三个操作:静态特征提取,从静态分析生成的汇编文件中提取操作码序列;Static feature2vector,将提取的操作码序列转换为向量;静态特征分类,通过训练Bi-LSTM模型中矢量化的操作码序列来构建恶意软件检测模型。
SPPNet动态分析中的动态特征提取从生成的报告中提取API调用序列。dynamic feature2image将大量API调用序列转换为图像。然后,动态特征分类通过在SPP-Net模型上训练生成的图像来构建一个混淆的恶意软件检测模型。
HyMalD数据库由包含数据集的文件数据库、包含静态和动态分析提取的特征的特征数据库、包含静态和动态分析综合检测结果的分类结果数据库和存储使用分析技术训练和构建的模型的分类器模型组成。
杜鹃沙盒和HyMalD提供的基础组件相互连接。HyMalD数据库通过命令行界面(CLI)将混淆的恶意软件传输到杜鹃沙盒。嵌套的虚拟环境还可以通过CLI交换杜鹃沙盒的分析信息和命令,以及虚拟环境的管理。此外,使用SPP-Net进行动态分析,从杜鹃沙盒内部的报告模块接收生成的报告,然后提取API调用序列。
第五部分 HyMalD实现
为了检测在移动环境中攻击易受攻击的物联网设备的恶意软件,所提出的 HyMalD 模型在配备 GeForce RTX 2070 和 Intel Core i7-9700K 的系统中实施。此外,还实施了嵌套虚拟环境,以防止恶意软件在运行动态分析时扩散到通过网络连接的其他设备。实现的嵌套虚拟环境配置了 Ubuntu 18.04 中的来宾操作系统和 Windows 7 中的嵌套来宾操作系统。
HyMalD 使用由恶意软件和良性文件组成的数据集来训练和构建模型,以检测使用过时操作系统攻击物联网设备的恶意软件。使用的数据集是韩国互联网安全局提供的 KISA-data Challenge 2019-Malware.04,其中使用了 38 166 个文件,但文件格式不是可移植可执行文件 (PE) 的数据除外。根据香农熵 6.8,有 23 634 个文件被分类为未混淆,有 14 532 个文件被确定为混淆。
A. Bi-LSTM 模型的静态分析
Bi-LSTM 模型的静态分析使用 18 908 个训练数据集来构建基于静态分析的恶意软件检测模型。总共使用 2363 个验证数据集来验证构建的模型。此外,总共使用了2363个测试数据集来测试模型。为了执行静态特征提取,使用基于 Python 的静态分析工具 Pydasm 分析 PE 文件,并提取操作码。提取的操作码序列中的重复操作码已被删除(重复了无意义的操作码,例如“add”,以避免在某些恶意软件中进行分析)。
根据研究中使用的计算机规格,将单个文件的操作码序列长度固定为 600 后,通过执行静态特征2向量,从操作码序列生成包括 < P A D > <PAD> <PAD> 在内的 1607 个单词的词汇表。在本例中,使用了 FastText 结构,该结构具有由 10 个操作码组成的输入层、1606 维投影层和 300 维输出层。
最后,静态特征分类步骤中用于恶意软件检测的 Bi-LSTM 模型具有 1 个 300 维嵌入层、两个 256 维和 128 维 Bi-LSTM 层、两个密集层和一个输出层。
Bi-LSTM 模型的训练结果显示,对于非混淆恶意软件的平均检测准确率为 94.12%。验证所构建的Bi-LSTM模型时准确率为91.90%,测试准确率为91.59%。
B. SPP-Net 模型的动态分析
SPP-Net模型的动态分析使用14 743个样本的数据集构建基于动态分析的恶意软件检测模型,该模型由基于香农熵分类的混淆数据集的14 532个样本和211个样本的数据集组成Bi-LSTM模型静态分析中其操作码序列为0。添加操作码序列为 0 的数据集是因为一些混淆的恶意软件使用对手技术,该技术通过采取添加良性文件字符串或减少打包数据量等操作来减少熵。
重建的数据集在虚拟环境中执行 2 分钟,通过 Cuckoo Sandbox 监控行为并生成报告。某些恶意软件会识别出正在虚拟环境中对其进行分析,因此该行为不会记录在报告中。具有此类反调试功能的恶意软件共有 2623 个,已从数据集中删除。
因此,用于构建模糊恶意软件检测模型的最终数据集有 12 120 个样本,其中 8231 个是恶意软件样本,3889 个是良性样本。 SPP-Net 的动态分析在训练数据集中使用了 9698 个样本进行恶意软件检测,在验证数据集中使用了 1211 个样本,在测试数据集中使用了 1211 个样本。
动态特征提取从报告中获取了展示文件行为的 API 调用序列。整个数据集共有 303 个 API 调用类型,其中 API 调用序列最长的文件有 2 818 616 个 API 调用。
动态 feature2image 通过对 API 调用序列和 API 调用信息进行通道化来创建 RGB 图像。生成的图像大小不一,最大为1024×1325,最小为32×5。
在动态特征分类中,SPP-Net 模型具有 3 个卷积层、2 个池化层、4 个金字塔、4 个全连接层和 1 个输出层,并使用图像检测混淆的恶意软件。
SPP-Net模型的训练结果,平均准确率为91.23%;所建立的模型经过验证,平均准确率为89.93%。进行测试后,混淆恶意软件的检测准确率达到 93.31%。
通过 Bi-LSTM 模型静态分析和 SPP-Net 模型动态分析构建 HyMalD 模型的结果表明,恶意软件检测准确率达到 92.50%。此外,HyMalD 模型将 IoT 恶意软件错误检测为良性的概率为 7.6%,将良性样本检测为恶意软件的概率为 7.2%。
第六部分 绩效评估
在本文中,我们进行了性能评估,以确定 HyMalD 通过同时逻辑地执行静态和动态分析来准确检测混淆的恶意软件。采用以下评价指标对构建的HyMalD模型进行性能评价:准确率、FNR、假阳性率(FPR)。
这三个指标在评价时采用了混淆矩阵。混淆矩阵包含四种类型的信息:真阳性(TP)、真阴性(TN)、假阳性(FP)和假阴性(FN)。 TP、TN、FP 和 FN 分别与预测为恶意软件的实际恶意软件样本数量、预测为良性的良性样本数量、错误预测为恶意软件的良性样本数量以及预测为恶意软件的恶意软件样本数量相关。良性。
普通静态分析与HyMalD的比较

准确率是评价训练后的模型能否准确分类恶意软件的指标;它是使用以下等式测量的:
准确度
A
c
c
u
r
a
c
y
=
(
T
P
+
T
N
)
(
T
P
+
T
N
+
F
P
+
F
N
)
准确度Accuracy = \frac{(TP + TN)}{(TP + TN + FP + FN)}
准确度Accuracy=(TP+TN+FP+FN)(TP+TN)
FNR是被错误预测为良性的恶意软件样本的比率
F
N
R
=
F
N
(
T
P
+
F
N
)
FNR = \frac{FN }{( TP + FN)}
FNR=(TP+FN)FN
FPR是被错误预测为恶意软件的良性样本的比率
F
P
R
=
F
P
(
F
P
+
T
N
)
FPR = \frac{FP }{ ( FP + TN)}
FPR=(FP+TN)FP
HyMalD 模型的性能通过香农熵 6.8、7.0 和 7.2 来测量。基于6.8的HyMalD模型的恶意软件检测准确率为92.50%,高于7.0时的91.46%和7.2时的91.76%。
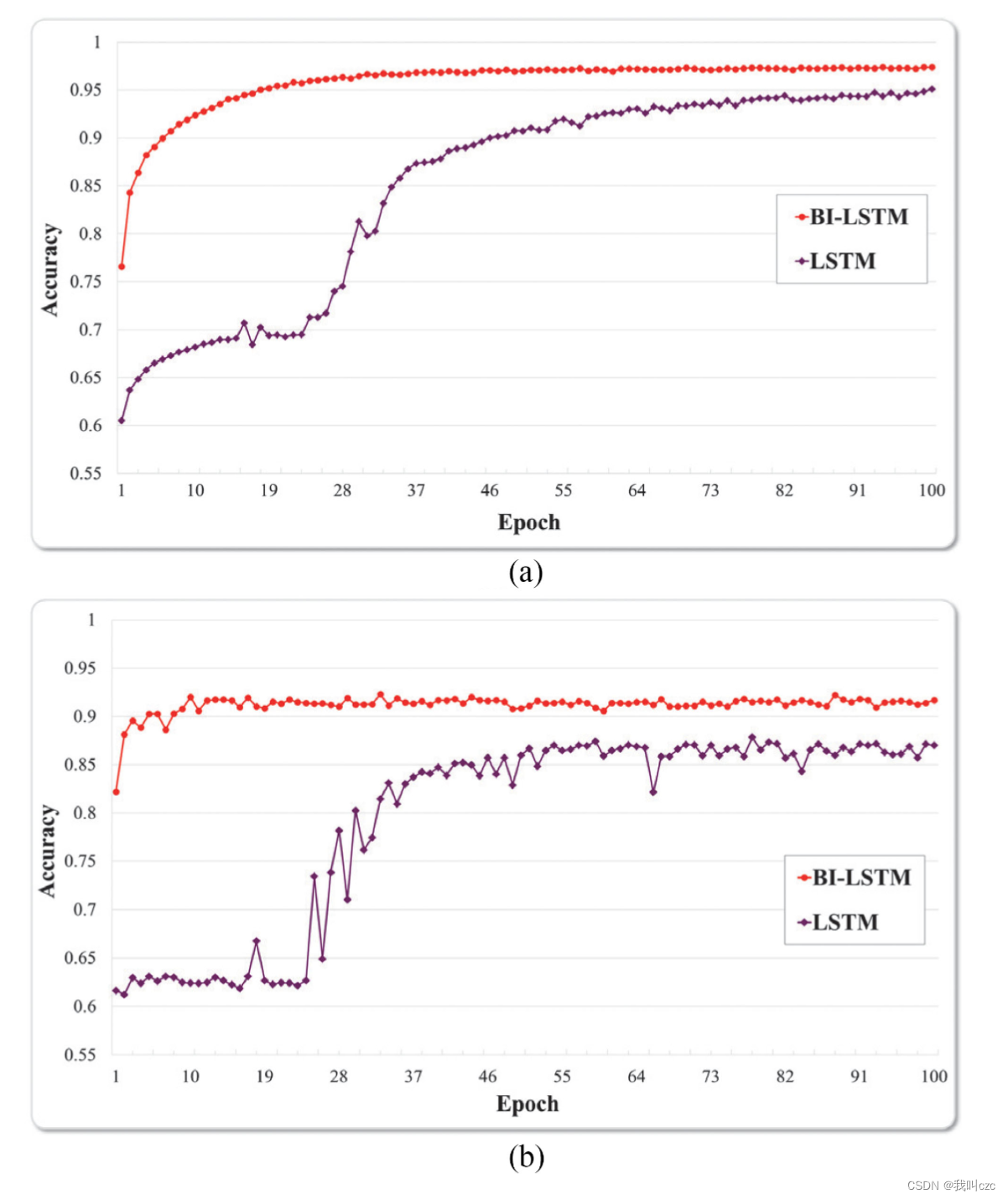
a图表示训练精度,b图表示验证精度
Epoch就是将所有训练样本训练一次的过程。
随着epoch增加,检测精度不断升高,相比LSTM,Bi-LSTM模型更准确地检测出未混淆的恶意软件。
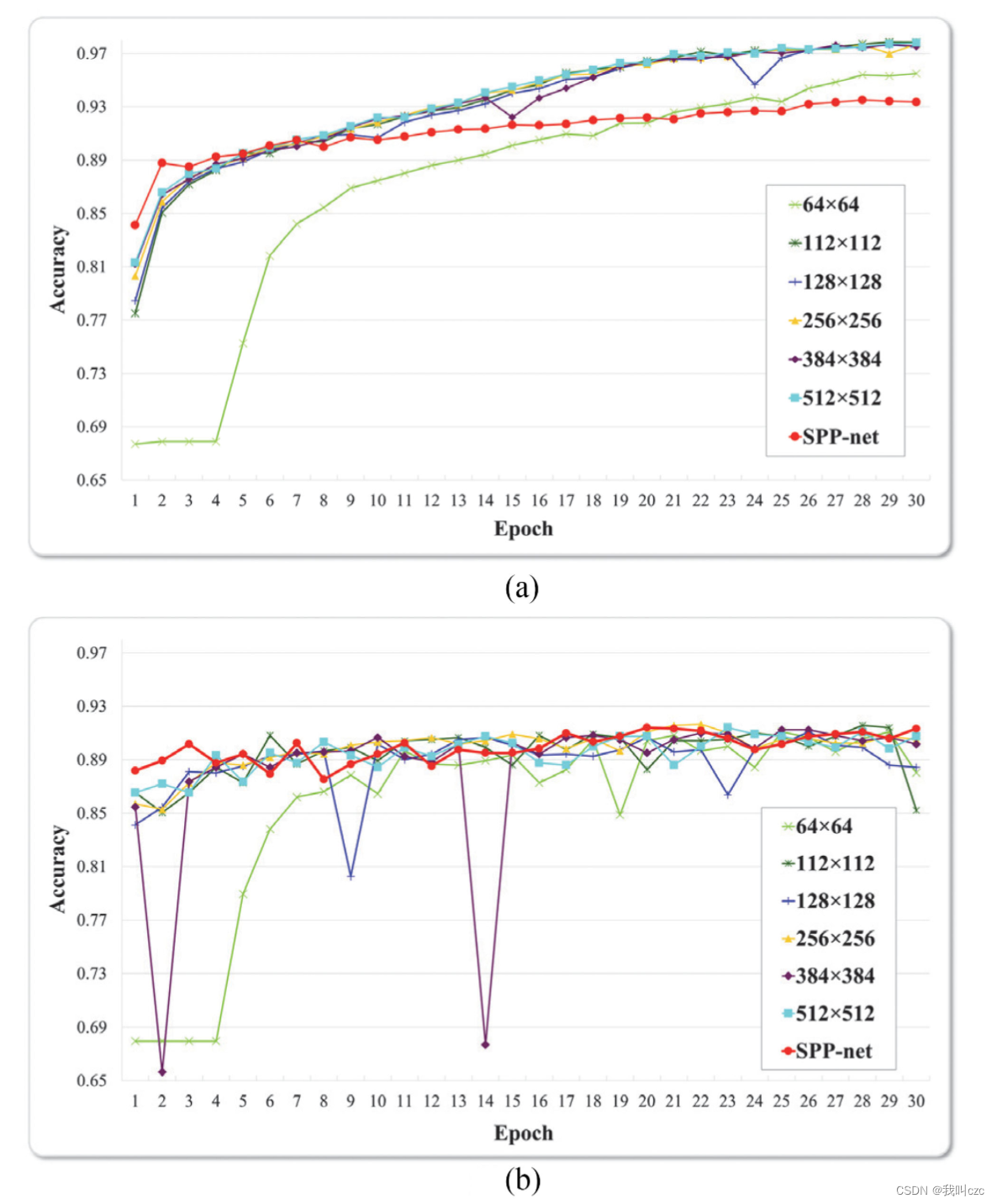
图中显示了使用SPP-Net和CNN模型构建混淆恶意软件检测模型时测量的训练和验证精度。SPP-Net模型有各种大小的图像作为输入。CNN模型只使用单一尺寸的图像作为输入。因此,为了比较SPP-Net和CNN模型的性能,输入到的图像的大小CNN模型为64×64、112× 112、128×128、256×256、384×384和512×512。
图a显示了SPP-Net和CNN模型的训练精度。虽然CNN和SPP-Net模型的准确率随着epoch数的增加而增加。
图b显示了构建的SPP-Net和CNN模型的验证精度。
当图像尺寸为64×64、128×128和384 × 384在CNN模型中,由于模型对训练数据集过拟合,无法准确预测验证数据集,因此在某些部分准确率波动较大。另一方面,SPP-Net模型的验证精度几乎恒定,即使对于越来越多的时代。随着epoch的增加,CNN模型的训练精度和验证精度之间的差距越来越大。CNN模型的测试精度在对于64 × 64、112 × 112、128 × 128、256 × 256、384 × 384和512 × 512的输入图像尺寸,分别为87.28%、84.39%、90.1%、90.3%、90.7%和91.24%。另一方面,SPP-Net模型的测试准确率为93.3%,表明在不固定特征图像尺寸的情况下,其模糊恶意软件的检测效果更好。
第七部分 结论
本文提出了一种 HyMalD 方案,该方案在逻辑上同时执行静态和动态分析,以检测医疗保健行业使用的物联网设备中的恶意软件。 HyMalD 利用香农熵检查样本文件是否被混淆。对混淆文件进行动态分析;对于未混淆的文件,执行静态分析。提取的特征在 Bi-LSTM 和 SPP-Net 模型中进行训练。 HyMalD 的性能评估为 92.5% 准确率和 7.67% FNR,与使用静态分析检测 IoT 恶意软件时的 92.09% 准确率和 9.67% FNR 性能相比,将恶意软件错误预测为良性文件的可能性较小。
某些恶意软件通过添加良性样本中使用的字符串或减少加密数据量等操作来降低熵(通常由于混淆而检测到熵较高)。当香农熵应用于此类恶意软件时,恶意软件由于文件混淆而被错误分类。另一种智能恶意软件会识别何时在虚拟机上运行,然后进行反调试,例如隐藏进程或导致崩溃以阻止虚拟机运行,从而逃避检测。未来的研究将通过进一步分析混淆和反调试技术来改进我们的 HyMalD 模型,以检测当前无法检测到的恶意软件。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









