






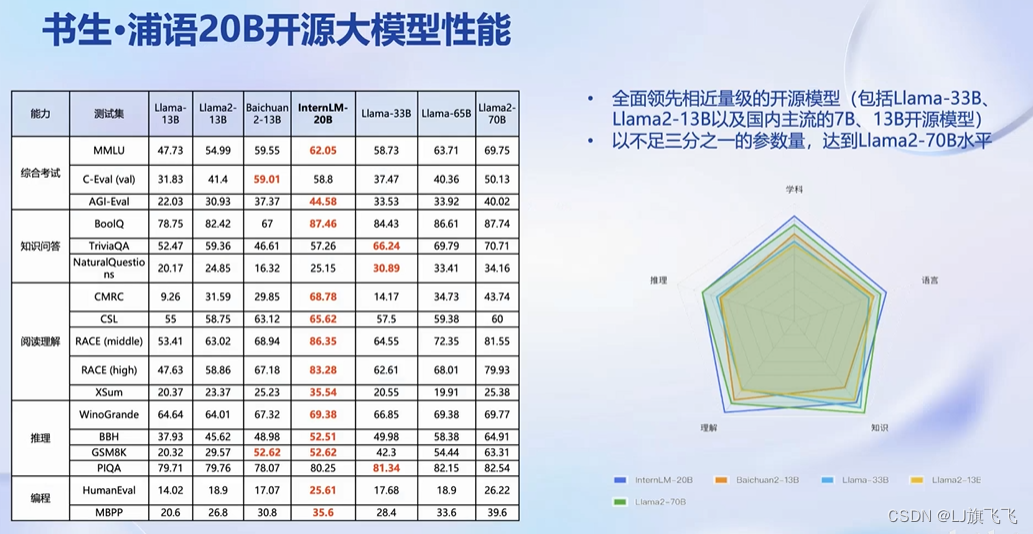
InternLM三个大小

以20B为例–性能
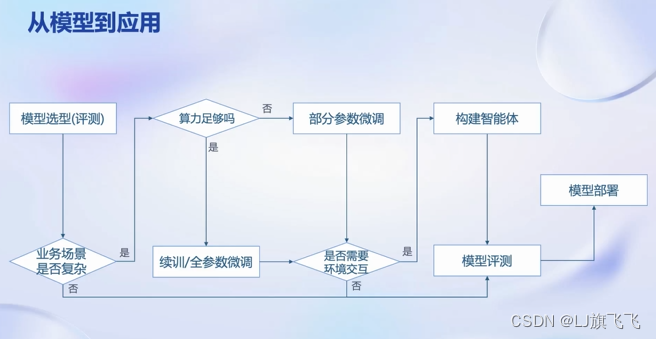
流程
1.首先从开源社区根据不同开源模型在各个维度上的能力选择中意的大模型
2.根据应用场景来判断是否需要对大模型进行参数微调,例如,仅仅是通用的简单对话任务则可以直接使用(至步骤5),如果应用场景比较复杂则需要对模型进行微调。
3.微调:如果算力足够则可以进行续训或全参微调,如果算力有限则可以固定一部分参数,只对部分参数修改进行部分参数微调(例如:LoRA算法)
4.微调后,如果业务场景需要与外部环境交互,例如:调用外部API,或与已有数据库进行交互,则需要构建基于大模型的智能体,如果不需要则可以在业务场景进行试用
5.评测大模型是否符合应用要求,如果符合应用要求则可以进行模型部署,否则则需要重新对模型进行微调,模型部署时也要解决一些问题,例如:以更少的资源部署模型、提升应用吞吐量
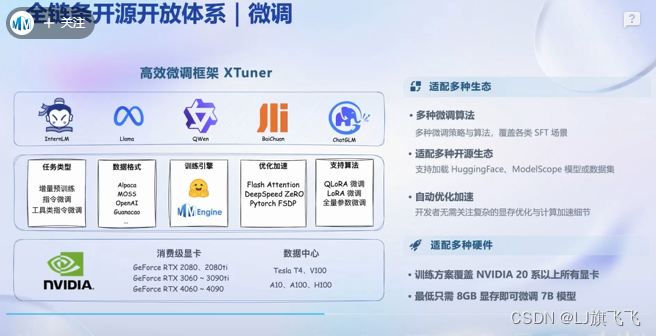
书生浦语全链条开源开放体系

数据
书生万卷开放数据:

OpenDataLab 开放数据平台,提供很多数据

预训练

微调
大语言模型的下游应用中,增量续训和有监督微调是经常会用到两种方式
增量续训使用场景: 让基座模型学习到一些新知识,如某个垂类领域知识训练数据:文章、书籍、代码等
有监督微调使用场景:让模型学会理解和遵循各种指令,或者注入少量领域知识训练数据:高质量的对话、问答数据

XTuner微调框架:8G显存即可微调7B模型
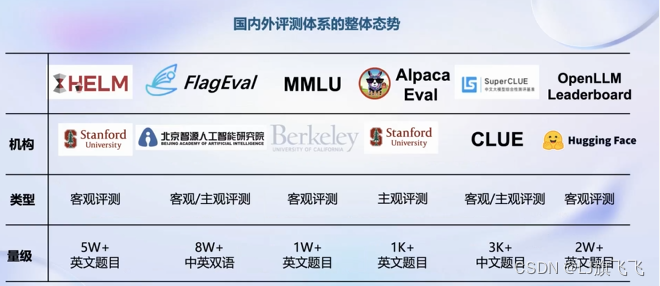
评测
国内外评测体系的整体态势:
OpenCompass评测体系

OpenCompass开源评测平台架构,亮点:
丰富模型支持:开源模型、API模型一站式评测
分布式高效评测:支持千亿参数模型在海量数据集上分布式评测
便捷的数据集接口:支持社区用户根据自身需求快速添加自定义数据集
敏捷的能力迭代:每周更新大模型能力版单,每月提升评测工具能力
部署
为了解决上面大模型的调整,开源了LMDeploy高效的推理框架,LMDeploy 提供大模型在GPU上部署的全流程解决方案,包括模型轻量化、推理和服务。

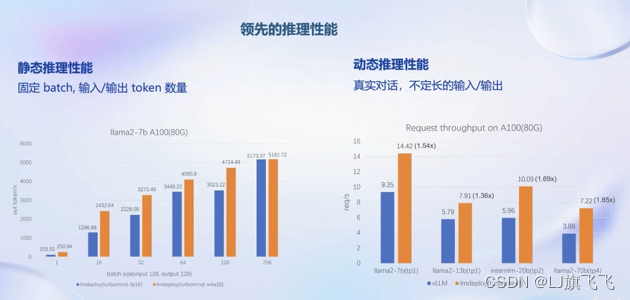
LMDeploy的静态推理性能(固定batch,输入\输出token数量)和动态推理性能(真实对话,不定长的输入\输出)相对其他框架都有一定优势
智能体
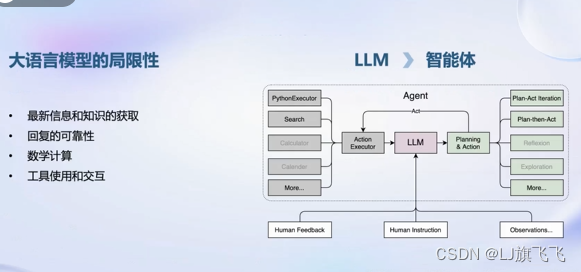
大语言模型的局限性:最新信息和知识的获取、回复的可靠性、数学计算、工具使用和交互。基于这些需求需要让大模型驱动一个智能体,智能体通常以大模型作为核心,来进行一些规划、推理、执行(让大模型自主调用工具)
开源轻量级智能体框架Lagent

举例:1.调用python代码解释器求解数学题,2.多模态AI工具使用
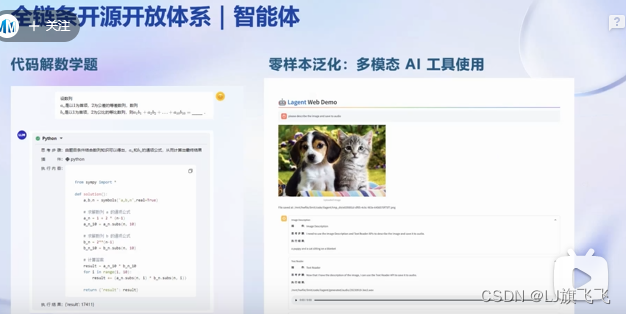
多模态智能体工具箱AgentLego,聚焦在提供给大模型更多的工具集合,在AgentLego加持下,可以更加简单的将大模型与环境连接起来














 1010
1010











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









