








表格形式:
ps第一行需要额外空出来
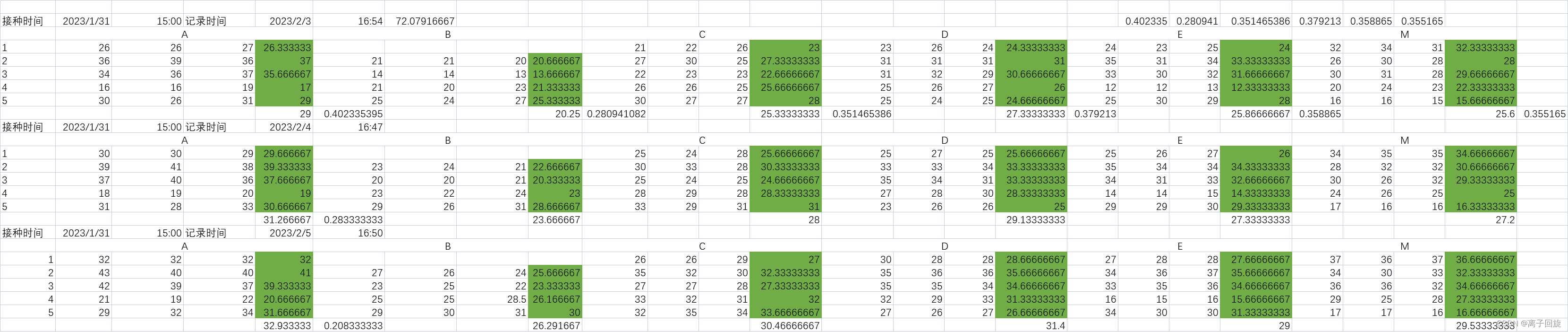
脚本如下:
import pandas as pd
import datetime
#people = pd.read_excel("people.xlsx",header=0,sheet_name="Sheet1")
people = pd.read_excel(r"D:\PersonalFiles\生态中心\博士课题\试验分析和纪录\20230131低温变温继代实验记录.xlsx",header=0,sheet_name="低温变温")
#people.sort_values(by="age",ascending=False,inplace=True)
i=0
StrainLen={"A":{},"B":{},"C":{},"D":{},"E":{},"M":{}}
oldtimemin=datetime.datetime(2023,1,31,15,0)
oldlen = [0,0,0,0,0,0]
while(i<1000):
try:
timeday = people.iloc[i,4:6][0]
timemin = people.iloc[i,4:6][1]
#print(timeday.date())
daytime = datetime.datetime.combine(timeday.date(),timemin)
i += 8
k = 0
for j in StrainLen.keys():
#print(j)
k = k+4
intervalTime = (daytime-oldtimemin).days*24+(daytime-oldtimemin).seconds/3600
intervalLen = people.iloc[i - 1, k] - oldlen[int(k/4-1)]
#print(intervalTime)
StrainLen[j][daytime] = intervalLen/(timemin.hour-9+timemin.minute/60)
oldlen[int(k/4-1)] = people.iloc[i - 1, k]
oldtimemin = daytime
# print(oldtimemin-timemin)
except:
break
speedA,speedB,speedC,speedD,speedE,speedM=[],[],[],[],[],[]
newtable2 = {"time":[]}
newtable = {}
for i in StrainLen["A"]:
newtable[i]=[]
for j in StrainLen.keys():
newtable[i].append([j,StrainLen[j][i]])
for i in sorted(newtable):
newtable2["time"].append(i)
for j in newtable[i]:
if j[0] == "A":
speedA.append(j[1])
elif j[0] == "B":
speedB.append(j[1])
elif j[0] == "C":
speedC.append(j[1])
elif j[0] == "D":
speedD.append(j[1])
elif j[0] == "E":
speedE.append(j[1])
elif j[0] == "M":
speedM.append(j[1])
newtable2["speedA"]=speedA
newtable2["speedB"]=speedB
newtable2["speedC"]=speedC
newtable2["speedD"]=speedD
newtable2["speedE"]=speedE
newtable2["speedM"]=speedM
df = pd.DataFrame(newtable2)
df.set_index("time")
df.to_excel('people.xlsx')


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









