






cs231n——损失函数与优化
损失函数
- 多类别SVM损失函数
- 铰链损失(单个数据点
i
i
i的损失函数
L
i
L_i
Li或数据损失)
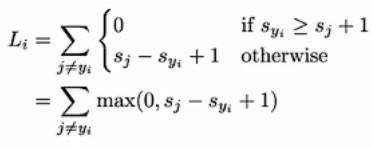
- 使用例子
- s j s_j sj是模型预测的第 j j j类的得分, s y i s_{y_i} syi是模型预测的真实类别 y i y_i yi的得分(即 j j j为其他类, y i y_i yi为想要预测的类)其中得分由 f ( x i , W ) f(x_i,W) f(xi,W)计算
- 使用例子
- 标准损失函数
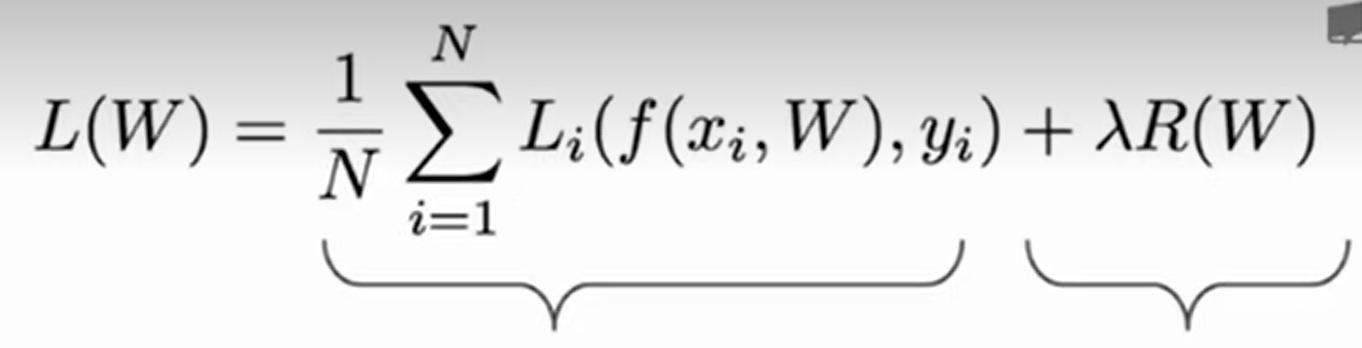
- λ R ( W ) λR(W) λR(W)为正则化项,用于防止模型过拟合
- 正则化
- L1正则化
- λ ∑ ∣ w ∣ \lambda \sum |w| λ∑∣w∣
- L2正则化
- λ ∑ w 2 \lambda \sum w^2 λ∑w2
- L1正则化
- 铰链损失(单个数据点
i
i
i的损失函数
L
i
L_i
Li或数据损失)
- Softmax损失函数

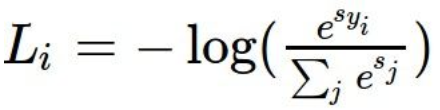
最优化
- 随机搜索
- 每次都进行随机取 w w w
- 随机本地搜索
- 在原有的 w w w上进行改动,若改动后的 w w w能使损失值更低则采用
- 梯度下降
- 概念
- 梯度方向移动指向函数值增加的最快方向,而沿着梯度的负方向移动则指向函数值减小的最快方向
- 目的
- 用于最小化一个函数(通常是损失函数)的值,找到其对应的参数
- 梯度的计算
- 数值梯度法
- 常与解析梯度作比较进行梯度检查
- 使用例子
- 解析梯度法
- 使用微积分(求偏导[链式法则],梯度)
- 数值梯度法
- 选择步长(学习率)
- 在更新参数时,指出在那个梯度下降方向前进多少距离。过大和过小都有问题
- 更新参数
- 根据梯度
∇
L
(
w
old
)
\nabla L(w_{\text{old}})
∇L(wold)和学习率
α
α
α更新参数
w
w
w
- w new = w old − α ∇ L ( w old ) w_\text{new}=w_\text{old}-α\nabla L(w_{\text{old}}) wnew=wold−α∇L(wold)
- 根据梯度
∇
L
(
w
old
)
\nabla L(w_{\text{old}})
∇L(wold)和学习率
α
α
α更新参数
w
w
w
- 随机梯度下降(SGD)
- 在更新参数时,随机选取训练集中的一个样本,而非整个数据集
- 概念
















 815
815











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









