






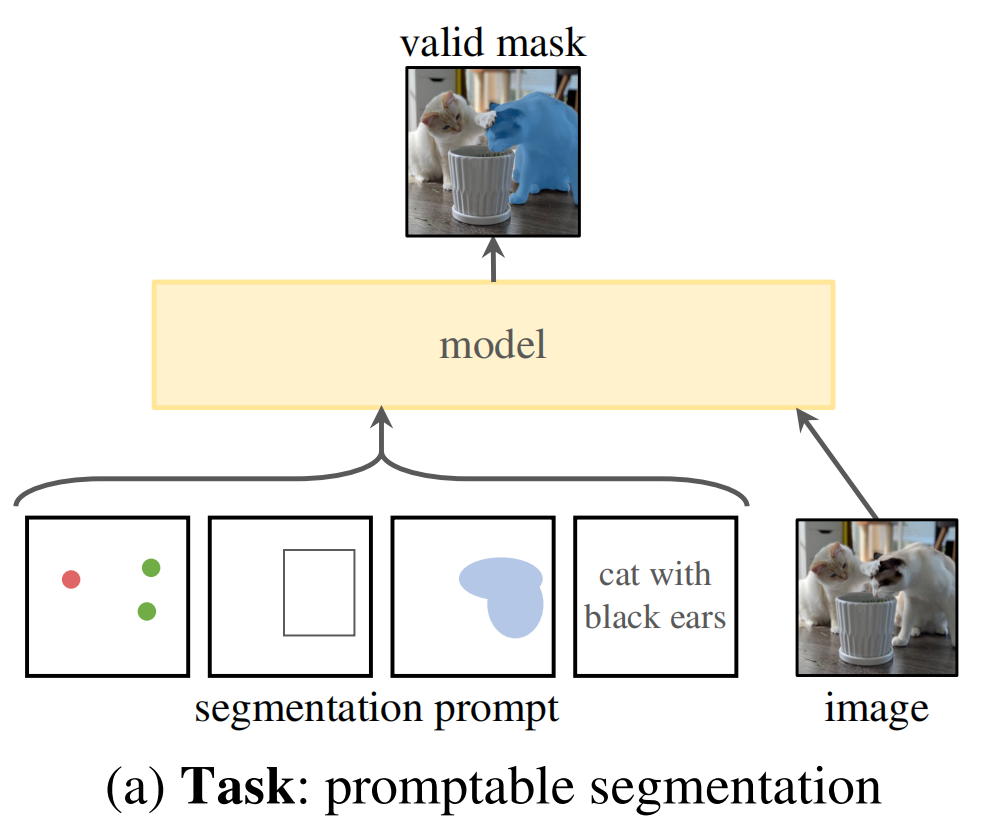
总模型结构
一个prompt encoder,对提示进行编码,image encoder对图像编码,生成embedding, 最后融合2个encoder,再接一个轻量的mask decoder,输出最后的mask。
模型结构示意图:
流程图:

模型的结构如上图所示. prompt会经过prompt encoder, 图像会经过image encoder。然后将两部分embedding经过一个轻量化的mask decoder得到融合后的特征。encoder部分使用的都是已有模型,decoder使用transformer。
image encoder
利用MAE(Masked AutoEncoder)预训练的ViT模型,对每张图片只处理一次,且在prompt encoder之前进行。输入(c,h,w)的图像,对图像进行缩放,按照长边缩放成1024,短边不够就填充,得到(c,1024,1024)的图像,经过image encoder,得到对图像16倍下采样的feature,大小为(256,64,64)。
prompt encoder
prompt encoder结构图:
分为两类:稀疏与密集
稀疏:
point:使用position encodingsbox:使用position encodingstext:使用CLIP作为encoder
密集:
mask:使用卷积作为encoder
mask decoder
- prompt self-attention
- cross-attention(从prompt到image和从image到prompt)
valid mask(模型输出)
- 解决混淆的输入: 对于一个prompt,模型会输出3个mask,实际上也可以输出更多的分割结果,3个可以看作一个物体的整体、部分、子部分,基本能满足大多数情况。使用IOU的方式,排序mask。在反向传播时,参与计算的只有loss最小的mask相关的参数.
- 高效: 这里主要指的是prompt encoder和mask decoder。在web浏览器上,CPU计算只用约50ms
SAM模型复现
环境:
python 3.8.10
pytorch 1.11.0
cuda 11.3
环境安装
git clone https://github.com/facebookresearch/segment-anything
pip install opencv-python matplotlib
pip install -e .
wget https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth #下载SAM_VIT-H模型
定义用于可视化的工具函数
import numpy as np
import torch
import matplotlib.pyplot as plt
import cv2
def show_mask(mask, ax, random_color=False):
if random_color:
color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)
else:
color = np.array([30/255, 144/255, 255/255, 0.6])
h, w = mask.shape[-2:]
mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
ax.imshow(mask_image)
def show_points(coords, labels, ax, marker_size=375):
pos_points = coords[labels==1]
neg_points = coords[labels==0]
ax.scatter(pos_points[:, 0], pos_points[:, 1], color='green', marker='*', s=marker_size, edgecolor='white', linewidth=1.25)
ax.scatter(neg_points[:, 0], neg_points[:, 1], color='red', marker='*', s=marker_size, edgecolor='white', linewidth=1.25)
def show_box(box, ax):
x0, y0 = box[0], box[1]
w, h = box[2] - box[0], box[3] - box[1]
ax.add_patch(plt.Rectangle((x0, y0), w, h, edgecolor='green', facecolor=(0,0,0,0), lw=2))
def show_anns(anns):
if len(anns) == 0:
return
sorted_anns = sorted(anns, key=(lambda x: x['area']), reverse=True)
ax = plt.gca()
ax.set_autoscale_on(False)
img = np.ones((sorted_anns[0]['segmentation'].shape[0], sorted_anns[0]['segmentation'].shape[1], 4))
img[:,:,3] = 0
for ann in sorted_anns:
m = ann['segmentation']
color_mask = np.concatenate([np.random.random(3), [0.35]])
img[m] = color_mask
ax.imshow(img)
可视化原图片
image = cv2.imread('R.jpg')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(14,14))
plt.imshow(image)
plt.axis('on')
plt.show()

原图片:

加载SAM模型
import sys
sys.path.append("..")
from segment_anything import sam_model_registry, SamPredictor
sam_checkpoint = "sam_vit_h_4b8939.pth"
model_type = "vit_h"
device = "cuda"
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)
predictor = SamPredictor(sam)
predictor.set_image(image)
点作为prompt
单点
input_point = np.array([[430, 605]])
input_label = np.array([1])
plt.figure(figsize=(14,14))
plt.imshow(image)
show_points(input_point, input_label, plt.gca())
plt.axis('on')
plt.show()

使用SAM模型进行分割,并输出模型分割出的3个mask
masks, scores, logits = predictor.predict(
point_coords=input_point,
point_labels=input_label,
multimask_output=True, #`multimask_output=True`表示是否输出三个mask结果
)
for i, (mask, score) in enumerate(zip(masks, scores)):
plt.figure(figsize=(14,14))
plt.imshow(image)
show_mask(mask, plt.gca())
show_points(input_point, input_label, plt.gca())
plt.title(f"Mask {i+1}, Score: {score:.3f}", fontsize=18)
plt.axis('off')
plt.show()



多点(使用先前单点输出的mask作为mask prompt)
仅前景点
input_point = np.array([[430, 605],[520, 650]])
input_label = np.array([1, 1]) #1代表前景点(绿色),0代表后景点(红色)
mask_input = logits[np.argmax(scores), :, :] #选择先前分数最高的mask
masks, _, _ = predictor.predict(
point_coords=input_point,
point_labels=input_label,
mask_input=mask_input[None, :, :],
multimask_output=False,
)
plt.figure(figsize=(14,14))
plt.imshow(image)
show_mask(masks, plt.gca())
show_points(input_point, input_label, plt.gca())
plt.axis('on')
plt.show()

前景点+后景点
input_point = np.array([[430, 605],[520, 650], [520,500]])
input_label = np.array([1, 1, 0]) #1代表前景点(绿色),0代表后景点(红色)
mask_input = logits[np.argmax(scores), :, :]
masks, _, _ = predictor.predict(
point_coords=input_point,
point_labels=input_label,
mask_input=mask_input[None, :, :],
multimask_output=False,
)
plt.figure(figsize=(14,14))
plt.imshow(image)
show_mask(masks, plt.gca())
show_points(input_point, input_label, plt.gca())
plt.axis('on')
plt.show()

矩形框作为prompt
单个矩形框
input_box = np.array([730, 105, 1030, 315])
masks, _, _ = predictor.predict(
point_coords=None,
point_labels=None,
box=input_box[None, :],
multimask_output=False,
)
plt.figure(figsize=(17, 17))
plt.imshow(image)
show_mask(masks[0], plt.gca())
show_box(input_box, plt.gca())
plt.axis('on')
plt.show()

多个矩形框(需要使用transform.apply_boxes_torch方法进行转换)
input_boxes = torch.tensor([
[730, 105, 1030, 315],
[970, 155, 1025, 250]
], device=predictor.device)
transformed_boxes = predictor.transform.apply_boxes_torch(input_boxes, image.shape[:2])
masks, _, _ = predictor.predict_torch(
point_coords=None,
point_labels=None,
boxes=transformed_boxes,
multimask_output=False,
)
plt.figure(figsize=(17, 17))
plt.imshow(image)
for mask in masks:
show_mask(mask.cpu().numpy(), plt.gca(), random_color=True)
for box in input_boxes:
show_box(box.cpu().numpy(), plt.gca())
plt.axis('on')
plt.show()

自动分割
from segment_anything import SamAutomaticMaskGenerator
mask_generator = SamAutomaticMaskGenerator(sam)
masks = mask_generator.generate(image)
print(len(masks))
plt.figure(figsize=(20,20))
plt.imshow(image)
show_anns(masks)
plt.axis('on')
plt.show()
输出mask数量
178

开始调参
mask_generator_2 = SamAutomaticMaskGenerator(
model=sam,
points_per_side=32,
pred_iou_thresh=0.86,
stability_score_thresh=0.92,
crop_n_layers=1,
crop_n_points_downscale_factor=2,
min_mask_region_area=100,
)
masks_2 = mask_generator_2.generate(image)
print(len(masks_2))
plt.figure(figsize=(20,20))
plt.imshow(image)
show_anns(masks_2)
plt.axis('on')
plt.show()
输出mask数量
335















 810
810











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









