







1.线程
一个进程中至少包含一个线程,如果只有一个线程,那该线程为程序本身。线程有时也被称为轻量进程(lightweight process,LWP),是程序执行的最小单元。
线程往往比进程运用更广泛。
线程的特点如下:
- 线程是进程中的一个实体,是被系统独立调度和分派的基本单元,线程自己不拥有系统资源,只拥有一点在运行中必不可少的资源,但它可与属于统一进程的其他线程共享进程所拥有的全部资源。
- 一个线程可以创建和撤销另一个线程,同一进程中的多个线程之间可以并发执行。
- 线程是程序中一个单一的顺序控制流程。进程内有一个相对独立的、可调度的执行单元,是系统独立调度和分派CPU的基本单位指令运行时的程序的调度单位。
- 在单个程序中同时运行多个线程完成不同的工作,称为多线程。
由于线程之间的相互制约,致使线程在运行中呈现出间断性。线程有就绪、阻塞和运行三种基本状态
- 就绪状态是指线程具有运行的所有条件,逻辑上可以运行,在等待处理机调度。
- 运行状态是指线程占用处理机正在执行。
- 阻塞状态是指线程在等待一个事件(如某个信号量),逻辑上不可执行。
见例程:
def thread_test(param):
print("[TEST]:%s is running,pid:%s" %(threading.currentThread().name,os.getpid()))
cnt = 0
while cnt < param:
cnt += 1
print("[TEST]:%s cnt:%s" %(threading.current_thread().name,cnt))
time.sleep(1)
if __name__ == '__main__':
print("%s is running,pid:%s" %(threading.currentThread().name,os.getpid()))
t = threading.Thread(target=thread_test, name='test_thread' ,args=(5,)) #创建一个线程,线程名字为test_thread。
print("thread start")
t.start()
print("wait thread end")
t.join()
print("thread end")结果:

可以看到,线程在被创建好之后是一个就绪状态,并没有开始执行,在调用了start()之后,线程才开始执行。而调用join()后,主任务阻塞等待线程运行完成。 此外,在主进程和线程中都打印了进程ID,发现ID是相同的,都是11716.说明线程使用的是进程的资源。
threading.current_thread().name方法会返回该线程的名字,如果该线程在创建的时候没有设置名字,则默认为Thread-1、Thread-2........
这里有一个小细节需要注意。请看如下创建线程代码。
def thread_test():
print("[TEST]:%s is running,pid:%s" %(threading.currentThread().name,os.getpid()))
cnt = 0
while cnt < 5:
cnt += 1
print("[TEST]:%s cnt:%s" %(threading.current_thread().name,cnt))
time.sleep(1)
if __name__ == '__main__':
print("%s is running,pid:%s" %(threading.currentThread().name,os.getpid()))
t = threading.Thread(target=thread_test(), name='test_thread') #创建一个线程,线程名字为test_thread。
print("thread start")
t.start()
print("wait thread end")
t.join()
print("thread end")结果如下:

可以看到,在创建完线程后,线程自动启动了,并且主程序阻塞了。另外创建的线程名字并不是设置的“test_thread”。
主要是因为在创建线程的时候,target参数多了一个(),此时系统会认为这不是一个线程,而是一个任务,就去调用,从而阻塞主程序。所以,在创建线程的时候一定要注意,target参数是不带()的。
2.多线程
为什么要使用多线程
- 线程在程序中是独立的,并发的执行流。与分隔的进程相比,进程中线程之间的隔离程度要小,它们共享内存,文件句柄和其他进程应有的状态。
- 线程的划分尺度小于进程,使得多线程程序的并发性高。进程在执行过程之中拥有独立的内存单元,而多个线程共享内存,从而极大的提升了程序的运行效率
- 线程比进程具有更高的性能,这是由于同一个进程中的线程都有共性,多个线程共享一个进程的虚拟空间。线程的共享环境包括进程代码段、进程的共有数据等,利用这些共享的数据,线程之间很容易实现通信。
多线程的优点
- 进程之间不能共享内存,但线程之间共享内存非常容易
- 操作系统在创建进程时,必须为该进程分配独立的内存空间,并分配大量的相关资源,但创建线程则简单得多。因此,使用多线程来实现并发比使用多进程的性能要高得多。
- Python内置了多线程功能支持,而不是单纯地作为底层操作系统的调度方式,从而简化了Python的多线程编程。
见例程:
def thread_test(param):
print("[%s]:running,pid:%s" %(threading.currentThread().name,os.getpid()))
cnt = 0
while cnt < param:
cnt += 1
print("[%s]:cnt:%s" %(threading.current_thread().name,cnt))
if __name__ == '__main__':
print("%s is running,pid:%s" %(threading.currentThread().name,os.getpid()))
t1 = threading.Thread(target=thread_test, name='test_thread1' ,args=(10,)) #创建一个线程,线程名字为test_thread1。
t2 = threading.Thread(target=thread_test, name='test_thread2', args=(10,)) # 创建一个线程,线程名字为test_thread2。
t3 = threading.Thread(target=thread_test, name='test_thread3', args=(10,)) # 创建一个线程,线程名字为test_thread3。
t1.start()
t2.start()
t3.start()
t1.join()
t2.join()
t3.join()
print("thread end")结果:

这里创建了三个线程,线程名为test_thread1、test_thread2、test_thread3.运行的内容都是一样的。可以看到,三个任务是穿插着在运行,“并行”运行。
线程间的数据共享
已知进程见的数据是没办法共享的,那线程如何呢?见如下代码:
g_count = 1000
def thread_test(param):
global g_count
print("[%s]:running,pid:%s" %(threading.currentThread().name,os.getpid()))
cnt = 0
while cnt < param:
g_count -= 1
cnt += 1
print("[%s]:cnt:%s,g_cnt:%s" %(threading.current_thread().name,cnt,g_count))
def thread_test3(param):
print("[%s]:running,pid:%s" %(threading.currentThread().name,os.getpid()))
cnt = 0
while cnt < param:
cnt += 1
print("[%s]:cnt:%s,g_cnt:%s" %(threading.current_thread().name,cnt,g_count))
if __name__ == '__main__':
print("%s is running,pid:%s" %(threading.currentThread().name,os.getpid()))
t1 = threading.Thread(target=thread_test, name='test_thread1' ,args=(10,)) #创建一个线程,线程名字为test_thread1。
t2 = threading.Thread(target=thread_test, name='test_thread2', args=(10,)) # 创建一个线程,线程名字为test_thread2。
t3 = threading.Thread(target=thread_test3, name='test_thread3', args=(10,)) # 创建一个线程,线程名字为test_thread3。
t1.start()
t2.start()
t3.start()
t1.join()
t2.join()
t3.join()
print("thread end")结果:

可以看到,线程3打印的数据,在随着线程1和2的操作在不断变化,说明,全局变量在线程之间是共享的。
3.线程锁
因为一个全局变量可以被所以线程共享使用,那就无可避免的会出现抢占使用的情况。比如A线程正在调用函数进行数据计算,计算到一半,此时线程B进入,开始进行数据计算。那当调度器再次回到A这边的时候,其中的变量已经发生了改变,那么最终计算出来的结果也就是异常的。
见如下代码:
def thread_test(param):
global g_count
print("[%s]:running,pid:%s" %(threading.currentThread().name,os.getpid()))
cnt = 0
while cnt < param:
value_cal(cnt)
cnt += 1
if __name__ == '__main__':
print("%s is running,pid:%s" %(threading.currentThread().name,os.getpid()))
t1 = threading.Thread(target=thread_test, name='test_thread1' ,args=(1000000,)) #创建一个线程,线程名字为test_thread1。
t2 = threading.Thread(target=thread_test, name='test_thread2', args=(1000000,)) # 创建一个线程,线程名字为test_thread2。
t1.start()
t2.start()
t1.join()
t2.join()
print("thread end")
print("g_count:%d" % g_count)结果:

可以看到,在调用函数时,只是进行加减相同的数。那么理论上最终结果是跟原来的数据相同。而目前计算出来的结果确实一个负值。原因就是线程之间没有进行锁保护,导致在多线程同时使用函数时,变量变化异常导致的。
为了解决这个问题,Python内置了Lock模块。该模块将会产生一个锁,在锁有效的情况下,其他线程是无法调用被保护的代码段。以此来解决重复调用的问题。
acquire()是Python中线程模块的Lock类的内置方法。此方法用于获取锁,阻塞或非阻塞。
函数原型:
def acquire(self, blocking: bool = ..., timeout: float = ...) -> bool: ...参数:
blocking:可选参数,用于阻塞标志。如果设置为True,调用线程将在其他线程持有该标志时被阻塞。一旦该锁被释放,调用线程将获取该锁并返回True。如果设置为False,如果其他线程已获取锁,则不会阻塞该线程,并返回False。
timeout:可选参数。表示阻塞线程的超时时间,单位为秒。默认为-1.
如果没有参数的情况下,会阻塞调用的线程,直到被解锁。
见如下代码:
g_count = 1000
lock = threading.Lock()
def value_cal(n):
global g_count
lock.acquire(True)
try:
g_count += n
g_count -= n
finally:
lock.release()
def thread_test(param):
global g_count
print("[%s]:running,pid:%s" %(threading.currentThread().name,os.getpid()))
cnt = 0
while cnt < param:
value_cal(cnt)
cnt += 1
# print("[%s]:cnt:%s,g_cnt:%s" %(threading.current_thread().name,cnt,g_count))
if __name__ == '__main__':
print("%s is running,pid:%s" %(threading.currentThread().name,os.getpid()))
t1 = threading.Thread(target=thread_test, name='test_thread1' ,args=(1000000,)) #创建一个线程,线程名字为test_thread1。
t2 = threading.Thread(target=thread_test, name='test_thread2', args=(1000000,)) # 创建一个线程,线程名字为test_thread2。
t1.start()
t2.start()
t1.join()
t2.join()
print("thread end")
print("g_count:%d" % g_count)结果:
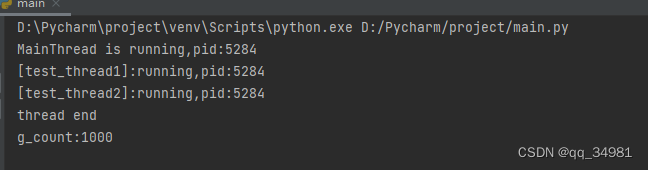
可以看到,在加了锁之后,程序的结果就是我们预期的结果。
当多个线程同时执行lock.acquire()时,只有一个线程能成功地获取锁,然后继续执行代码。其他线程将会阻塞等待,直到获取到锁为止。
锁的好处就是确保了某段代码只能由一个线程从头到尾完整地执行。坏处就是阻止了多线程并发执行,效率降低了。此外,如果锁没有被及时释放,可能会导致死锁。
注:在调用acquire后,一定要调用release进行释放,否则线程会一直阻塞,最终造成程序死锁。只能通过系统强制终止。
4.多线程变量管理
在使用多线程的情况下,每个线程都有自己的数据需要使用。如果所有线程都使用全局变量的话,那么所有在调用全局变量的地方都需要加上锁。这样对于整个程序运行来说无疑会增加过多的负担。那如果使用局部变量的话,在每个函数调用的时候,变量都需要作为传参传入到函数中。这样传递起来也很麻烦。所以,Python提供了ThreadLocal模块。
threading.local()会产生一个全局变量,任意一个线程都可以调用。但是每个线程调用这个变量后,就变成了局部变量。对于其他线程来说是不可更改的。
见如下代码:
local = threading.local()
def value_cal(n):
if n == 0:
local.abs -= 1
else:
local.abs += 1
def thread_test(param):
print("[%s]:running,pid:%s" %(threading.currentThread().name,os.getpid()))
cnt = 0
local.abs = 1000
while cnt < param:
value_cal(0)
cnt += 1
print("[%s]:g_count:%d" % (threading.currentThread().name,local.abs))
def thread_test2(param):
print("[%s]:running,pid:%s" %(threading.currentThread().name,os.getpid()))
cnt = 0
local.abs = 1000
while cnt < param:
value_cal(1)
cnt += 1
print("[%s]:g_count:%d" % (threading.currentThread().name,local.abs))
if __name__ == '__main__':
print("%s is running,pid:%s" %(threading.currentThread(),os.getpid()))
t1 = threading.Thread(target=thread_test, name='test_thread1' ,args=(100,)) #创建一个线程,线程名字为test_thread1。
t2 = threading.Thread(target=thread_test2, name='test_thread2', args=(100,)) # 创建一个线程,线程名字为test_thread2。
t1.start()
t2.start()
t1.join()
t2.join()
print("thread end")结果:

可以看到,两个线程都使用了local.abs这个变量,并且在调用中也都对这个变量进行了操作。但是最终是local.abs变量与线程向对应。并没有被另外一个线程所影响。
全局变量local就是一个ThreadLoacl对象,每个线程都可以对其进行读写,但是互不影响。也可以把local看成是全局变量,但是local.abs是线程的局部变量,可以任意读写而互不干扰,也不用管理锁问题,ThreadLoacl内部会处理。















 9890
9890











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









