






Pytorch3D坐标系
借用pytorch3d官网对于坐标系的解释来讲,pytorch3d中使用了一个NDC坐标系,这个坐标系最终将所有3d点的坐标归一化到-1到1之间。熟悉pytorch的朋友应该知道这是为了方便梯度的反向传播。
与常规的图形和视觉系统一致,我们分别定义了
1、模型坐标系(可选,图中未显示)
2、世界坐标系
3、相机坐标系
4、NDC坐标系
5、屏幕坐标系
其坐标轴的朝向如图所示
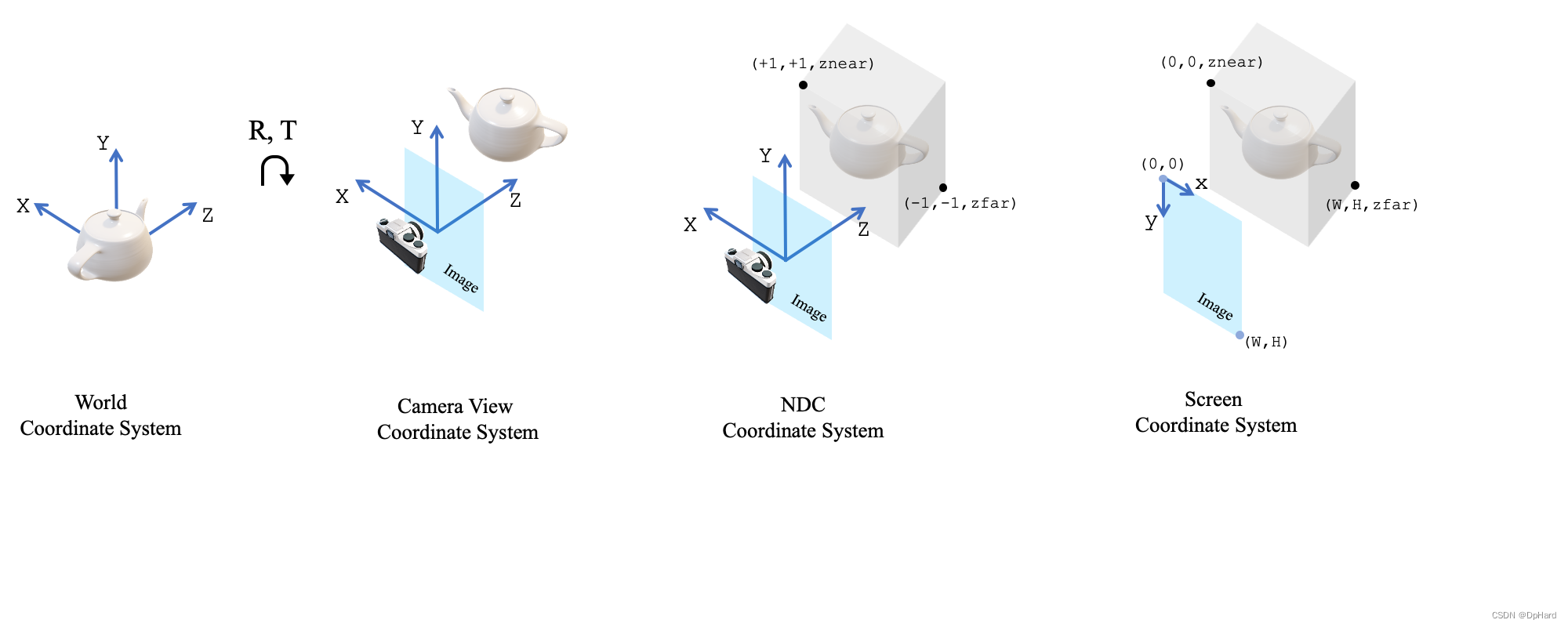
坐标系转换
在研究中我们很自然的获得了了3D模型的K(内参信息),RT位姿信息,但是往往直接输入会出现问题
这里需要辨析一些概念
概念解析
1、这里的R一般是世界坐标系到相机坐标系的旋转矩阵,一般记为R_w2c ,其逆矩阵 R − 1 = R T R^{-1}=R^T R−1=RT的三列代表着相机三个轴分别在世界坐标系的朝向,向量模长是1,基本性质可以通过games101查看
2、T一般是世界坐标系到相机坐标系的位移矩阵,一般记为t_w2c,它代表着
我们通过下面简单的分块矩阵乘法感受一下R和T具体的含义
设相机位姿为V,世界坐标系下相机位置(相机位置处成像)为t
[
V
T
1
]
[
E
−
t
1
]
=
]
[
V
T
−
V
T
t
0
1
]
[\begin{matrix}V^T&\\&1\end{matrix}][\begin{matrix}E&-t\\&1\end{matrix}]=][\begin{matrix}V^T&-V^Tt\\0&1\end{matrix}]
[VT1][E−t1]=][VT0−VTt1]
这个矩阵就是
[
R
T
1
]
[\begin{matrix}R&T\\&1\end{matrix}]
[RT1]
坐标转换
不同包之间的相机朝向一般是不同的

如上图所示,例如当已知在opencv坐标系下的R和T,想获得在pytorch3d坐标系下的转换矩阵
R
p
R_p
Rp和
T
p
T_p
Tp
按照我们对
V
V
V的理解,只需要将x轴和y轴取反就可以了,即对
V
V
V的第一列和第二列取反,其位置坐标t不变。
我们将相机再求一遍逆矩阵,获得新的
R
p
R_p
Rp和
T
p
T_p
Tp即为将原始
[
R
T
1
]
[\begin{matrix}R&T\\&1\end{matrix}]
[RT1]第一行和第二行取反的结果
注意: 新矩阵的对应T_p也要取反,这是因为我们是先定了相机位姿和位置然后求的逆矩阵获得的
R
p
R_p
Rp和
T
p
T_p
Tp
还有一个最重要的问题:pytorch3d中的3D点是按照Nx3的格式存储的,因此 在计算过程中 Point= point@R+t 而不是 Point=R @ point+t,所以在传入参数时应使用 R.t()
ps:如果使用R, T = pytorch3d.renderer.look_at_view_transform(dist=3, elev=0, azim=180)
生成的R和T已经是转置好了的,因此就不必再转置了。
实验
我们接下来通过几个实验,熟悉pytorch3d中的操作
下面提供了实验使用的模型和图片
实验所用到的数据和完整代码在以下链接中
实验链接
1、 利用MeshRasterizer生成深度图
正如前面所说,我们设in_ndc=False ,即为将相机定义在常规的坐标系中,我们按照opencv转pytorch3d的操作将R和T对应位置做改变
def getcamera(width,height,R,T,K):
T=T.reshape(3)
R[0,:]=-R[0,:]
T[0]=-T[0]
R[1,:]=-R[1,:]
T[1]=-T[1]
R=R.t()
fx,_,cx,_,fy,cy,_,_,_=K.reshape(9)
cameras = PerspectiveCameras(
image_size=[[height, width]],
R=R[None],
T=T[None],
focal_length=torch.tensor([[fx, fy]], dtype=torch.float32),
principal_point=torch.tensor([[cx, cy]], dtype=torch.float32),
in_ndc=False,
device=device
)
return cameras
def getdepth(model_path,R,T,K,device=torch.device('cuda')):
width,height=640,480
verts,faces=pytorch3d.io.load_ply(model_path)
mesh = pytorch3d.structures.Meshes(
verts=[verts],
faces=[faces],
textures=TexturesVertex(verts_features=torch.ones_like(verts)[None]),
)
mesh = mesh.to(device)
cameras=getcamera(width,height,R,T,K)
rasterizer = MeshRasterizer(
cameras=cameras,
raster_settings=RasterizationSettings(
image_size=((height, width)),
),
)
fragments = rasterizer(meshes_world=mesh)
return fragments.zbuf[0, :, :, 0],cameras

再将原图读入后,将深度值不为-1的点可视化一下,我们发现确实深度图渲染正确

2、手动变换验证3D-2D关系
更进一步,我们想手动控制3D-2D的变换,而不是通过渲染。
xy = camera1.transform_points_screen(xyz)[:, :, :2]
我们试图使用以上函数可视化为红色点,看看和渲染的深度位置的区别,通过下图可以看出是基本覆盖的,也就是说当使用上图函数时可以将3D转换成2D

那么在这个过程中具体坐标是如何转换的呢?
我们通过查阅文档的源码发现,要注意区分view和camera以及screen和camera的区别
在transform_points_screen过程中,实际上中转借助了ndc坐标系,但是图中没有画出
其中最重要的是view 到screen是先取反和缩放坐标轴,然后加上偏移,而到camera是直接缩放+偏移

我们用了两种方式,试图找到screen坐标和camera坐标的关系
xy2=camera1.transform_points(xyz)
xy3=camera1.get_ndc_camera_transform().transform_points(xy2)
pr_point_fix = torch.zeros(
(1, 4, 4), device=device, dtype=torch.float32
)
pr_point_fix[:, 0, 0] = 1.0
pr_point_fix[:, 1, 1] = 1.0
pr_point_fix[:, 2, 2] = 1.0
pr_point_fix[:, 3, 3] = 1.0
pr_point_fix[:, :2, 3] = -2.0 * camera1.get_principal_point()
pr_point_fix_transform = Transform3d(
matrix=pr_point_fix.transpose(1, 2).contiguous(), device=device
)
xy44=pr_point_fix_transform.transform_points(xy2)
xy44[:,:,:2]=-xy44[:,:,:2]
xy4=get_ndc_to_screen_transform(camera1,with_xyflip=True,image_size=camera1.get_image_size()).transform_points(xy3)
print(torch.allclose(xy4,xy44)) #true
print(torch.allclose(xy,xy4[:,:,:2])) #true
参考资料
- https://zhuanlan.zhihu.com/p/593204605
- https://zhuanlan.zhihu.com/p/651937759
- https://pytorch3d.org/docs/cameras















 882
882

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









