










入门机器学习(西瓜书+南瓜书)线性回归和逻辑回归总结(python代码实现)
一、线性回归理论总结
1.1 通俗理解
通俗理解的线性回归就是求解方程,拿一个最简单的例子来说就是对
y
=
k
x
+
b
y=kx+b
y=kx+b,只需要已知两个点
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
(x_{1},y_{1}),(x_{2},y_{2})
(x1,y1),(x2,y2)就可以解得参数
k
,
b
k ,b
k,b.进而可以对其余点预测。也就是说你给我一个
x
n
x_{n}
xn,我可以带入方程预测
y
n
y_{n}
yn.这也就是我们常说的解方程。
但是,我们要清晰的认识到这只是理想的情况,现实中的数据错综复杂,仅仅依靠两个点根本不具有代表性,他们甚至存在偏差或者噪声(可以理解为假数据),因此,传统的机器学习对线性的回归的做法就不仅仅依靠两个点了。而是大量的数据点,这样又会带来一个问题,也就是说找不到一个直线方程来拟合这么多的点。因此,我们常常来要求求出的方程要尽可能的拟合所有的样本点,方程的预测和真实数据之间的误差就是所谓的损失值,才用梯度下降的方法可以不断的优化更新参数
k
,
b
k,b
k,b.这里最终获得的方程不是“样本点的方程解”,应该叫“最优解”。这也就是线性回归的最通俗的理解。这里简单说下回归和分类的区别,回归一般值线性回归,预测值是一个连续值,也就是有小数点,而分类一般指逻辑回归。即把预测值应用激活函数划分,结果是一个离散的值。比如就西瓜数据集来说,回归可以是预测西瓜的含糖量,而分类就是根据含糖量划分好瓜坏瓜。
1.2 基本形式
给定由d个属性描述的示例
x
=
(
x
1
;
x
2
;
.
.
.
;
x
d
)
\textbf{x}=(x_{1};x_{2};...;x_{d})
x=(x1;x2;...;xd),其中
x
i
x_{i}
xi是第i个属性上的取值(这里的x代表一个上文中的一个点,而x本身可以具有很多的值,正如西瓜集中的根蒂,纹理,敲声。y代表标签或者说是真实值,也就是好瓜坏瓜。最后也就是找到参数
k
,
b
k,b
k,b),而这里把问题一般化了,也就是x有d个属性,那么就需要d个参数w(这里用w代替k ,其实仅仅是名字不同而已)来拟合数据。专业来说就是线性模型试图通过属性的线性组合来进行预测的函数,即
f
(
x
)
=
w
1
x
1
+
w
2
x
2
+
.
.
.
+
w
d
x
d
+
b
f(x)=w_{1}x_{1} + w_{2}x_{2}+...+w_{d}x_{d}+b
f(x)=w1x1+w2x2+...+wdxd+b
一般的用向量形式写成
f
(
x
)
=
w
T
x
+
b
f(x)=w^{T}x+b
f(x)=wTx+b
其中
w
=
(
w
1
;
w
2
;
.
.
.
w
d
)
w=(w_{1};w_{2};...w_{d})
w=(w1;w2;...wd),w和b学得以后,模型就得以确定
1.3 公式推导——最小二乘法(数学基础不好的同学可以不看)
就1.1中提到的机器学习为了使得模型更具泛化能力,要求方程学习更多的的样本,而且要求方程尽可能多的拟合被提供的数据,那么求出这样一些未知参数使得样本点和拟合线的总误差(距离)最小,而这个误差(距离)可以直接相减,但是直接相减会有正有负,相互抵消了,所以就用差的平方或者差的绝对值来计算。(而差的绝对值部分点不可导,因此一般我们采用差的平方来用作损失函数),那么对于拟合方程有
y
=
k
x
+
b
y=kx+b
y=kx+b .为了便于我们更好的理解,我们下面纤细的推到以下这个过程。
现在假设我们找到了最佳拟合的直线方程
y
=
k
x
+
b
y=kx+b
y=kx+b
那么对于每一个样本点
x
(
i
)
x^{(i)}
x(i),根据我们的直线方程,预测值为
y
^
(
i
)
\hat y^{(i)}
y^(i)可以表示为
y
^
(
i
)
=
k
x
(
i
)
+
b
\hat y^{(i)} = kx^{(i)} + b
y^(i)=kx(i)+b,真实值我们称作
y
(
i
)
y^{(i)}
y(i).希望y^{(i)}和
y
^
(
i
)
\hat y^{(i)}
y^(i)的差距尽可能地小,那么用差的平方考虑所有样本表示为
∑
i
=
1
m
(
y
(
i
)
−
y
^
(
i
)
)
2
\sum_{i=1}^{m}(y^{(i)}- \hat y^{(i)})^2
∑i=1m(y(i)−y^(i))2
那么我们的目标就是使得
∑
i
=
1
m
(
y
(
i
)
−
y
^
(
i
)
)
2
\sum_{i=1}^{m}(y^{(i)}- \hat y^{(i)})^2
∑i=1m(y(i)−y^(i))2尽可能地小。而且
y
^
(
i
)
=
k
x
(
i
)
+
b
\hat y^{(i)} = kx^{(i)} + b
y^(i)=kx(i)+b,也即是说找到k和b,使得
J
(
k
,
b
)
=
∑
i
=
1
m
(
y
(
i
)
−
k
x
(
i
)
−
b
)
2
J(k,b)=\sum_{i=1}^{m}(y^{(i)}- kx^{(i)} - b)^2
J(k,b)=∑i=1m(y(i)−kx(i)−b)2尽可能小。这个式子也叫损失函数(loss function)。机器学习最终的优化过程就是优化参数使得问题的损失函数最小。这里先给出问题的解。
k
=
∑
i
=
1
m
(
x
(
i
)
−
x
‾
)
(
y
(
i
)
−
y
‾
)
∑
i
=
1
m
(
x
(
i
)
−
x
‾
)
2
b
=
y
‾
−
k
x
‾
\begin{aligned} k&=\frac {\sum_{i=1}^{m}(x^{(i)}-\overline{x})(y^{(i)}-\overline{y})}{\sum_{i=1}^{m}(x^{(i)}- \overline{x})^2}\\ b&=\overline{y}-k\overline{x}\\ \end{aligned}
kb=∑i=1m(x(i)−x)2∑i=1m(x(i)−x)(y(i)−y)=y−kx
对于
J
(
k
,
b
)
J(k,b)
J(k,b)分别对k和b求偏导,令偏导数等于零,也就是说求函数的最小值$
这里涉及到比较基础的数学计算,如下所示。
对b,有
∂
J
(
k
,
b
)
∂
b
=
0
\frac{\partial J(k,b)}{\partial{b}}=0
∂b∂J(k,b)=0
∂
J
(
k
,
b
)
∂
b
=
∑
i
=
1
m
2
(
y
(
i
)
−
k
x
(
i
)
−
b
)
(
−
1
)
=
0
∑
i
=
1
m
(
y
(
i
)
−
k
x
(
i
)
−
b
)
=
0
∑
i
=
1
m
(
y
(
i
)
−
k
x
(
i
)
−
b
)
=
0
∑
i
=
1
m
y
(
i
)
−
k
∑
i
=
1
m
x
(
i
)
−
∑
i
=
1
m
b
=
0
∑
i
=
1
m
y
(
i
)
−
k
∑
i
=
1
m
x
(
i
)
−
m
b
=
0
m
b
=
∑
i
=
1
m
y
(
i
)
−
k
∑
i
=
1
m
x
(
i
)
b
=
y
‾
−
k
x
‾
\begin{aligned} \frac{\partial J(k,b)}{\partial{b}}&= \sum_{i=1}^{m}2(y^{(i)}- kx^{(i)} - b)(-1)=0 \\ \sum_{i=1}^{m}(y^{(i)}- kx^{(i)} - b)&=0 \\ \sum_{i=1}^{m}(y^{(i)}- kx^{(i)} - b)&=0 \\ \sum_{i=1}^{m}y^{(i)}-k \sum_{i=1}^{m}x^{(i)}- \sum_{i=1}^{m}b&=0 \\ \sum_{i=1}^{m}y^{(i)}-k \sum_{i=1}^{m}x^{(i)}- mb&=0\\ mb&=\sum_{i=1}^{m}y^{(i)}-k \sum_{i=1}^{m}x^{(i)} \\ b&=\overline{y}-k\overline{x}\\ \end{aligned}
∂b∂J(k,b)i=1∑m(y(i)−kx(i)−b)i=1∑m(y(i)−kx(i)−b)i=1∑my(i)−ki=1∑mx(i)−i=1∑mbi=1∑my(i)−ki=1∑mx(i)−mbmbb=i=1∑m2(y(i)−kx(i)−b)(−1)=0=0=0=0=0=i=1∑my(i)−ki=1∑mx(i)=y−kx
对k,由
b
=
y
‾
−
k
x
‾
和
∂
J
(
k
,
b
)
∂
k
=
0
b=\overline{y}-k\overline{x}和\frac{\partial J(k,b)}{\partial{k}}=0
b=y−kx和∂k∂J(k,b)=0
∂
J
(
k
,
b
)
∂
k
=
∑
i
=
1
m
2
(
y
(
i
)
−
k
x
(
i
)
−
b
)
(
−
x
(
i
)
)
=
0
∑
i
=
1
m
(
y
(
i
)
−
k
x
(
i
)
−
b
)
x
(
i
)
=
0
展开整理可得
∑
i
=
1
m
(
x
(
i
)
y
(
i
)
−
x
(
i
)
y
‾
)
−
k
∑
i
=
1
m
(
(
x
(
i
)
)
2
−
x
‾
x
(
i
)
)
=
0
解得
k
=
∑
i
=
1
m
(
x
(
i
)
y
(
i
)
−
x
(
i
)
y
‾
)
∑
i
=
1
m
(
(
x
(
i
)
)
2
−
x
‾
x
(
i
)
)
这里涉及到一些等式的代换
∑
i
=
1
m
x
(
i
)
y
‾
=
y
‾
∑
i
=
1
m
x
(
i
)
=
m
y
‾
x
‾
=
x
‾
∑
i
=
1
m
y
(
i
)
=
∑
i
=
1
m
x
‾
⋅
y
‾
\begin{aligned} \frac{\partial J(k,b)}{\partial{k}}= \sum_{i=1}^{m}2(y^{(i)}- kx^{(i)} - b)(-x^{(i)})=0\\ \sum_{i=1}^{m}(y^{(i)}- kx^{(i)} - b)x^{(i)}&=0\\ 展开整理可得 \sum_{i=1}^{m}(x^{(i)}y^{(i)}-x^{(i)}\overline{y})- k\sum_{i=1}^{m}((x^{(i)})^2 - \overline{x}x^{(i)})&=0\\ 解得 k=\frac {\sum_{i=1}^{m}(x^{(i)}y^{(i)}-x^{(i)}\overline{y})}{\sum_{i=1}^{m}((x^{(i)})^2 - \overline{x}x^{(i)})}\\ 这里涉及到一些等式的代换\\ \sum_{i=1}^{m}x^{(i)}\overline{y}=\overline{y}\sum_{i=1}^{m}x^{(i)}=m\overline{y}\overline{x}=\overline{x}\sum_{i=1}^{m}y^{(i)}=\sum_{i=1}^{m}\overline{x}\cdot \overline{y}\\ \end{aligned}
∂k∂J(k,b)=i=1∑m2(y(i)−kx(i)−b)(−x(i))=0i=1∑m(y(i)−kx(i)−b)x(i)展开整理可得i=1∑m(x(i)y(i)−x(i)y)−ki=1∑m((x(i))2−xx(i))解得k=∑i=1m((x(i))2−xx(i))∑i=1m(x(i)y(i)−x(i)y)这里涉及到一些等式的代换i=1∑mx(i)y=yi=1∑mx(i)=myx=xi=1∑my(i)=i=1∑mx⋅y=0=0
那么对于k的结果进一步化简
k
=
∑
i
=
1
m
(
x
(
i
)
y
(
i
)
−
x
(
i
)
y
‾
)
∑
i
=
1
m
(
(
x
(
i
)
)
2
−
x
‾
x
(
i
)
)
=
∑
i
=
1
m
(
x
(
i
)
y
(
i
)
−
x
(
i
)
y
‾
−
x
‾
y
(
i
)
+
x
‾
⋅
y
‾
)
∑
i
=
1
m
(
(
x
(
i
)
)
2
−
x
‾
x
(
i
)
−
x
‾
x
(
i
)
+
x
‾
2
)
=
∑
i
=
1
m
(
x
(
i
)
−
x
‾
)
(
y
(
i
)
−
y
‾
)
∑
i
=
1
m
(
x
(
i
)
−
x
‾
)
2
\begin{aligned} k&=\frac {\sum_{i=1}^{m}(x^{(i)}y^{(i)}-x^{(i)}\overline{y})}{\sum_{i=1}^{m}((x^{(i)})^2 - \overline{x}x^{(i)})}\\ &=\frac {\sum_{i=1}^{m}(x^{(i)}y^{(i)}-x^{(i)}\overline{y}-\overline{x}y^{(i)}+\overline{x}\cdot \overline{y})}{\sum_{i=1}^{m}((x^{(i)})^2 - \overline{x}x^{(i)}-\overline{x}x^{(i)}+\overline{x}^2)}\\ &=\frac {\sum_{i=1}^{m}(x^{(i)}-\overline{x})(y^{(i)}-\overline{y})}{\sum_{i=1}^{m}(x^{(i)}- \overline{x})^2}\\ \end{aligned}
k=∑i=1m((x(i))2−xx(i))∑i=1m(x(i)y(i)−x(i)y)=∑i=1m((x(i))2−xx(i)−xx(i)+x2)∑i=1m(x(i)y(i)−x(i)y−xy(i)+x⋅y)=∑i=1m(x(i)−x)2∑i=1m(x(i)−x)(y(i)−y)
上述这个过程就是著名的最小二乘法。这也可以说是线性回归的基础。也可以说是AI的起点。可以看到数学的结果“美”的,但是这个过程就一言难尽,所以说AI的尽头还是数学。
如果同学的数学基础十分扎实,那么,这个优化的过程也可以采用最大似然估计来得到参数。这里还有一个专业的内容就是求解参数唯一的凸函数求解问题。具体细节请详见西瓜书54页,南瓜书第16页,对应配套视频南瓜书一元线性回归配套视频。最终得到的优化结果同样是
∑
i
=
1
m
(
y
(
i
)
−
y
^
(
i
)
)
2
\sum_{i=1}^{m}(y^{(i)}- \hat y^{(i)})^2
∑i=1m(y(i)−y^(i))2,即最小二乘法和最大似然估计法殊途同归。
1.4 多元线性回归
上述只有参数k和b,那么对于更多的参数应该怎么做呢?而且,要在计算机写程序就要求运算速度,那么就注定要用矩阵运算来求解。因此GPU(图形处理器)应运而生,适应于矩阵运算。这也是机器学习发展面临的最实际的问题,运算速度与多维特征。
下面我们就简单介绍一下求解的算法。首先如果采用矩阵运算的方式,就需要消除掉偏置b的影响,将他加入到矩阵运算中。求解的原理也很简单,我们把b设为
k
0
k_{0}
k0,其对应的特征
x
x
x全为1(这样的矩阵在线性代数里被称作增广矩阵),这样可以随着特征矩阵X一起计算,改进后的向量
k
^
=
(
b
;
k
)
\hat k=(b;k)
k^=(b;k)(这里的k是多个参数的)也就是说k的他们总体。更确切地说
k
^
=
(
b
,
k
1
,
k
2
,
.
.
.
,
k
d
)
\hat k=(b,k_{1},k_{2},...,k_{d})
k^=(b,k1,k2,...,kd)那么对于由所有样本组成的特征矩阵为:
(
1
x
11
x
12
⋯
x
1
d
1
x
21
x
22
⋯
x
2
d
⋮
⋮
⋮
⋱
⋮
1
x
m
1
x
m
2
⋯
x
m
d
)
=
(
1
x
1
1
x
2
⋮
⋮
1
x
m
)
\begin{pmatrix} {1}&{x_{11}}&{x_{12}}&{\cdots}&{x_{1d}}\\ {1}&{x_{21}}&{x_{22}}&{\cdots}&{x_{2d}}\\ {\vdots}&{\vdots}&{\vdots}&{\ddots}&{\vdots}\\ {1}&{x_{m1}}&{x_{m2}}&{\cdots}&{x_{md}}\\ \end{pmatrix}=\begin{pmatrix} {1}&{x_{1}}\\ {1}&{x_{2}}\\ {\vdots}&{\vdots}\\ {1}&{x_{m}}\\ \end{pmatrix}
11⋮1x11x21⋮xm1x12x22⋮xm2⋯⋯⋱⋯x1dx2d⋮xmd
=
11⋮1x1x2⋮xm
其实全为1的一列,加入左侧右侧都是一样的,只不过最终的结果不同,当前的矩阵最终运算的参数第一个参数是偏置b,而当全为1的一列放入最右侧一列时,最后一个参数时偏置b。这样预测的结果
y
^
=
X
k
^
T
\hat y = X\hat k^T
y^=Xk^T,这里注意矩阵的运算要求第一个的矩阵的列等于第二个矩阵的行,这里X时m行d+1列,
k
^
\hat k
k^是1行,d+1列,所以要把
k
^
\hat k
k^转置。最终就是要优化
k
^
\hat k
k^了。
我们把最优化的
k
^
∗
=
a
r
g
m
i
n
(
y
−
X
k
^
)
T
(
y
−
X
k
^
)
)
\hat k^*= argmin(y-X\hat k)^T(y-X\hat k))
k^∗=argmin(y−Xk^)T(y−Xk^)),那么我们损失函数
J
(
k
^
)
=
(
y
−
X
k
^
)
T
(
y
−
X
k
^
)
)
J(\hat k)=(y-X\hat k)^T(y-X\hat k))
J(k^)=(y−Xk^)T(y−Xk^))
∂
J
(
k
^
)
∂
k
^
=
∂
(
y
−
X
k
^
)
T
(
y
−
X
k
^
)
∂
k
^
=
∂
(
y
T
y
−
k
^
X
T
y
−
y
T
X
k
^
+
k
^
T
X
T
X
)
∂
k
^
=
0
−
X
T
y
−
X
T
y
+
(
X
T
X
+
X
T
X
)
k
^
=
2
X
T
(
X
k
^
−
y
)
\begin{aligned} \frac {\partial{J(\hat k)}}{\partial{\hat k}} &= \frac {\partial{(y-X\hat k)^T(y-X\hat k)}}{\partial{\hat k}}\\ &= \frac {\partial{(y^Ty-\hat kX^Ty - y^TX\hat k+\hat k^TX^TX)}}{\partial{\hat k}}\\ &= 0-X^Ty-X^Ty+(X^TX+X^TX)\hat k\\ &=2X^T(X\hat k-y)\\ \end{aligned}
∂k^∂J(k^)=∂k^∂(y−Xk^)T(y−Xk^)=∂k^∂(yTy−k^XTy−yTXk^+k^TXTX)=0−XTy−XTy+(XTX+XTX)k^=2XT(Xk^−y)
这里的求解用到两个公式
∂
α
T
x
∂
x
=
∂
x
T
α
∂
x
=
α
∂
x
T
A
x
∂
x
=
(
A
+
A
T
)
x
\begin{aligned} \frac{\partial{\alpha ^Tx}}{\partial{x}}=\frac{\partial{x ^T\alpha}}{\partial{x}}=\alpha \\ \frac{\partial{x ^TAx}}{\partial{x}}=(A+A^T)x \end{aligned}
∂x∂αTx=∂x∂xTα=α∂x∂xTAx=(A+AT)x
令
2
X
T
(
X
k
^
−
y
)
=
0
2X^T(X\hat k-y)=0
2XT(Xk^−y)=0解得
k
^
=
(
X
T
X
)
−
1
X
T
y
\hat k=(X^TX)^{-1}X^Ty
k^=(XTX)−1XTy
具体细节请详见西瓜书54页,南瓜书第16页,对应配套视频南瓜书多元线性回归对应配套视频。
但是我们必须清晰的认识到,这样的解只有在
(
X
T
X
)
(X^TX)
(XTX)可逆才可以求解,而在实际任务中,往往样本数量会小于特征个数d,此时显然
(
X
T
X
)
(X^TX)
(XTX)不满秩(这个是线性代数的专有名词,也就是不可逆),此时会有很多的
k
^
\hat k
k^满足方程。也就是解不唯一,我们的目的就是为了找到方程的最优解。那么常用的方法就是引入正则化项,进而对模型的参数设施限制。正则化项一般直接加入损失函数,称为损失函数的一部分,这样正则化项也会被当作优化项,也就是模型的参数不可以过大,这样就可以有效的抑制模型的表现力,限制模型变得复杂,也就是模型会变得更加简单,这将会提高模型的泛化能力,有效抑制模型的过拟合。而常见的正则化项由L1范数(也就是模型参数的绝对值,优化后使得参数向量稀疏)和L2范数(模型参数平方和开根号,使得向量二维范数降低)。
那么上述的问题该如何解决呢,梯度下降法给出了一个相对不错的答案,而梯度下降法因为对该问题的有效求解,当之无愧的称为AI界基石,也就是说几乎所有的模型参数的优化都离不开梯度下降的影子。关于梯度下降的详细过程我之前的博客由详细的描述,感兴趣的朋友可以点这里梯度下降算法
此外,还有一系列的方法对线性回归变式,比如再加入一个非线性的映射,使得模型含有非线性关系,比如
l
n
y
lny
lny.这样如果数据分布本身是
e
k
x
+
b
e^{kx+b}
ekx+b的分布,加入非线性映射
l
n
y
lny
lny后,便成了我熟悉的线性回归。
这里基本就是AI的所有最基本的步骤,读者可以再次回顾整个模型训练的过程。这里附上一张流程图供大家参考。

二、逻辑回归理论总结
2.1 通俗理解
说到逻辑回归,不得不提到分类,提到分类就不得不说到一个东西,叫做激活函数。毕竟目前的AI都是基于统计学习方法,因此很依赖概率统计,我们需要一个方法,把预测的值转化到(0,1)的数,最好还是增函数,这样也很容易比较。最好还要可导。嘻嘻,是不是感觉要求这么多能找到吗?答案是肯定的,这个函数就是著名的sigmoid函数。它不仅在逻辑回归中占据重要地位,甚至目前大红大紫火的深度学习都离不开他的影子,它可以把线性的方法非线性化。使得深度神经网络理论上可以拟合任何的函数。
咳咳,扯得有点多。下面有请我们的主角登场,在哪里呢,看下图。

sigmoid:还有谁?还有谁?
哈哈,大哥直到现在都可以被称为是经典的激活函数,AI界的宠儿。仔细观察,他成功的把从
(
−
∞
,
+
∞
)
(-\infty,+\infty)
(−∞,+∞)的所有数都映射到了
(
0
,
1
)
(0,1)
(0,1),而且还是单调递增,而且还是处处可导。笔者只想说一句666。
来人把大哥的表达式请上来,
S
i
g
m
o
i
d
(
x
)
=
1
1
+
e
−
x
Sigmoid(x)=\frac{1}{1+e^{-x}}
Sigmoid(x)=1+e−x1.
这里我们对最简单的二分类进行举例。

这其实也就是逻辑回归的全部秘密。就是由于大哥的存在,回归就成为了分类,我们可以在其中设置一个阈值,一般是0.5,即大于0.5的为正类,小于0.5的为负类。另一个方面,逻辑回归的损失函数和线性回归的损失函数也有所区别。比如二分类的损失函数是二类交叉熵函数。
b
i
n
a
r
y
C
r
o
s
s
E
n
t
r
o
p
y
=
−
y
l
n
p
−
(
1
−
y
)
l
n
(
1
−
p
)
binaryCrossEntropy = -ylnp - (1-y)ln(1-p)
binaryCrossEntropy=−ylnp−(1−y)ln(1−p)
其中p为
p
(
y
=
1
∣
x
^
;
β
)
=
e
β
T
x
^
1
+
e
β
T
x
^
=
p
1
(
x
^
;
β
)
p(y=1|\hat x;\beta)=\frac{e^{\beta^{T}\hat x}}{1+e^{\beta ^{T}\hat x}}=p_{1}(\hat x;\beta)
p(y=1∣x^;β)=1+eβTx^eβTx^=p1(x^;β)

具体细节请详见西瓜书57页,南瓜书第16页,对应配套视频南瓜书对数几率回归对应配套视频。
2.2 理论分析
对于激活后的结果为
y
=
1
1
+
e
−
(
k
T
x
+
b
)
y=\frac{1}{1+e^{-(k^Tx+b)}}
y=1+e−(kTx+b)1
两边取ln对数有
y
(
1
+
e
−
(
k
T
x
+
b
)
)
=
1
e
−
(
k
T
x
+
b
)
=
1
−
y
y
−
(
k
T
x
+
b
)
=
l
n
(
1
−
y
y
)
k
T
x
+
b
=
l
n
(
1
−
y
y
)
−
1
k
T
x
+
b
=
l
n
(
y
1
−
y
)
\begin{aligned} y(1+e^{-(k^Tx+b)}) &= 1 \\ e^{-(k^Tx+b)} &=\frac{1-y}{y}\\ {-(k^Tx+b)}&=ln(\frac{1-y}{y})\\ k^Tx+b&=ln(\frac{1-y}{y})^{-1}\\ k^Tx+b&=ln(\frac{y}{1-y}) \end{aligned}
y(1+e−(kTx+b))e−(kTx+b)−(kTx+b)kTx+bkTx+b=1=y1−y=ln(y1−y)=ln(y1−y)−1=ln(1−yy)
这里将y视作样本为正例的可能性,则1-y为样本为负例,两者的比值
y
1
−
y
\frac{y}{1-y}
1−yy称为几率(odds),表示是正例的相对可能性,对几率取对数可以得到对数几率,因此线性回归的结果去逼近是对数几率。逻辑回归其实本质上是一个分类模型。这样多分类的方法基本和二分类类似,方法有一对一,一对多,多对多。
2.3 类别分布不平衡
这里存在一个比较经典的例子,我想要设置一个分类器,帮助我找到癌症病人,可以想象数据分布中大致1000人有1人是癌症,那么如果以此为训练集,模型很容易认为基本上都是正常,准确率高达99.9%,但是,这个模型根本没有存在的意义。因此为了避免这种问题,尤其是在二分类的情况下,我们常常把正负样本的比例设置为1:1,并且为了排除顺序的干扰(前半部分都是正例,后半部分都是负例)。我们常常把样本集打乱顺序。
但是对于数据分布本身就存在问题的,我们也需要优化样本类别的方法。
再放缩(rescaling):主要思想是更改决策阈值,使之更加贴合正负样本的比例,比如我们设置阈值为0.1,也就是说只有预测小于0.1才被判定为患有癌症。
采样(sampling):对于多数样本欠采样,也就是少取点,对于少数样本过采样,也就是多取点,这样保证正负样本个数平衡。
具体细节请详见西瓜书66页,南瓜书第16页,对应配套视频南瓜书二分类线性判别分析对应配套视频。
三、代码实现
3.1 线性回归
**利用求解公式 k ^ = ( X T X ) − 1 X T y \hat k=(X^TX)^{-1}X^Ty k^=(XTX)−1XTy**求解参数
# !/usr/bin/env python
# @Time:2022/3/22 16:02
# @Author:华阳
# @File:linear_regression.py
# @Software:PyCharm
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv("ex0_1.csv",header=None)
data = df.values
X=data[:,0].reshape((-1,1))
Y=data[:,1].reshape((-1,1))
plt.scatter(X,Y)
x_min = min(X)
x_max = max(X)
ones=np.ones((X.shape[0],1))
X=np.hstack((ones,X))
XT=X.T
XTX=np.dot(XT,X)
XTX_1=np.linalg.inv(XTX)
XTX_1XT=np.dot(XTX_1,XT)
W=np.dot(XTX_1XT,Y)
x_w = np.linspace(x_min,x_max,100)
y_w = x_w*W[1]+W[0]
plt.plot(x_w,y_w)
plt.show()
运行结果:

线性回归案例:拟合学习时间和学习成绩关系(jupyter):
- 提出问题 已知一部分学生的学习时间和分数,预测另一部分学生的分数。其中,特征为学习时间,标签为分数。
- 理解数据 将数据集导入python,计算相关系数
- 构建模型 (1) 提取特征和标签 (2) 建立训练数据和测试数据 (3) 训练模型(使用训练数据) (4) 模型评估(使用测试数据)
#OrderedDict,实现了对字典对象中元素的排序。
from collections import OrderedDict
import pandas as pd
#建立数据集
examDict={
'学习时间':[0.50,0.75,1.00,1.25,1.50,1.75,1.75,2.00,2.25,
2.50,2.75,3.00,3.25,3.50,4.00,4.25,4.50,4.75,5.00,5.50],
'分数':[10, 22, 13, 43, 20, 22, 33, 50, 62,
48, 55, 75, 62, 73, 81, 76, 64, 82, 90, 93]}
examOrderDict=OrderedDict(examDict)
examDf=pd.DataFrame(examOrderDict)
#查看数据集前5行
examDf.head()
#提取特征和标签
#特征features
exam_X=examDf.loc[:,'学习时间']
#标签labes
exam_Y=examDf.loc[:,'分数']
#绘制散点图
import matplotlib.pyplot as plt
#散点图
plt.scatter(exam_X, exam_Y, color="b", label="exam data")
#添加图标标签
plt.xlabel("Hours")
plt.ylabel("Pass")
#显示图像
plt.show()

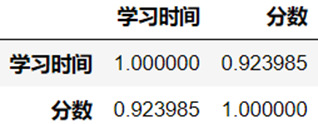
#相关系数:corr返回结果是一个数据框,存放的是相关系数矩阵(协方差)
rDf=examDf.corr()
print('相关系数矩阵:')
rDf
#特征features
exam_X=examDf.loc[:,'学习时间']
#标签labes
exam_Y=examDf.loc[:,'分数']
from sklearn.model_selection import train_test_split
#建立训练数据和测试数据
X_train , X_test , Y_train , Y_test = train_test_split(exam_X,exam_Y,train_size=0.8)
#输出数据大小
print('原始数据特征:',exam_X.shape,'训练数据特征:',X_train.shape,',测试数据特征:',X_test.shape)
print('原始数据标签:',exam_Y.shape,'训练数据标签:',Y_train.shape ,'测试数据标签:',Y_test.shape)
#散点图
plt.scatter(X_train, Y_train, color="blue", label="train data")
plt.scatter(X_test, Y_test, color="red", label="test data")
原始数据特征: (20,) 训练数据特征: (16,) ,测试数据特征: (4,)
原始数据标签: (20,) 训练数据标签: (16,) 测试数据标签: (4,)

#将训练数据特征转换成二维数组XX行*1列
X_train=X_train.values.reshape(-1,1)
#将测试数据特征转换成二维数组行数*1列
X_test=X_test.values.reshape(-1,1)
''' reshape(-1,列数)是根据所给的列数,自动按照原始数组的大小形成一个新的数组,
例如reshape(-1,1)就是改变成1列的数组,这个数组的长度是根据原始数组的大小来自动形成的。
reshape(行数,-1)是根据所给的行数,自动按照原始数组的大小形成一个新的数组。'''
#第1步:导入线性回归
from sklearn.linear_model import LinearRegression
#第2步:创建模型:线性回归
model = LinearRegression()
#第3步:训练模型
model.fit(X_train , Y_train)
'''
最佳拟合线:z= + x
截距intercept:a
回归系数:b
'''
#截距
a=model.intercept_
#回归系数
b=model.coef_
print('最佳拟合线:截距a=',a,',回归系数b=',b)
#得到最佳拟合曲线:
#训练数据散点图
plt.scatter(X_train, Y_train, color='blue', label="train data")
#训练数据的预测值
Y_train_pred = model.predict(X_train)
#绘制最佳拟合线
plt.plot(X_train, Y_train_pred, color='black', linewidth=3, label="best line")
最佳拟合线:截距a= 13.518458698661739 ,回归系数b= [15.04845408]
![[<matplotlib.lines.Line2D at 0x1dec394ee10>]](https://img-blog.csdnimg.cn/60f672706ab844baac9ba8ac20158584.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5ZWl6YO95LiN5oeC55qE5bCP56iL5bqP54y_,size_10,color_FFFFFF,t_70,g_se,x_16)
#线性回归的score方法得到的是决定系数R平方
model.score(X_test , Y_test)
#score内部会对第一个参数X_test用拟合曲线自动计算出y预测值,内容是决定系数R平方的计算过程。
#导入绘图包
import matplotlib.pyplot as plt
#第1步:绘制训练数据散点图
plt.scatter(X_train, Y_train, color='blue', label="train data")
#第2步:用训练数据绘制最佳线
#最佳拟合线训练数据的预测值
Y_train_pred = model.predict(X_train)
#绘制最佳拟合线:标签用的是训练数据的预测值y_train_pred
plt.plot(X_train, Y_train_pred, color='black', linewidth=3, label="best line")
#第3步:绘制测试数据的散点图
plt.scatter(X_test, Y_test, color='red', label="test data")
#添加图标标签
plt.legend(loc=2)
plt.xlabel("Hours")
plt.ylabel("Score")
#显示图像
plt.show()

案例分析二波士顿房价(pycharm)
# !/usr/bin/env python
# @Time:2022/3/22 16:02
# @Author:华阳
# @File:linear_regression.py
# @Software:PyCharm
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.utils import shuffle
df = pd.read_csv("boston.csv")
df = np.array(df.values,ndmin=2)
x_data = df[:,:12]
#归一化
for i in range(12):
x_data[:,i] = (x_data[:,i]-x_data[:,i].min())/(x_data[:,i].max()-x_data[:,i].min())
y_data = df[:,12]
#将后10个作为测试集,不参加训练
test_x = x_data[-10:]
test_y = y_data[-10:]
x_d = x_data[:-10]
y_d = y_data[:-10]
#初始化参数
w = np.random.normal(0.0,1.0,(1,12))
b = 0.0
#设置训练轮次
train_epochs = 200
learing_rate = 0.001
loss_=[]
for count in range(train_epochs):
loss=[]
for i in range(len(x_d)):
re = w.dot(x_d[i])+b
err_loss = (y_d[i]-re)*(y_d[i]-re)
err = 2*(y_d[i]-re)
w += learing_rate*err*x_d[i] #err种re为负值,所以没有负号
b += learing_rate*err
#记录误差
loss.append(abs(err_loss))
loss_.append(sum(loss)/len(loss))
print("第%d轮次,损失值为:%.3f"%(count+1,sum(loss)/len(loss)))
#随机打乱训练集中的样本,防止模型出现结果和输入的位置有关的情况
x_d,y_d = shuffle(x_d,y_d)
#打印误差的变化情况
fig1 = plt.figure(1,(5,5))
plt.plot(loss_)
plt.show()
#简单的评估,看看实际值和预测值之间的误差
sum_loss = 0
for i in range(10):
print("true:\t{}".format(test_y[i]),end="\t")
pre = np.dot(w,test_x[i])+b
sum_loss += (pre-test_y[i])**2
print("guess:\t{}".format(pre))
pre = [np.dot(w,x_d[i])+b for i in range(len(x_d)-10)]
fig2 = plt.figure(1,(5,10))
axe_train = fig2.add_subplot(211)
axe_train.set_title('distribution between true and prediction about train data')
axe_train.plot(y_d,color='red',label='true')
axe_train.plot(pre,color='blue',label='prediction')
axe_train.legend()
pre1 = [np.dot(w,test_x[i])+b for i in range(len(test_x))]
axe_test = fig2.add_subplot(212)
axe_test.set_title('distribution between true and prediction about test data')
axe_test.plot(test_y,color='red',label='true')
axe_test.plot(pre1,color='blue',label='prediction')
axe_test.legend()
print("测试集损失为%.3f"%sum_loss)
plt.show()


3.2 逻辑回归
头歌Educoder案例一逻辑回归实现癌细胞识别
动手实现逻辑回归 - 癌细胞精准识别
数据集介绍
乳腺癌数据集,其实例数量是 569 ,实例中包括诊断类和属性,帮助预测的属性一共 30 个,各属性包括为 radius 半径(从中心到边缘上点的距离的平均值), texture 纹理(灰度值的标准偏差)等等,类包括: WDBC-Malignant 恶性和 WDBC-Benign 良性。用数据集的 80% 作为训练集,数据集的 20% 作为测试集,训练集和测试集中都包括特征和类别。其中特征和类别均为数值类型,类别中 0 代表良性, 1 代表恶性。
# -*- coding: utf-8 -*-
import numpy as np
import warnings
warnings.filterwarnings("ignore")
def sigmoid(x):
'''
sigmoid函数
:param x: 转换前的输入
:return: 转换后的概率
'''
return 1/(1+np.exp(-x))
def fit(x,y,eta=1e-3,n_iters=10000):
'''
训练逻辑回归模型
:param x: 训练集特征数据,类型为ndarray
:param y: 训练集标签,类型为ndarray
:param eta: 学习率,类型为float
:param n_iters: 训练轮数,类型为int
:return: 模型参数,类型为ndarray
'''
# 请在此添加实现代码 #
#********** Begin *********#
theta = np.ones((x.shape[1]+1,1))
print(theta.shape)
a = np.ones((len(x),1))
X = np.hstack([a,x])
count = 0
while(count < n_iters):
predict = X.dot(theta)
theta1 = theta - eta * (predict - y).dot(X)
theta = theta1
count += 1
return theta[1:]
#********** End **********#
逻辑回归实现手写字识别
手写数字识别,本关使用的是手写数字数据集,该数据集有 1797 个样本,每个样本包括 8*8 像素(实际上是一条样本有 64 个特征,每个像素看成是一个特征,每个特征都是float类型的数值)的图像和一个 [0, 9] 整数的标签。比如下图的标签是 2 :

方法一:调参比较麻烦
from sklearn.linear_model import LogisticRegression
def digit_predict(train_image, train_label, test_image):
'''
实现功能:训练模型并输出预测结果
:param train_sample: 包含多条训练样本的样本集,类型为ndarray,shape为[-1, 8, 8]
:param train_label: 包含多条训练样本标签的标签集,类型为ndarray
:param test_sample: 包含多条测试样本的测试集,类型为ndarry
:return: test_sample对应的预测标签
'''
#************* Begin ************#
model = LogisticRegression(max_iter=500,C=0.3)
train_image = train_image.reshape(-1,64)
test_image = test_image.reshape(-1,64)
model.fit(train_image,train_label)
result = model.predict(test_image)
return result
#************* End **************#
方法二:对数据归一化
from sklearn.linear_model import LogisticRegression
def digit_predict(train_image, train_label, test_image):
'''
实现功能:训练模型并输出预测结果
:param train_sample: 包含多条训练样本的样本集,类型为ndarray,shape为[-1, 8, 8]
:param train_label: 包含多条训练样本标签的标签集,类型为ndarray
:param test_sample: 包含多条测试样本的测试集,类型为ndarry
:return: test_sample对应的预测标签
'''
#************* Begin ************#
# 训练集变形
flat_train_image = train_image.reshape((-1, 64))
# 训练集标准化
train_min = flat_train_image.min()
train_max = flat_train_image.max()
flat_train_image = (flat_train_image-train_min)/(train_max-train_min)
# 测试集变形
flat_test_image = test_image.reshape((-1, 64))
# 测试集标准化
test_min = flat_test_image.min()
test_max = flat_test_image.max()
flat_test_image = (flat_test_image - test_min) / (test_max - test_min)
# 训练--预测
rf = LogisticRegression(C=4.0)
rf.fit(flat_train_image, train_label)
return rf.predict(flat_test_image)
#************* End **************#















 670
670











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









