






实现功能
验证码自动识别
模拟登陆
多用户数据下载
excel处理
数据库操作
梗概
炒期货的朋友是不是也有这样的体验,打开中国期货市场监控中心网站,手动登陆到每个帐户,然后在帐户上进行下载数据(逐日盯市),再通过EXCEL宏等统计制作成树状图的形式。
这样操作有许多缺点和不足的地方,比如:
工作量比较大;
不能统计一定时间内的数据;
不能统一管理和数据分析;
多个账号无法对比分析。
因此,写了个爬虫和后台,爬虫每天自动登录中国期货市场监控中心,自动下载逐日盯市的表格数据,然后队列处理数据,写入到自己的后台,就可以分析每个账号一段时间操作的净值、盈亏比等了。
分析
在写爬虫前,我们先手动操作一遍,分析一下流程。
打开登录页,登录页面有验证码,在实现的时候需要自动识别
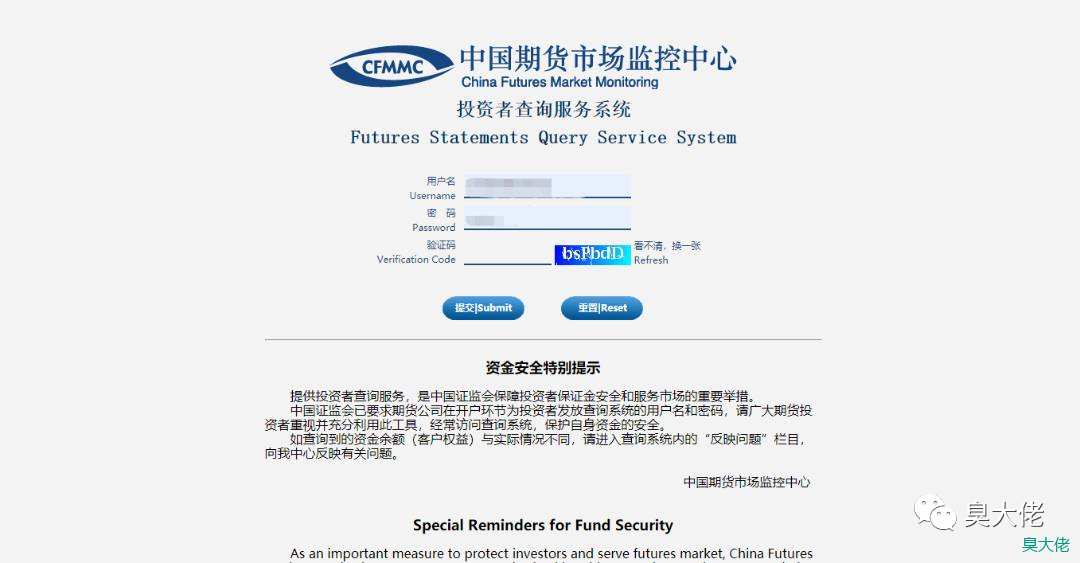
手动登录后,进入的第一个页面是今天的逐笔对冲,
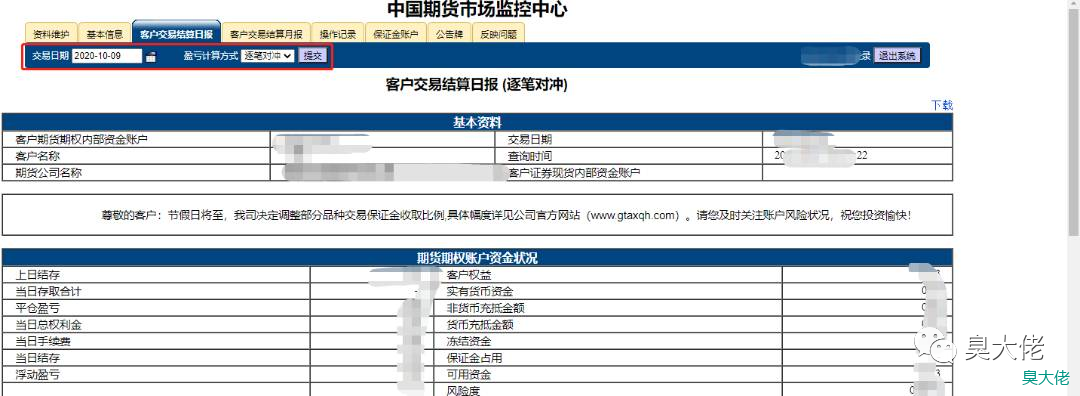
我们要的是逐日盯市,而且不一定是今天的数据,打开F12,切换到逐日盯市页面,

从 Network 中可以看到如下信息;
Request URL: https://investorservice.cfmmc.com/customer/setParameter.do
Request Method: POST
org.apache.struts.taglib.html.TOKEN: 08424ad1b28fabecccd7bf5161108b13
tradeDate: 2020-10-09
byType: date

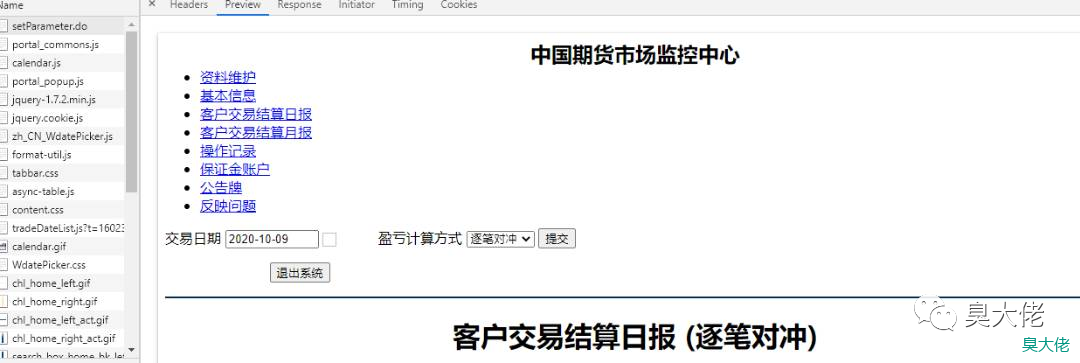
从上面可以看到接口和参数,
org.apache.struts.taglib.html.TOKEN:是登录页面中的一个 input,经测试,不传似乎没什么影响,
tradeDate:查询的日期,
byType:trade为默认值,trade时是逐笔对冲,date是逐日盯市。
另外,返回的并不是接口形式的数据,而是一个页面,
有了接口和参数,我们就可以抓取指定日期的逐日盯市了。
思路其实很简单,获取用户账号密码,模拟登陆,切换到逐日盯市,下载数据,然后处理excel文件,写到数据库,后台对数据进行分析。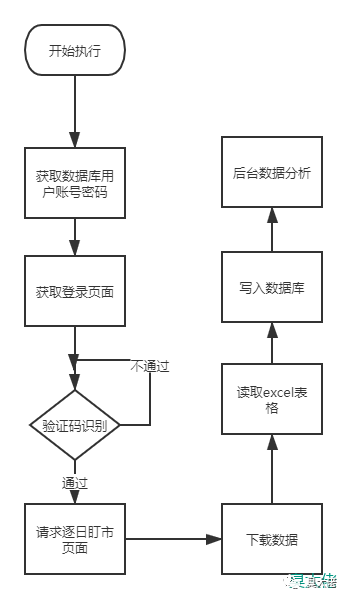
技术点
自动识别验证码
模拟登陆
excel处理
数据库写入
整个流程下来,技术点基本就上面几个。
这个验证码看似很普通,但Google的开源工具Tesseract-OCR识别率太低了,基本识别不了,于是找了BAT大厂的识别接口,依次封装成接口,方便调用:
Tesseract-OCR
腾讯文字识别API
百度文字识别API
百度文字识别SDK
由于阿里的文档只看到python2的,所以就忽略了。识别率自上而下越来越高,腾讯的有点坑,识别率不算高,每天免费次数少,超过还扣费,然后一直给你发欠费邮件,百度SDK识别率是最好的,一般都是5次以内,而且每月免费5000次好像。
代码
后台我是用laravel-wjfcms写的,这里只展示python爬虫部分的代码,代码微调一下就可以跑起来了。
目录结构如下:
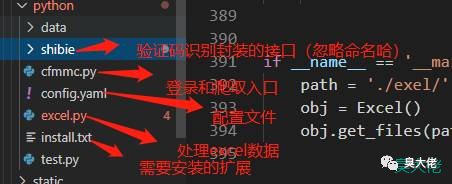
config.yaml是数据库配置文件,格式如下:
mysql_config:
host: 'xxx'
port: 3306
user: 'root'
password: 'sss'
db: 'qihuo'
charset: 'utf8'
登录用户表大概有以下几个字段,根据自己的情况去修改:
CREATE TABLE `wjf_transaction_users` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '交易用户表',
`admin_id` tinyint(4) NOT NULL DEFAULT '0' COMMENT '交易账号对应的管理账号',
`username` varchar(100) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT '' COMMENT '用户名',
`password` varchar(100) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT '' COMMENT '密码',
`status` tinyint(4) NOT NULL DEFAULT '2' COMMENT '状态,1:已验证,2:待验证,3:验证失败',
`created_at` timestamp NULL DEFAULT NULL,
`updated_at` timestamp NULL DEFAULT NULL,
`deleted_at` timestamp NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
KEY `wjf_transaction_users_admin_id_index` (`admin_id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci ROW_FORMAT=COMPACT;
识别接口代码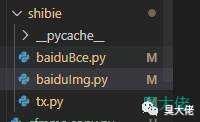
百度API地址:https://ai.baidu.com/ai-doc/OCR/3k3h7yeqa
baiduBce.py
# -*- coding:utf8 -*-
"""
Author: gallopingvijay
Email: 1937832819@qq.com
Website: https://www.choudalao.com
"""
from aip import AipOcr
""" 你的 APPID AK SK """
APP_ID = 'xxx'
API_KEY = 'xxxx'
SECRET_KEY = 'xxxx'
# 需要安装扩展
# pip install baidu-aip
class BaiduBce():
def __init__(self):
self.options = {}
self.setOptions()
self.client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
def dealImg(self, image, type=1, is_local=False):
'''
识别
:param image:图片地址或者url
:param type:识别接口类型
:param is_local:是否为本地,False:远程,True,本地
:return:
'''
if type == 1: # 通用文字识别
if is_local is False:
res = self.client.basicGeneralUrl(image)
else:
res = self.client.basicGeneral(self.get_file_content(image),
self.options)
elif type == 2: # 通用文字识别(高精度版)
if is_local is True:
res = self.client.basicAccurate(self.get_file_content(image))
elif type == 3: # 网络图片文字识别
if is_local is False:
res = self.client.webImageUrl(image)
else:
res = self.client.webImage(self.get_file_content(image))
else:
if is_local is False:
res = self.client.basicGeneralUrl(image)
else:
res = self.client.basicGeneral(self.get_file_content(image),
self.options)
return res['words_result'][0]['words']
def get_file_content(self, filePath):
'''
读取图片
'''
with open(filePath, 'rb') as fp:
return fp.read()
def setOptions(self,
language_type='CHN_ENG',
detect_direction='false',
detect_language='false',
probability='false'):
'''
如果有可选参数
:param language_type:
:param detect_direction:
:param detect_language:
:param probability:
:return:
'''
options = {}
options["language_type"] = language_type
options["detect_direction"] = detect_direction
options["detect_language"] = detect_language
options["probability"] = probability
self.options = options
baiduImg.py
# encoding:utf-8
"""
Author: gallopingvijay
Email: 1937832819@qq.com
Website: https://www.choudalao.com
"""
import requests
import base64
CLIENT_ID = 'xxxx'
CLIENT_SECRET = 'xxxx'
class BaiduImg():
def __init__(self):
self.base_url = 'https://aip.baidubce.com'
self.token = ''
def dealImg(self, path, type=1):
self.getToken()
if type == 1:
# 通用文字识别
request_url = self.base_url + "/rest/2.0/ocr/v1/general_basic"
elif type == 2:
# 位置信息版
request_url = self.base_url + "/rest/2.0/ocr/v1/general"
elif type == 3:
request_url = self.base_url + "/rest/2.0/ocr/v1/accurate_basic"
elif type == 4:
request_url = self.base_url + "/rest/2.0/ocr/v1/accurate"
else:
request_url = self.base_url + "/rest/2.0/ocr/v1/general_basic"
if isinstance(path, bytes):
s = path
else:
# 二进制方式打开图片文件
f = open(path, 'rb')
s = f.read()
img = base64.b64encode(s)
params = {"image": img}
access_token = self.token
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
if response:
res = response.json()
if 'error_msg' in res:
return res['error_msg']
else:
return res['words_result'][0]['words']
def getToken(self):
# client_id 为官网获取的AK, client_secret 为官网获取的SK
host = self.base_url + '/oauth/2.0/token?grant_type=client_credentials&client_id=' + str(
CLIENT_ID) + '&client_secret=' + str(CLIENT_SECRET)
response = requests.get(host)
if response:
data = response.json()
self.token = data['access_token']
print(data['access_token'])
# return data['access_token']
def test(self):
print(11)
# if __name__ == '__main__':
# path = '../code_img/veriCode (1).do'
# baidu = BaiduImg()
# res = baidu.dealImg(path, 3)
# print(res)
tx.py
"""
Author: gallopingvijay
Email: 1937832819@qq.com
Website: https://www.choudalao.com
"""
from tencentcloud.common import credential
from tencentcloud.common.profile.client_profile import ClientProfile
from tencentcloud.common.profile.http_profile import HttpProfile
from tencentcloud.common.exception.tencent_cloud_sdk_exception import TencentCloudSDKException
from tencentcloud.ocr.v20181119 import ocr_client, models
import json
def get_code(path):
try:
cred = credential.Credential(
"xxxx", "xxxx")
httpProfile = HttpProfile()
httpProfile.endpoint = "ocr.tencentcloudapi.com"
clientProfile = ClientProfile()
clientProfile.httpProfile = httpProfile
client = ocr_client.OcrClient(cred, "ap-guangzhou", clientProfile)
req = models.GeneralBasicOCRRequest()
params = '{\"ImageUrl\":\"' + path + '\"}'
req.from_json_string(params)
resp = client.GeneralBasicOCR(req)
res = resp.to_json_string()
res_json = json.loads(res)
if res_json['TextDetections'][0]['DetectedText'] is not None:
code = res_json['TextDetections'][0]['DetectedText']
# print(res_json['TextDetections'][0]['DetectedText'])
return code
except TencentCloudSDKException as err:
print(err)
cfmmc.py


















 2515
2515

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











