







转载自:读DL论文心得之RCNN - liumaolincycle的博客 - 博客频道 - CSDN.NET
http://blog.csdn.net/liumaolincycle/article/details/49787101
之前研究了一段时间,又去做了一段时间的项目,发现以前看的文章都不记得讲了什么,于是又重读一遍,记录下认为重要的地方。 这篇论文是Ross Girshick等发表在CVPR2014上面的Rich feature hierarchies for accurate object detection and semantic segmentation。作者非常好,最近几篇文章的代码都开源了,本篇论文自然也是(代码在此),还有一个很棒的slides。
overview
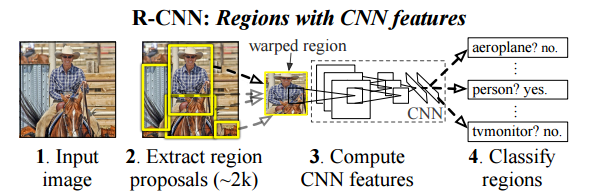
首先对每一个输入图像都用selective search算法提取大约2000个建议框,对每一个建议框进行简单粗暴的变形,即先在周围加16个像素的边框,边框像素值为该图像的平均值,再变形为227*227的大小。对每一个变形后的建议框计算一次CNN特征,再用一个SVM分类器进行分类。
dataset
本文提出一种十分有效的解决有标签的训练数据太少的方法,先在ImageNet上有监督地预训练,再在小数据集PASCAL上微调。
在微调时,与Ground Truth的IoU交叠≥0.5的区域建议框,认为是正样本,其他的是负样本,这样也扩大了数据集。
但是注意,在SVM训练时,经过验证发现,与Ground Truth的IoU交叠<0.3的区域建议,认为是负样本,Ground Truth就是正阳本,其他的忽略。作者在补充材料中做出了猜想,认为可能是SVM的训练样本需要精确的定位。
bounding box regression
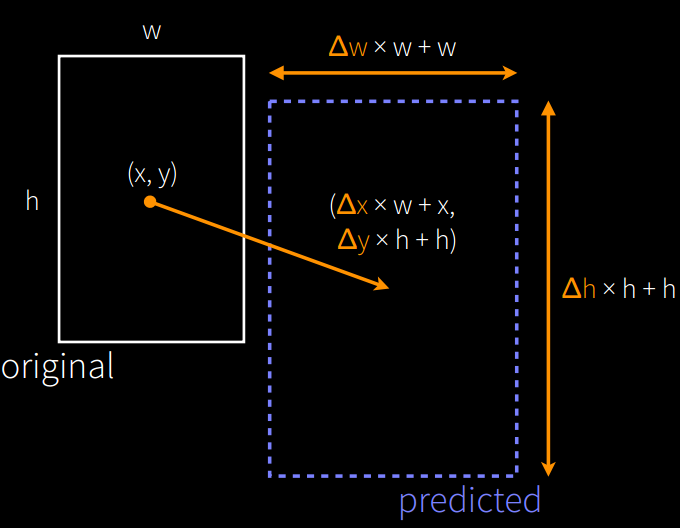
包围盒回归也在补充材料中详细给出了,我描述起来有点复杂,它的主要目标是找到一个从建议框(proposal)P到实际标注框(Ground Truth)G之间的一个映射变换,通过优化一个回归函数来获得最优参数。当然也不是对所有建议框都做这样的回归,而是只对与Ground Truth的IoU交叠大于一个阈值的建议框进行回归。
non-maximum suppression
之前不太明白非极大值抑制这个看起来很专业的操作是在做什么,实际上非常简单,就是设定一个阈值,如果后到的一个区域比先到的一个区域之间的IoU交叠大于这个阈值,而得分却没有前一个区域高,就舍弃这个后到区域。
run-time
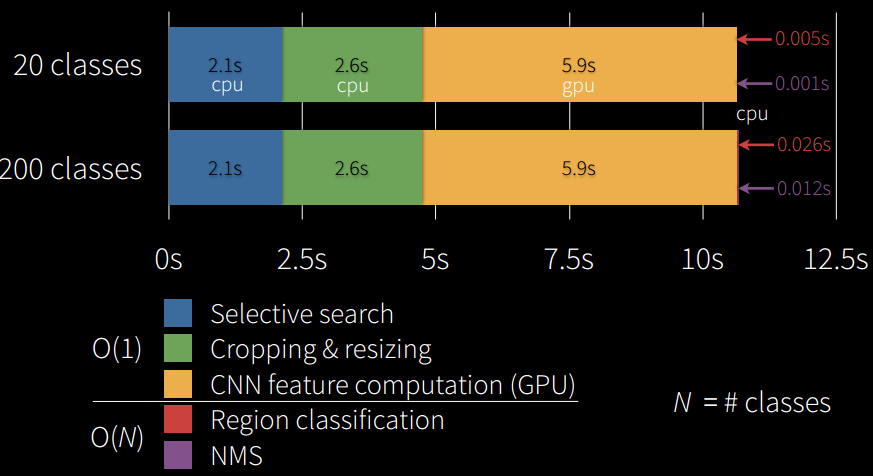
现在来看,这个速度是很慢的,但是不能不承认RCNN打开了图像目标检测新世界的大门,也占领了数据检测基准的高点,后来者再难在mAP上有很大突破,只能在速度提升上下功夫。
result
| \ | VOC2007 | VOC2010 |
|---|---|---|
| RCNN | 54.2% | 50.2% |
| RCNN+BB | 58.5% | 53.7% |















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









