







 本文深入探讨了Transformer模型,核心在于Attention机制,包括self-attention和multi-head attention。Transformer作为一个Seq2Seq模型,由encoder和decoder组成,各包含特定的sub-layers。Attention机制通过计算Query、Key和Value之间的关系,动态地权重输入信息,解决了传统神经网络长距离依赖的问题。
本文深入探讨了Transformer模型,核心在于Attention机制,包括self-attention和multi-head attention。Transformer作为一个Seq2Seq模型,由encoder和decoder组成,各包含特定的sub-layers。Attention机制通过计算Query、Key和Value之间的关系,动态地权重输入信息,解决了传统神经网络长距离依赖的问题。
-
借助Attention机制提高神经网络对于信息处理能力
Attention 机制主要分为两部分 第一部分:self-attention (提高注意力方式),第二部分:transformer(定义encode-decode 过程)
如下所示:
Attention机制实质寻址过后过程 给定一个查询向量Q,通过计算与Key的注意力并附加到value,得到Attention Value
优点: 不需要计算所有的N的输入信息到神经网络中进行计算,从X中选择一些与任务相关信息输入到神经网络中- 信息输入
- 计算注意力分布A,A = Softmax(s(key,q))
- 根据注意力分布A来计算信息加权平均
Attention 机制 在 RNN,CNN 解决输入序列长距离依赖问题
传统的神经网络中,想要建立输入序列之间长距离依赖 使用两种方法: 第一种方法增加网络层数,利用深层神经网络远距离信息交互; 第二中方式:使用权连接网络(无法处理变长序列,不同输入长度,连接权重大小相同)
采用 Self-Attetntion 动态生成不用连接权重,从而处理变长信息序列。Attention 机制函数计算原理:
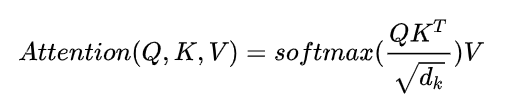
Q 表示Query,k(Key), V(Value) ,
key == value 普通模型, Key!= Value 键值对的模型
4. Q与K dot 点乘,防止结果过大 会除以一个尺度标度 d k \sqrt{d_k} dk , d k d_k dk 为query和key 向量维度
5. 利用Softmax将结果归一化成概率分布
6. 乘以矩阵V 得到权重求和
Transfomer (Attention Is All You Need) 详解
transformer的 核心机制Attention
Transformer 本质是一个Seq2Seq 模型,左边一个encoder 把输入读进,右边将decoder得到输出
** Transformer encode **:
sub-layer-1: multi-head self attention mechanism, 用来进行self-attention
sub-layer-2: Position-wise Feed-foeward Network , 简单全连接网络,对每个position 的向量分别进行相同操作(线性变换+ RELU激活层(输入出层512,中间层2048))
每个sub-layer 实验残差网络 LayerNorm(X+ sublayer(X))
* * Transformer Decoder **:
sub-layer-1 : 使用 self-attention 需要做mask
sub-layer-2: Positionn-wise Feed -forward Network 同 Encode
sub-layer-3: Encoder-Decoder attention 计算
- Encoder-Decoder attention VS self-attention
使用multi-head 不过Encoder-Decoder attention 采用传统的attention机制,其中的Query是self-attention mechanism已经计算出的上一时间i处的编码值,Key和Value都是Encoder的输出,这与self-attention mechanism不同
multi-head attention
basic attention 使用scaled dot-product attention, 下面的例子
example:
use the RNN with Attention
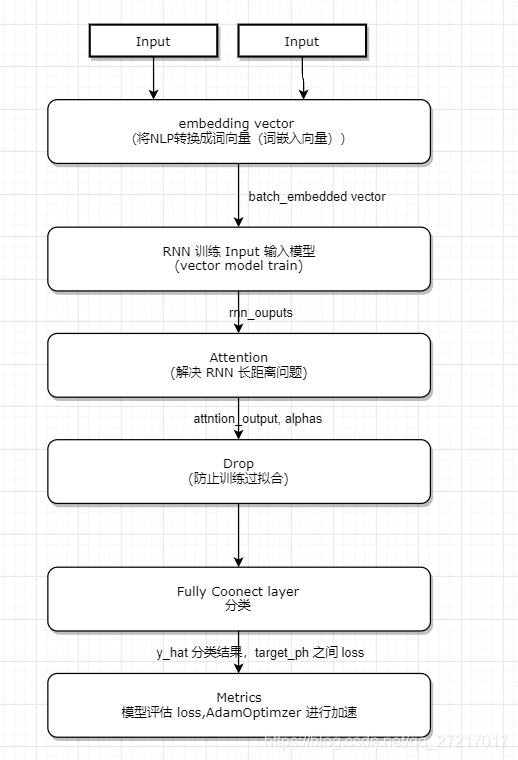
"""
Toy example of attention layer use
Train RNN (GRU) on IMDB dataset (binary classification)
Learning and hyper-parameters were not tuned; script serves as an example
"""
from __future__ import print_function,division
import numpy as np
import tensorflow as tf
from tensorflow.contrib.rnn import GRUCell
from tensorflow.python.ops.rnn import bidirectional_dynamic_rnn as bi_rnn
from tqdm import tqdm
from Attention.attention import attention
import Attention.imdb as imdb
from Attention.utils import get_vocabulary_size, fit_in_vocabulary, zero_pad, batch_generator
NUM_WORDS = 10000
INDEX_FROM = 3
SEQUENCE_LENGTH = 250
EMBEDDING_DIM = 100
HIDDEN_SIZE = 150
ATTENTION_SIZE = 50
KEEP_PROB = 0.8
BATCH_SIZE = 256
NUM_EPOCHS = 3 # Model easily overfits without pre-trained words embeddings, that's why train for a few epochs
DELTA = 0.5
MODEL_PATH = './model'
NUM_WORDS = 10000
INDEX_FROM = 3
SEQUENCE_LENGTH = 250
EMBEDDING_DIM = 100
HIDDEN_SIZE = 150
ATTENTION_SIZE = 50
KEEP_PROB =  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









