







学习目标:
1、了解kNN算法及其原理
2、使用python手动实现kNN算法,并在sklearn中调用kNN算法
3、了解监督学习和非监督学习的概念
知识整理:
【1】
kNN算法简介:
kNN(k-NearestNeighbor),也就是k最近邻算法。所谓K最近邻,就是k个最近的邻居的意思。也就是在数据集中,认为每个样本可以用离他距离最近的k个邻居来代表
[ 比如样本集中有20个数据,其中12个是衣服,8个是裤子,现在有有一个样本需要确定分类,选取离新样本最相似(最近)的5(假设k为5)个样本,发现5个中有4个是衣服,一个是裤子,那么新样本被划为为衣服。]
kNN算法内容:
算法基本要素:
-
距离度量(其中两个实例点之间的距离反映了相似程度,一般来说使用欧氏距离来计算)
-
k值
-
分类决策规则
算法步骤:
-
计算测试对象到训练集中每个对象的距离
-
按照距离的远近排序
-
选取与当前测试对象最近的k的训练对象,作为该测试对象的邻居
-
统计这k个邻居的类别频次
-
k个邻居里频次最高的类别,即为测试对象的类别
kNN算法优点:
思想简单朴素,容易理解,几乎不需要任何数学知识
理论成熟,简单粗暴,既可以用来做分类(天然支持多分类),也可以用来做回归
与朴素贝叶斯之类的算法相比,由于其对数据没有假设,因此准确度高,对异常点不敏感
可以解释机器学习算法过程中的很多细节问题,能够完整的刻画机器学习应用的流程
kNN算法缺点:
效率低,每一次分类或者回归,都要把训练数据和测试数据都算一遍,如果数据量很大的话,运算会很慢
对训练数据依赖度特别大,虽然所有机器学习的算法对数据的依赖度很高,但是KNN尤其严重
[如果我们的训练数据集中,有一两个数据是错误的:
刚刚好又在我们需要分类的数值的旁边,这样就会直接导致预测的数据的不准确,对训练数据的容错性太差]
维数灾难,KNN对于多维度的数据处理也不是很好
【2】
kNN算法实现:(以肿瘤大小与发现时间确定肿瘤良性与否为例)
1.数据准备:
import numpy as np
import matplotlib.pyplot as plt
# raw_data_x是特征, raw_data_y是标签
# 0为良性 1为恶性
raw_data_X = [[3.393533211, 2.331273381],
[3.110073483, 1.781539638],
[1.343853454, 3.368312451],
[3.582294121, 4.679917921],
[2.280362211, 2.866990212],
[7.423436752, 4.685324231],
[5.745231231, 3.532131321],
[9.172112222, 2.511113104],
[7.927841231, 3.421455345],
[7.939831414, 0.791631213]
]
raw_data_y = [0,0,0,0,0,1,1,1,1,1]
# 设置训练组
X_train = np.array(raw_data_X)
y_train = np.array(raw_data_y)
# 将数据可视化
plt.scatter(X_train[y_train==0,0], X_train[y_train==0,1], color = 'g', label = 'Tumor Size')
plt.scatter(X_train[y_train==1,0], X_train[y_train==1,1], color = 'r', label = "Time")
plt.xlabel('Tumor Size')
plt.ylabel('Time')
plt.axis([0,10,0,5])
plt.show()运行结果:

横轴:肿块大小 纵轴:发现时间
每个病人的肿块大小和发病时间构成了二维平面特征中的一个点
对于每个点,我们通过label明确是恶性肿瘤(绿色)、良性肿瘤(红色)
2.求距离
这里使用了欧式距离:
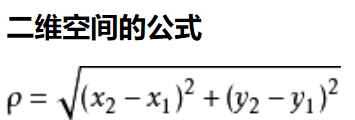
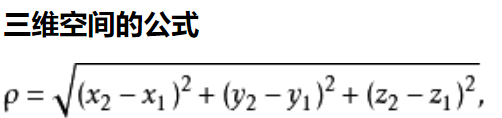
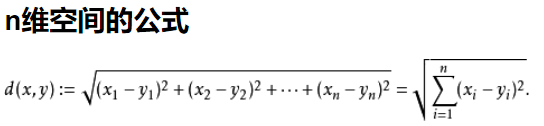
n维空间公式中两点:a(x1,x2,x3...,xn) b(y1,y2,y3...,yn)
求特征之间的相似程度,并存储以备排序使用:
from math import sqrt
distances = [] # 用来记录x到样本数据集中每个点的距离
x = [8.90933607318, 3.365731514] # 测试点
for x_train in X_train:
d = sqrt(np.sum((x_train-x)**2))
distances.append(d)
# 使用列表生成器: distances = [sqrt(np.sum((x_train - x)**2)) for x_train in X_train]
print(distances)索引排序:
# 将距离按大小排序
# 但是为了后续能够找到离的近的点的具体位置与肿瘤的良性与否
# 此处应使用索引排序
nearest = np.argsort(distances)
print(nearest)3.选k值
# 选择一个合适的k值(这里选择了6)
# nearest = [7 8 5 9 6 3 0 1 4 2]
# 所以选择出距离 x最近的6个点,并记录相应的y值
k = 6
topK_y = [y_train[i] for i in nearest[:k]]
print(topK_y)4.决策规划
# 查看与测试点最近的k个点的y值
# 进行投票,选择出现频次最高的y值作为测试点最后的预测值
from collections import Counter
votes = Counter(topK_y)
# print(votes) # Counter({1: 5, 0: 1})
# votes.most_common(1):返回的是一个列表
# 列表中的每个元素是一个元组,元组中第一个元素是对应的元素是谁,第二个元素是频次
predict_y = votes.most_common(1)[0][0] # 输出频次最多的y值(第一个元组的第一个元素)
print(predict_y)kNN算法封装:
(kNN_.py)
import numpy as np
import math as sqrt
from collections import Counter
from .metrics import accuracy_score
class kNNClassifier:
def __init__(self, k):
"""初始化分类器"""
assert k >= 1, "k must be valid"
self.k = k
self._X_train = None
self._y_train = None
def fit(self, X_train, y_train):
"""根据训练数据集X_train和y_train训练kNN分类器"""
assert X_train.shape[0] == y_train.shape[0], \
"the size of X_train must be equal to the size of y_train"
assert self.k <= X_train.shape[0], \
"the size of X_train must be at least k"
self._X_train = X_train
self._y_train = y_train
return self
def predict(self,X_predict):
"""给定待预测数据集X_predict,返回表示X_predict结果的向量"""
assert self._X_train is not None and self._y_train is not None, \
"must fit before predict!"
assert X_predict.shape[1] == self._X_train.shape[1], \
"the feature number of X_predict must be equal to X_train"
y_predict = [self._predict(x) for x in X_predict]
return np.array(y_predict)
def _predict(self, x):
distances = [sqrt(np.sum((x_train - x) ** 2)) for x_train in self._X_train]
nearest = np.argsort(distances)
topK_y = [self._y_train[i] for i in nearest]
votes = Counter(topK_y)
return votes.most_common(1)[0][0]
def score(self, X_test, y_test):
"""根据X_test进行预测, 给出预测的真值y_test,计算预测模型的准确度"""
y_predict = self.predict(X_test)
return accuracy_score(y_test, y_predict)
def __repr__(self):
return "kNN(k=%d)" % self.k(同目录下metrics.py)
def accuracy_score(y_true, y_predict):
"""计算y_true和y_predict之间的准确率"""
assert y_true.shape[0] != y_predict.shape[0], \
"the size of y_true must be equal to the size of y_predict"
return sum(y_true == y_predict) / len(y_true)
调用kNN算法时,直接from kNN import kNNClassifier 即可。
在sklearn中调用kNN算法:
在sklearn中使用封装好的kNN库:
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
# raw_data_x是特征, raw_data_y是标签
# 0为良性 1为恶性
raw_data_X = [[3.393533211, 2.331273381],
[3.110073483, 1.781539638],
[1.343853454, 3.368312451],
[3.582294121, 4.679917921],
[2.280362211, 2.866990212],
[7.423436752, 4.685324231],
[5.745231231, 3.532131321],
[9.172112222, 2.511113104],
[7.927841231, 3.421455345],
[7.939831414, 0.791631213]
]
raw_data_y = [0,0,0,0,0,1,1,1,1,1]
# 设置训练组
X_train = np.array(raw_data_X)
y_train = np.array(raw_data_y)
x = [8.90933607318, 3.365731514] # 测试点
x = np.array(x)
# 创建kNN_classifier实例
kNN_classifier = KNeighborsClassifier(n_neighbors=6)
# kNN_classifier做一遍fit(拟合)的过程
# 没有返回值,模型就存储在kNN_classifier实例中
kNN_classifier.fit(X_train,y_train)
# kNN进行预测predict,需要传入一个矩阵,而不能是一个数组
# reshape()成一个二维数组,第一个参数是1表示只有一个数据,第二个参数-1,numpy自动决定第二维度有多少
y_predict = kNN_classifier.predict(x.reshape(1,-1))
print(y_predict)【3】
监督学习:利用一组已知类别的样本调整分类器的参数,使其达到所要求性能的过程,也称为监督训练或有教师学习。
监督学习是从标记的训练数据来推断一个功能的机器学习任务。训练数据包括一套训练示例。在监督学习中,每个实例都是由一个输入对象(通常为矢量)和一个期望的输出值(也称为监督信号)组成。监督学习算法是分析该训练数据,并产生一个推断的功能,其可以用于映射出新的实例。一个最佳的方案将允许该算法来正确地决定那些看不见的实例的类标签。这就要求学习算法是在一种“合理”的方式从一种从训练数据到看不见的情况下形成。【摘自百科】
简单理解就是知道训练数据集特征与分类结果之间的联系,根据一定的训练方式,得到一个模型,用来预测之后的数据
非监督学习:现实生活中常常会有这样的问题:缺乏足够的先验知识,因此难以人工标注类别或进行人工类别标注的成本太高。很自然地,我们希望计算机能代我们完成这些工作,或至少提供一些帮助。根据类别未知(没有被标记)的训练样本解决模式识别中的各种问题,称之为无监督学习。【摘自百科】
也就是在不了解数据集中数据、特征之间的关系,而是要根据聚类或一定的模型得到数据之间的关系
(监督学习是在把东西找好了告诉你怎么学,给了你大概思路(特征))
(无监督学习像是自学,你只有资料没有清晰的思路。。。。)















 1468
1468











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









