







Seq2Seq模型
模型原理
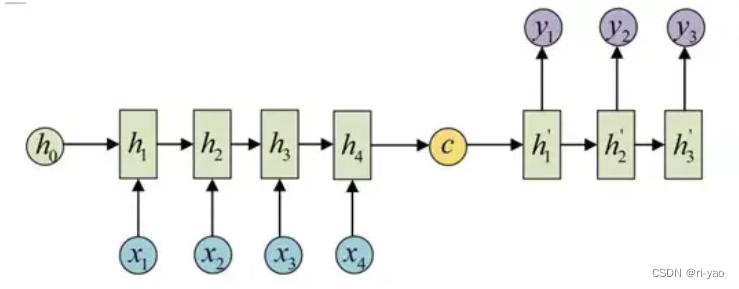
序列到序列模型,也称encoder-decoder模型。
其中Seq2Seq(序列到序列),强调目的,将输入序列转化为输出序列;
Encoder-Decoder(编码器-解码器),强调模型实现的方法。
1)Encoder部分:将输入序列转化为固定长度的上下文向量;
在每个时间步,读入输入序列的一个元素,并更新隐藏层状态,并将最终的隐藏层状态或其变换作为上下文向量。
2)Decoder部分:将上下文向量转化为输出序列;
在每个时间步,基于上一时间步的输出、隐藏层状态、上下文向量来生成当前时间步的输出;
具体实现
编码器
class Encoder(nn.Module):
def __init__(self,input_size,hidden_size,num_layers,batch_size):
super().__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.num_layers = num_layers
self.batch_size = batch_size
self.num_directions = 1
self.lstm = nn.LSTM(self.input_size,self.hidden_size,self.num_layers,batch_first=True,bidirectional=False)
def forward(self,input_seq):
h_0 = torch.randn(self.num_directions*self.num_layers,self.batch_size,self.hidden_size).to(device)
c_0 = torch.randn(self.num_directions * self.num_layers, self.batch_size, self.hidden_size).to(device)
output,(h,c) = self.lstm(input_seq,(h_0,c_0))
return h,c解码器
class Decoder(nn.Module):
def __init__(self,input_size,hidden_size,num_layers,output_size,batch_size):
super().__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.num_layers = num_layers
self.output_size = output_size
self.batch_size = batch_size
self.num_directions = 1
self.lstm = nn.LSTM(self.input_size,self.hidden_size,self.num_layers,batch_first=True,bidirectional=False)
self.linear = nn.Linear(self.hidden_size, self.input_size)
def forward(self,input_seq,h,c):
input_seq = input_seq.unsqueeze(1)
output,(h,c) = self.lstm(input_seq,(h,c))
pred = self.linear(output.squeeze(1))
return pred,h,cSeq2Seq
class Seq2Seq(nn.Module):
def __init__(self,input_size,hidden_size,num_layers,output_size,batch_size):
super().__init__()
self.input_size = input_size
self.output_size = output_size
self.batch_size = batch_size
self.encoder = Encoder(input_size,hidden_size,num_layers,batch_size)
self.decoder = Decoder(input_size, hidden_size, num_layers, output_size, batch_size)
def forward(self,input_seq):
target_len = self.output_size
h,c = self.encoder(input_seq)
outputs = torch.zeros(self.batch_size,self.input_size,self.output_size).to(device)
decoder_input = input_seq[:,-1,:]
for t in range(target_len):
decoder_output,h,c = self.decoder(decoder_input,h,c)
outputs[:,:,t] = decoder_output
decoder_input = decoder_output
return outputs[:,0,:]单元测试
model = Seq2Seq(1,32,2,2,2)
test_input = torch.tensor([[70, 80, 90],[70, 80, 90]]).float().unsqueeze(2) # 输入最后3个时间步
predicted_output = model(test_input)
print(predicted_output)基于Seq2Seq实现一元多步时间序列预测
数据来源
天池-某地区电网某地区电网2018年1月1日至2021年8月31日间隔 15 分钟的电力系统负荷数据,链接为:电网_数据集-阿里云天池 (aliyun.com)
任务描述
通过24个时刻的数据预测未来12个时刻的数值
模型参数
def get_parameters():
para_dict = {
"input_size":1,
"output_size":12,
"batch_size":10,
"hidden_size":32,
"num_layers":2,
"seq_len":24,
"modelpara_path":'md.pth',
"loss_function":'mse',
"optimizer":'Adam',
"lr":0.0001,
"epoch":250,
}
return para_dict数据读取
注意事项:
标签读取部分与基于Pytorch+LSTM实现一元单步时间序列预测(保姆级教程)-CSDN博客
略有改动,其余部分相同。
def read_data(filename):
data = pd.read_csv(filename,skiprows=1)
data.head(5)
L = data.shape[0]
print("data的尺寸为:{}".format(data.shape))
# print("文件中有nan行共{}行".format(data.isnull().sum(axis=1)))
return data,L
def process_data(data,N,m):
XY=[]
for i in range(len(data) - N-m):
X = []
Y = []
for j in range(N):
X.append(data.iloc[i+j, 1])
for j in range(N+1,N+1+m):
Y.append(data.iloc[i+j, 1])
X = torch.FloatTensor(X).view(-1,1)
Y = torch.FloatTensor(Y).view(-1,1)
XY.append((X,Y))
return XY
# Dataset是一个抽象类,需要进行继承实现,len获取数据集大小,getitem根据索引获取数据
class MyDataset(Dataset):
def __init__(self,data):
self.data = data
def __getitem__(self, item):
return self.data[item]
def __len__(self):
return len(self.data)
def data_loader(data,N,m,batch_size,shuffle):
seq = process_data(data, N,m)
seq_set = MyDataset(seq)
seq = DataLoader(dataset=seq_set,batch_size=batch_size,shuffle=shuffle,drop_last=True)
return seq_set,seq模型训练
def train_proc(para_dict,train_data,val_data):
input_size=para_dict["input_size"]
hidden_size = para_dict["hidden_size"]
num_layers = para_dict["num_layers"]
output_size = para_dict["output_size"]
batch_size = para_dict["batch_size"]
lr = para_dict["lr"]
epoch = para_dict["epoch"]
model = Seq2Seq(input_size,hidden_size,num_layers,output_size,batch_size)
model.to(device)
#优化器保存当前的状态,并可以进行参数的更新
if para_dict["optimizer"]=='Adam':
optimizer = torch.optim.Adam(model.parameters(),lr)
if para_dict["loss_function"]=='mse':
loss_function = nn.MSELoss()
best_model = None
min_val_loss = float('inf')
train_loss = []
val_loss = []
for i in tqdm(range(epoch)):
train_loss_tmp = 0
val_loss_tmp = 0
# 训练
model.train()
for curdata in train_data:
seq, label = curdata
seq = seq.to(device)
label = label.to(device)
# 计算网络输出
y_pred = model(seq)
y_pred = y_pred.unsqueeze(2)
# 计算损失
loss = loss_function(y_pred,label)
train_loss_tmp += loss.item()
# 计算梯度和反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 验证
model.eval()
for (seq, label) in val_data:
seq = seq.to(device)
label = label.to(device)
with torch.no_grad():
y_pred = model(seq)
y_pred = y_pred.unsqueeze(2)
loss = loss_function(y_pred,label)
val_loss_tmp += loss.item()
# 最优模型
if val_loss_tmp<min_val_loss:
min_val_loss = val_loss_tmp
best_model = copy.deepcopy(model)
#损失保存
train_loss_tmp /= len(train_data)
val_loss_tmp /= len(val_data)
train_loss.append(train_loss_tmp)
val_loss.append(val_loss_tmp)
print("epoch={:03d}: train_loss = {:05f},val_loss = {:05f}".format(i,train_loss_tmp,val_loss_tmp))
# 绘制损失曲线
plt.figure()
plt.plot(range(epoch),train_loss,'r')
plt.plot(range(epoch), val_loss, 'b')
plt.legend(['train','val'])
plt.savefig('seq2seq_loss.svg',format='svg')
plt.show()
#保存模型
state = {'models':best_model.state_dict()}
torch.save(state,para_dict["modelpara_path"])模型测试
def test_proc(para_dict,test_data,min_val,max_val):
input_size=para_dict["input_size"]
hidden_size = para_dict["hidden_size"]
num_layers = para_dict["num_layers"]
output_size = para_dict["output_size"]
batch_size = para_dict["batch_size"]
lr = para_dict["lr"]
epoch = para_dict["epoch"]
path = para_dict["modelpara_path"]
model = Seq2Seq(input_size,hidden_size,num_layers,output_size,batch_size)
model.to(device)
print("loading models ......")
model.load_state_dict(torch.load(path)['models'])
model.eval()
pred = []#list
labels = []
for curdata in test_data:
seq, label = curdata
seq = seq.to(device)
label = label.to(device)
with torch.no_grad():
y_pred = model(seq)
for j in range(len(y_pred)):
for k in range(output_size):
y = y_pred[j][k].item()*(max_val-min_val)+min_val
lb = label[j][k].item()*(max_val-min_val)+min_val
pred.append(y)
labels.append(lb)
errs = np.array(pred)-np.array(labels)
mape = abs(errs/np.array(labels)).sum()/len(errs)
print('预测结果:MAPE={:.3f}%'.format(mape*100))
# 绘制预测对比曲线
plt.figure()
plt.plot(pred,'r')
plt.plot(labels, 'b')
plt.legend(['pred','labels'])
plt.show()
plt.figure()
plt.plot(errs)
plt.savefig('seq2seq_err.svg', format='svg')
plt.show()
return errs主程序
import numpy as np
import pandas as pd
import torch
from torch.utils.data import Dataset,DataLoader
import torch.nn as nn
from tqdm import *
import copy
import matplotlib.pyplot as plt
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
if __name__ == '__main__':
filename = "complete_data.csv"
data,L = read_data(filename)
# 归一化
min_val = min(data.iloc[:,1])
max_val = max(data.iloc[:,1])
data.iloc[:, 1] = (data.iloc[:,1]-min_val)/(max_val-min_val)
train_pro = 0.9
val_pro = 0.95
test_pro = 1
train = data.loc[:len(data)*train_pro,:]
val = data.loc[len(data)*train_pro+1:len(data)*val_pro,:]
test = data.loc[len(data)*val_pro+1:len(data)*test_pro,:]
print("训练集的大小为{}".format(train.shape))
print("验证集的大小为{}".format(val.shape))
#print("测试集的大小为{}".format(test.shape))
para_dict = get_parameters()
batch_size = para_dict["batch_size"]
N = para_dict["seq_len"]
m = para_dict['output_size']
train_data_set,train_data = data_loader(train,N,m,batch_size,True)
print('训练数据导入完毕!')
val_data_set,val_data = data_loader(val, N,m,batch_size,True)
print('验证数据导入完毕!')
test_data_set,test_data = data_loader(test, N,m,batch_size,False)
print('测试数据导入完毕!')
print("开始训练")
train_proc(para_dict,train_data,val_data)
print("开始测试")
errs = test_proc(para_dict, test_data,min_val,max_val)训练效果
MAPE=2.095%
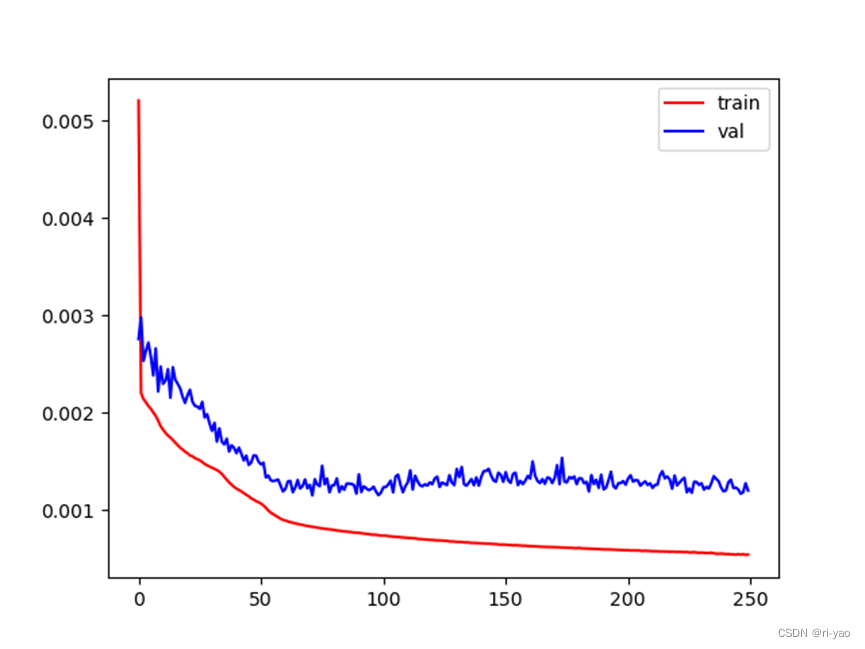
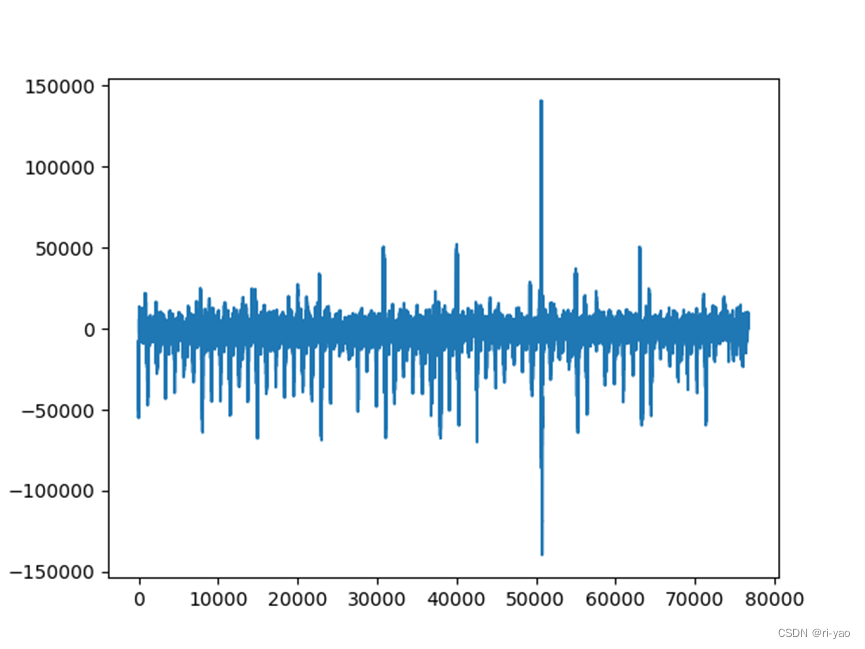
loss曲线 误差曲线
对时间序列预测的思考
基本问题描述
输入:
输出:
多步预测的策略
(1)直接输出多步预测:
(Batch_size,M)
缺点:没有考虑不同时刻的关联
(2)多个单步预测
预测M步,训练M个模型,每个模型为单步。
模型1:输入,输出
模型2:输入,输出
模型M:输入,输出
缺点:需要训练多个模型,长时间间隔的预测不准
(3)递归预测
通过滑动窗口,预测未来M步。
第一步:输入,输出
第二步:输入,输出
第M步:输入,输出
优点:可基于Seq2Seq模型实现,建模了时刻间的依赖关系
缺点:存在误差累积
多元预测问题
input_size=n
如实现传感器A和B 的预测,历史结果有A:[1,5,8,3,2,3],B:[3,6,0,7,5,8],则可通过建模为(1,3),(5,6),(8,0)....为6个时刻的输入即可。
Seq2Seq模型在时间序列预测中的优势
- 框架灵活,支持不定长的输入与输出;
- 考虑了输出标签的序列依赖性















 5480
5480

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









