







python发展
随着近几年来机器学习和人工智能的高速发展,python编程语言逐渐成为最热门语言。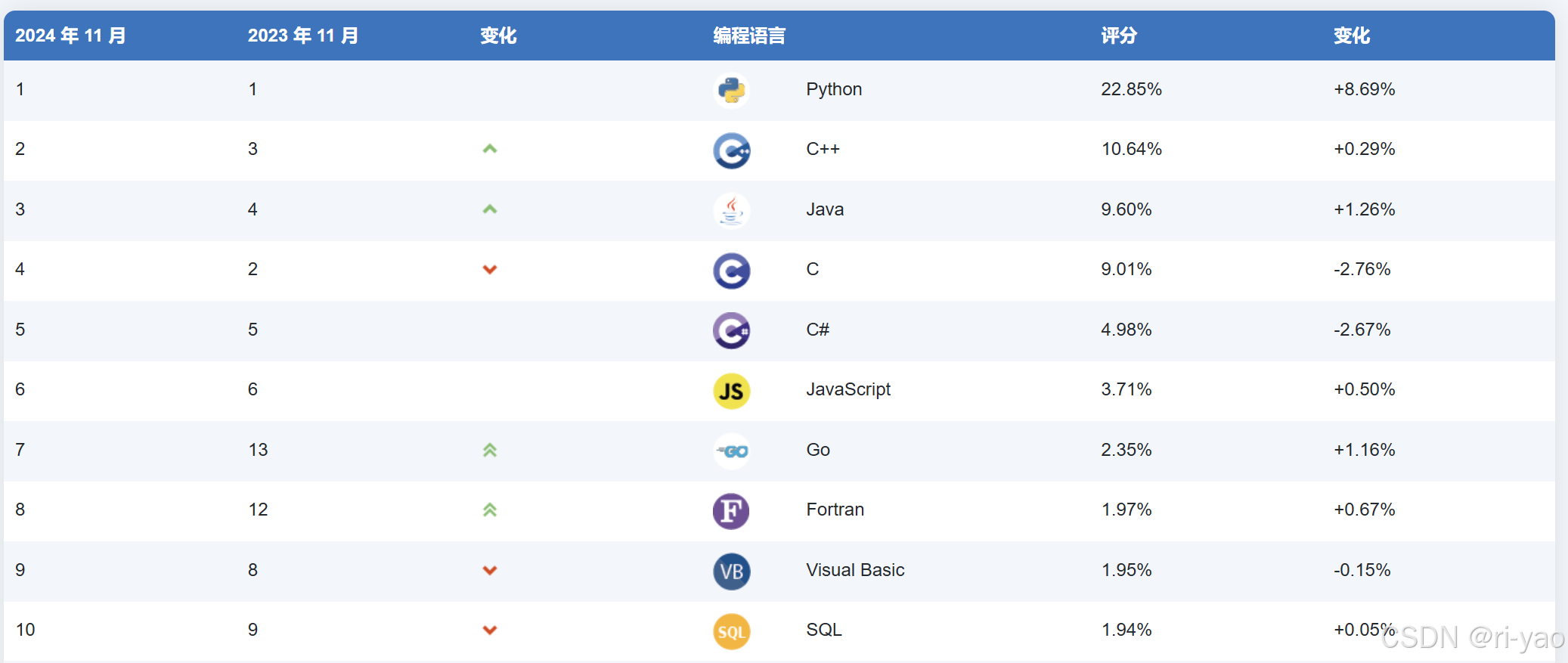
图1 TIOBE 编程社区指数
常用数据结构
- 元组(tuple):异构数据存储,不可变,以()表示;
- 列表(list):异构数据存储,可变,以[ ]表示;
- 集合(set):唯一的元素的无序集合,以{ }表示;
- 字典(dict):键值对的集合,键是唯一且不可变的对象;
代码示例
a=(1,2,'3') #tuple
b=[1,2,'3'] #list
c={1,2,3} #set
d ={'1':1,'2':2} #dict
元组和列表的区别?
列表是动态数组;元组是静态数组,一旦创建无法改变,存储更高效。
数组和列表如何选择?
元素序列很长或需要数值运算,采用数组;元素序列很短且不需要数值计算,采用列表。
对列表的操作
切片

添加
- insert:在指定位置添加元素(pos,num)
- append:在末尾添加元素
- extend:在末尾一次性追加多个值

删除
- remove:删除指定值的第一个元素
- del:删除指定位置的元素
- pop:删除末尾元素

运算
- +:拼接两个列表
- *:复制列表元素

函数
- index():某个元素第一次出现的索引
- count():统计某个值的次数
- sort():排序
- reverse():反转

列表推导式

更改类型

range、arange、linspace
- range(start,stop,step),返回object,不支持小数步长
- arange(start,stop,step),返回ndarray类型,支持小数步长
- linspace(start,stop,n)
注意:python中range和arange是左闭右开区间!

常用第三方库
numpy
科学计算基础库,包含矩阵、数组计算,加减乘除、三角函数、指数函数、随机数等数学函数。
库导入
import numpy as np
创建数组
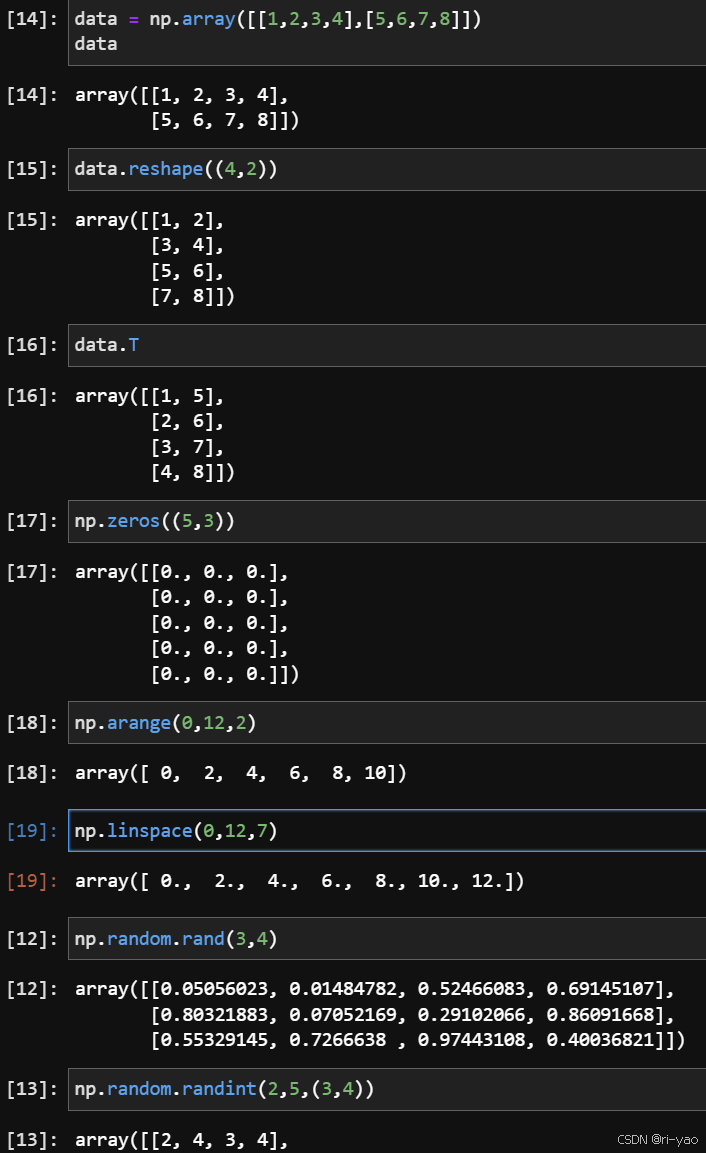
数组展示
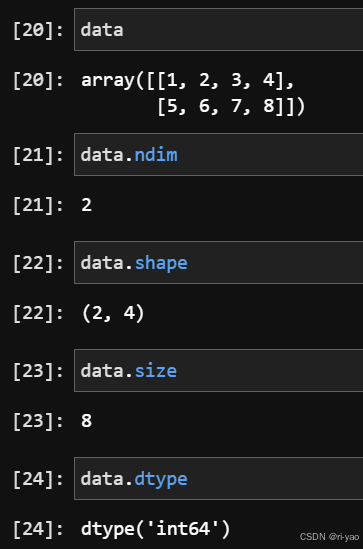
数组运算
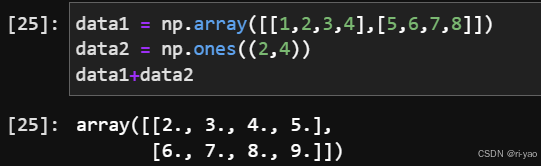
数据统计
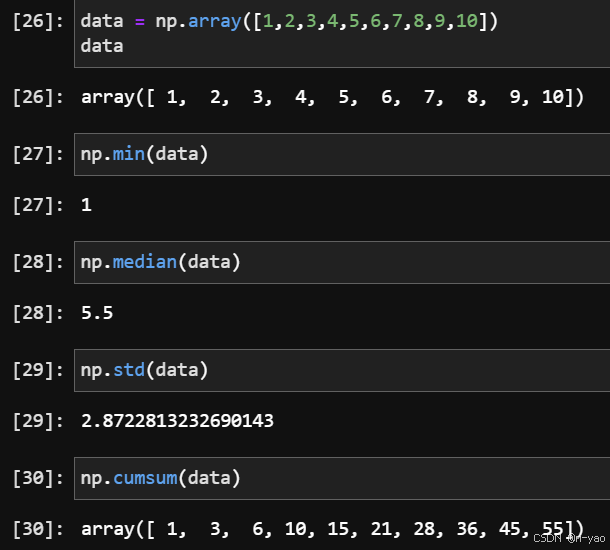
数组的切片和索引
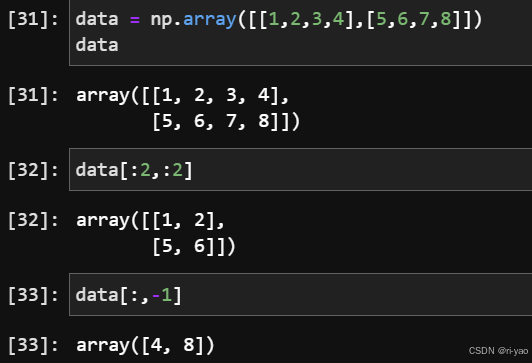
数组堆叠
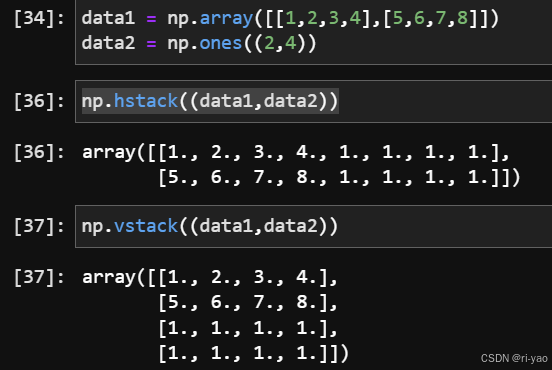
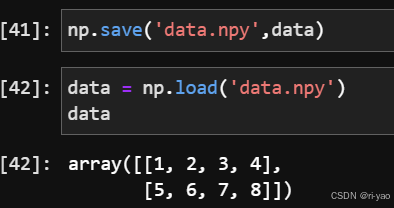
数组的保存和加载
参考:numpy详细教程(涵盖全部,看这一篇就够了)-CSDN博客
matplotlib.pyplot
import matplotlib.pyplot as plt
# 显示中文
plt.rcParams["font.family"]="SimHei"
# 绘图
fig=plt.figure(num=1,figsize=(4,4))
ax=fig.add_subplot(111)
ax.plot([1,2,3,4],[1,2,3,4])
plt.show()
#设置刻度范围
ax.set_xlim(1,7.1)#x轴从1到7.1
ax.set_ylim(40,100)#y轴从40到100
#设置显示的刻度
ax.set_xticks(np.linspace(1,7,7))#np.linspace()函数为等差数列,1至7的7个数组成的等差数列1,2,3,4,5,6,7,
ax.set_yticks(np.linspace(50,100,6))#关于等差数列,想了解的可以参看numpy的用法
#设置刻度标签
ax.set_xticklabels(["星期一","星期二","星期三","星期四","星期五","星期六","星期日"],fontproperties="SimHei"\
,fontsize=12)
#这里用到了属性fontproperties可以单独设置x轴标签的字体,也可以用fontsize设置字体大小,还可以用color设置字的颜色
ax.set_yticklebels(["50kg","60kg","70kg","80kg","90kg","100kg"],fontsize=12)
# 设置坐标标签
ax.set_xlabel("星期")#添加x轴坐标标签,后面看来没必要会删除它,这里只是为了演示一下。
ax.set_ylabel("销售量",fontsize=16)#添加y轴标签,设置字体大小为16,这里也可以设字体样式与颜色
ax.set_title("某某水果店一周水果销售量统计图",fontsize=18,backgroundcolor='#3c7f99',\
fontweight='bold',color='white',verticalalignment="baseline")#标题(表头)
# 网格
plt.grid()
# 图例
ax.plot(x,app,label="苹果")
ax.legend(loc=3,labelspacing=2,handlelength=3,fontsize=14,shadow=True)
ax.legend(("苹果"),loc=3,labelspacing=2,handlelength=4,fontsize=14,shadow=True)
# 保存图片
plt.savefig("figure.png")
# 多种图示
matplotlib.pyplot.scatter(x, y, s=None, c=None, marker=None, cmap=None, norm=None, vmin=None, vmax=None, alpha=None, linewidths=None, *, edgecolors=None, plotnonfinite=False, data=None, **kwargs)
matplotlib.pyplot.bar(x, height, width=0.8, bottom=None, *, align='center', data=None, **kwargs)
matplotlib.pyplot.hist(x, bins=None, range=None, density=False, weights=None, cumulative=False, bottom=None, histtype='bar', align='mid', orientation='vertical', rwidth=None, log=False, color=None, label=None, stacked=False, **kwargs)
imshow(X, cmap=None, norm=None, aspect=None, interpolation=None, alpha=None, vmin=None, vmax=None, origin=None, extent=None, shape=None, filternorm=1, filterrad=4.0, imlim=None, resample=None, url=None, *, data=None, **kwargs)
seaborn
import seaborn as snssklearn
机器学习库,支持分类、回归、聚类、降维四种机器学习算法,包括特征提取、数据处理和模型评估三大模块。
数据导入
from sklearn import dataset数据预处理
# 标准化数据
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 特征选择
from sklearn.feature_selection import VarianceThreshold
data = np.array([[1, 2, 0], [0, 0, 0], [1, 3, 0]])
selector = VarianceThreshold(threshold=0.1)
selected_data = selector.fit_transform(data)
from sklearn.feature_selection import SelectKBest, chi2
X, y = [[1, 2], [3, 4], [5, 6], [7, 8]], [0, 0, 1, 1]
X_new = SelectKBest(chi2, k=1).fit_transform(X, y)
print(X_new)
模型训练
# 模型选择
from sklearn.linear_model import LinearRegression
model = LinearRegression()
# 数据分割
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=42)
# 模型训练
model.fit(X_train_scaled, y_train)
# 超参数调优
from sklearn.model_selection import GridSearchCV
param_grid = {
'max_depth': [2, 3, 5, 10],
'min_samples_split': [2, 5, 10]
}
grid_search = GridSearchCV(DecisionTreeClassifier(), param_grid, cv=5)
grid_search.fit(X_train, y_train)
print("最佳参数:", grid_search.best_params_)
# 模型预测
y_pred = model.predict(X_test_scaled)模型评估
from sklearn.metrics import mean_squared_error,accuracy_score,confusion_matrix
from sklearn.model_selection import cross_val_score
# 计算准确率
accuracy = accuracy_score(y_test, predictions)
# 计算mse
mse = mean_squared_error(y_test, y_pred)
# 生成混淆矩阵
cm = confusion_matrix(y_test, predictions)
# 交叉验证
knn=KNeighborsClassifier(n_neighbors=5)#选择邻近的5个点
scores=cross_val_score(knn,X,y,cv=5,scoring='accuracy')#评分方式为accuracy
print(scores)#每组的评分结果
#[ 0.96666667 1. 0.93333333 0.96666667 1. ]5组数据
print(scores.mean())#平均评分结果
#0.973333333333
模型保存和读取
# 模型持久化
import pickle
with open("model.pkl", "wb") as f:
pickle.dump(model, f)
with open("model.pkl", "rb") as f:
loaded_model = pickle.load(f)
图2 sikit-learn库
参考:深入Scikit-learn:掌握Python最强大的机器学习库-云社区-华为云
pandas
数据处理库,支持文件的导入、数据处理(数据清洗、数据变换、数据分析)等。
库导入
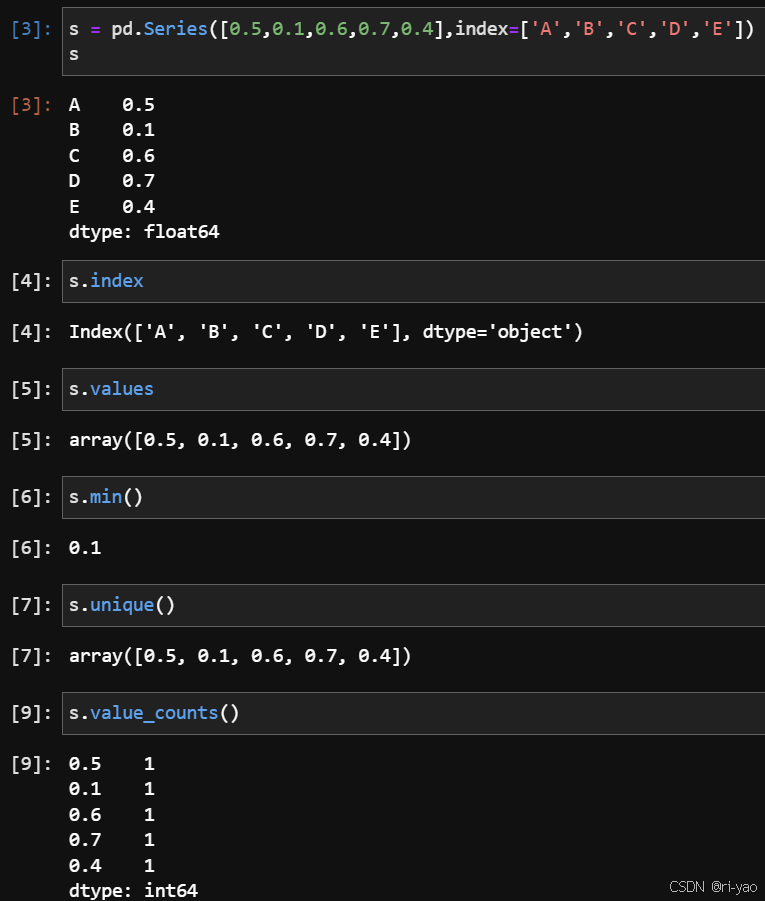
import pandas as pd数据结构-Series
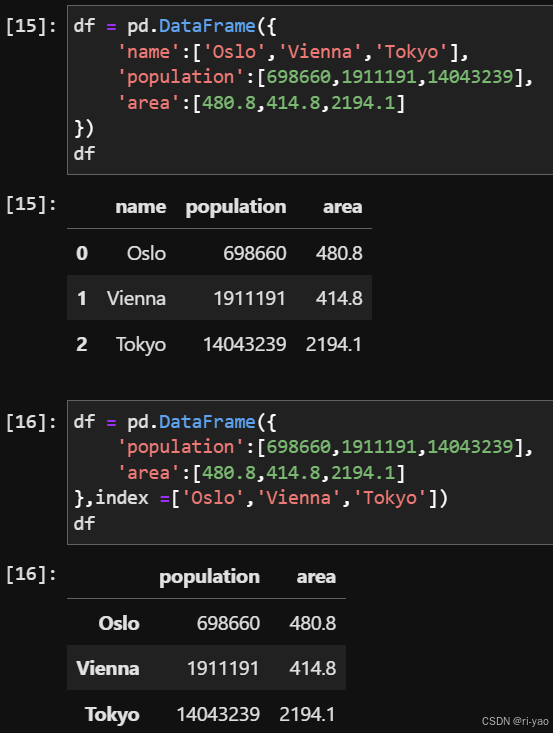
数据结构-DataFrame
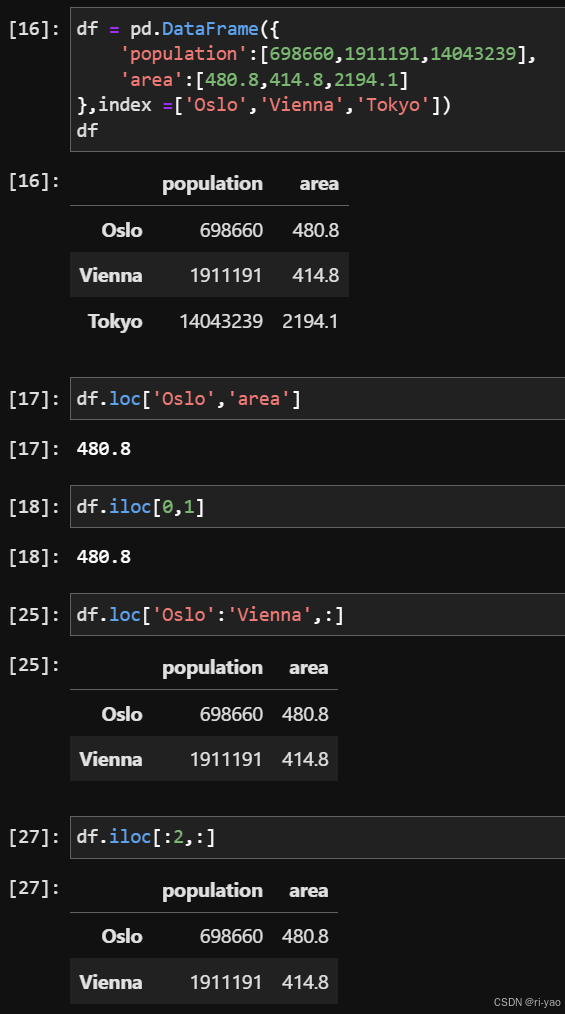
创建
切片
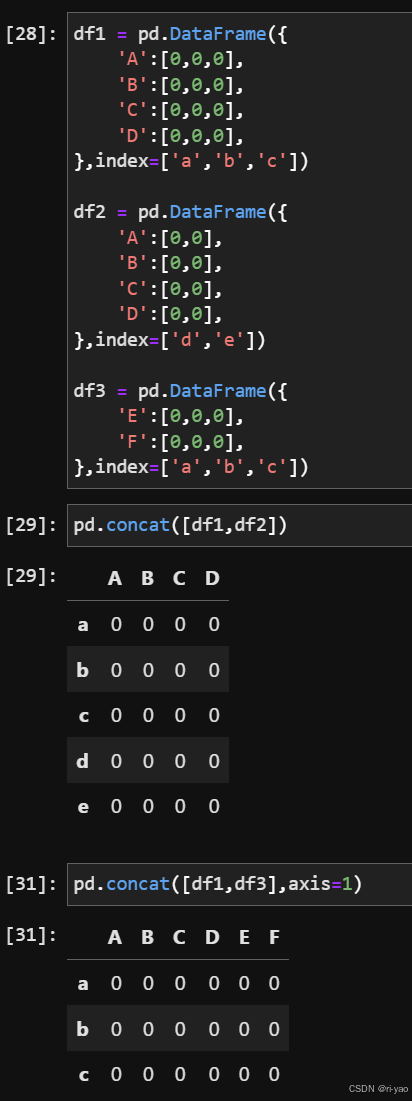
拼接
连接
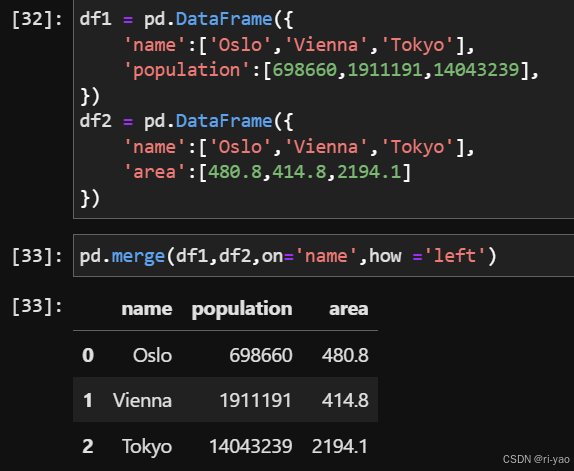
分组与聚合
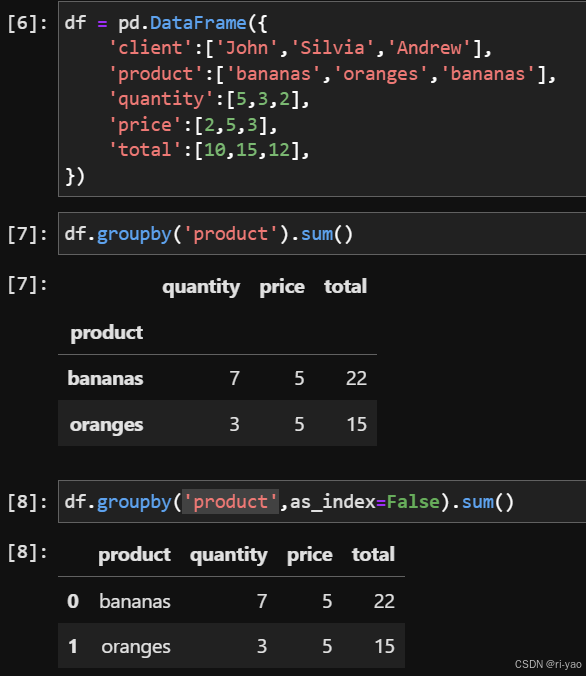
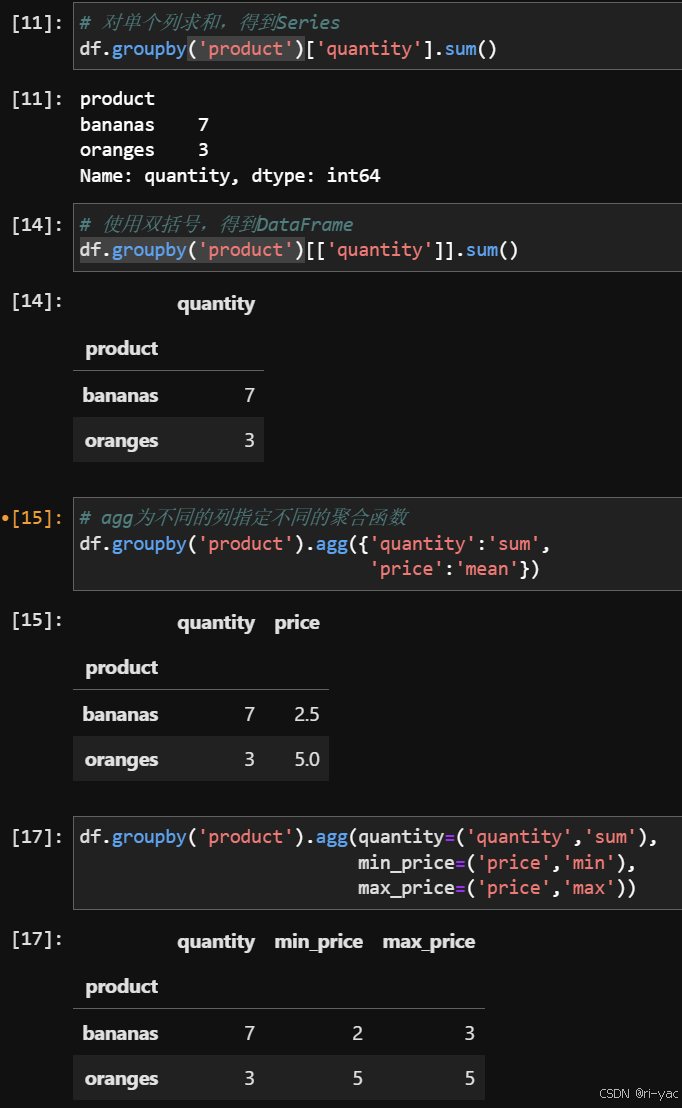
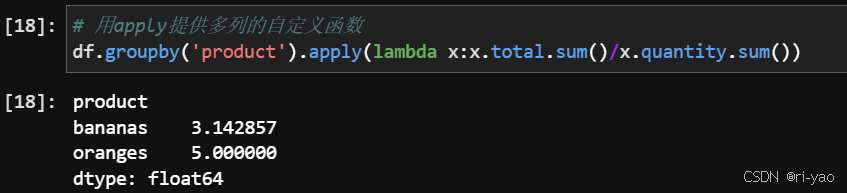
数据读取与存储
pd.read_csv(filepath_or_buffer="filename.csv", # 文件读取路径
header="infer", # 默认第1列是列索引
names=None, # 用于自定义列索引,不自定义列名
nrows=None, # 用于选择读取前X行,默认读取所有行
usecols=None, # 可以用于选择读取特定的列,默认读取所有列
index_col=None, # 用于指定某列的元素作为行索引,默认自动生成行索引
skiprows=None )# 用于选择跳过开头的X行,默认不跳过
df.to_csv(path_or_buf="filename.csv" , # 保存文件的路径
columns=None, # 默认保存所有列
header=True, # 默认保存列索引
index=True) # 默认保存行索引
参考:3.5万字,图解Python数据分析最强库Pandas(全是干货,建议收藏)_pandas库-CSDN博客
torch
Pytorch是torch的python版本,是由Facebook开源的神经网络框架,专门针对 GPU 加速的深度神经网络(DNN)编程。Torch 是一个经典的对多维矩阵数据进行操作的张量(tensor )库,在机器学习和其他数学密集型应用有广泛应用。与Tensorflow的静态计算图不同,pytorch的计算图是动态的,可以根据计算需要实时改变计算图。
库导入
import torchTensor
tensor张量是pytorch中基本的数据结构。
创建
# 全0/1/单位矩阵
torch.zeros(3,5)
torch.ones(3,5)
torch.eyes(3,5)
# 随机数
torch.randn(3,5)
# n数字随机排列
torch.randperm(n)
# 由numpy创建
torch.tensor([1,2,3,4])运算
# 绝对值
torch.abs(A)
# 相加
torch.add(A,B)
# 裁剪,保证范围在min~max之间
torch.clamp(A,min,max)
# 相除
torch.div(A,B)
# 点乘
torch.mul(A,B)
# 叉乘
torch.mm(A,B.T)
# 取元素
A.item()
# 转换为numpy
A.numpy()
# 查看尺寸
A.size()
A.shape
# 对角
torch.diag(A)梯度下降及参数更新
# f(x) = a*x**2 + b*x + c的最小值
x = torch.tensor(0.0, requires_grad=True) # x需要被求导
a = torch.tensor(1.0)
b = torch.tensor(-2.0)
c = torch.tensor(1.0)
optimizer = torch.optim.SGD(params=[x], lr=0.01) #SGD为随机梯度下降
def f(x):
result = a * torch.pow(x, 2) + b * x + c
return (result)
for i in range(500):
optimizer.zero_grad() #将模型的参数初始化为0
y = f(x)
y.backward() #反向传播计算梯度
optimizer.step() #更新所有的参数
print("y=", y.data, ";", "x=", x.data)数据管道
Dataset:一个数据集抽象类,所有自定义的Dataset都需要继承它,并且重写__getitem__()或__get_sample__()这个类方法
DataLoader :一个可迭代的数据装载器。在训练的时候,每一个for循环迭代,就从DataLoader中获取一个batch_sieze大小的数据。
常用流程
import numpy as np
import torch
import matplotlib.pyplot as plt
from torch.utils.data import Dataset, DataLoader
# Prepare the dataset
class DiabetesDateset(Dataset):
# 加载数据集
def __init__(self, filepath):
xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32, encoding='utf-8')
self.len = xy.shape[0] # shape[0]是矩阵的行数,shape[1]是矩阵的列数
self.x_data = torch.from_numpy(xy[:, :-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
# 获取数据索引
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
# 获得数据总量
def __len__(self):
return self.len
dataset = DiabetesDateset('diabetes.csv')
train_loader = DataLoader(dataset=dataset, batch_size=32, shuffle=True, num_workers=2, drop_last=True) # num_workers为多线程
# Define the model
class FNNModel(torch.nn.Module):
def __init__(self):
super(FNNModel, self).__init__()
self.linear1 = torch.nn.Linear(8, 6) # 输入数据的特征有8个,也就是有8个维度,随后将其降维到6维
self.linear2 = torch.nn.Linear(6, 4) # 6维降到4维
self.linear3 = torch.nn.Linear(4, 2) # 4维降到2维
self.linear4 = torch.nn.Linear(2, 1) # 2w维降到1维
self.sigmoid = torch.nn.Sigmoid() # 可以视其为网络的一层,而不是简单的函数使用
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
x = self.sigmoid(self.linear4(x))
return x
model = FNNModel()
# Define the criterion and optimizer
criterion = torch.nn.BCELoss(reduction='mean') # 返回损失的平均值
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
epoch_list = []
loss_list = []
# Training
if __name__ == '__main__':
for epoch in range(100):
# i是一个epoch中第几次迭代,一共756条数据,每个mini_batch为32,所以一个epoch需要迭代23次
# data获取的数据为(x,y)
loss_one_epoch = 0
for i, data in enumerate(train_loader, 0):
inputs, labels = data
y_pred = model(inputs)
loss = criterion(y_pred, labels)
loss_one_epoch += loss.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_list.append(loss_one_epoch / 23)
epoch_list.append(epoch)
print('Epoch[{}/{}],loss:{:.6f}'.format(epoch + 1, 100, loss_one_epoch / 23))
# Drawing
plt.plot(epoch_list, loss_list)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()

















 2229
2229

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









