







目录
一、线性表(Linear List)
线性表(linear list)是数据结构的一种,一个线性表是n个具有相同特性的数据元素的有限序列。
有两种表示方法:数组和链表。
1,数组(Array):
存储单元连续。
eg. int array[10]
vector<int> vMyVector = {1,2,3.0,4,5,6,7}
遍历:
for(int i=0; i<10; i++)
for(auto it=vMyVector .begin(); it!=vMyVector .end(); it++)
std::for_each(vMyVector .begin(), vMyVector .end(), func);
2,链表(List):
存储单元不连续。
3,栈(Stack)
先进后出的数据结构。
4,队列(Queue)
先进先出的数据结构。
二、树(Tree)
三、图(Graph)
邻接列表和邻接矩阵——参考唐先僧的文章:https://www.jianshu.com/p/bce71b2bdbc8
图由定点的集合和边的集合组成。
常用表示方法:邻接列表和邻接矩阵;有向图和无向图。
1,邻接列表
在邻接列表实现中,每一个顶点会存储一个从它这里开始的边的列表。比如,如果顶点A 有一条边到B、C和D,那么A的列表中会有3条边
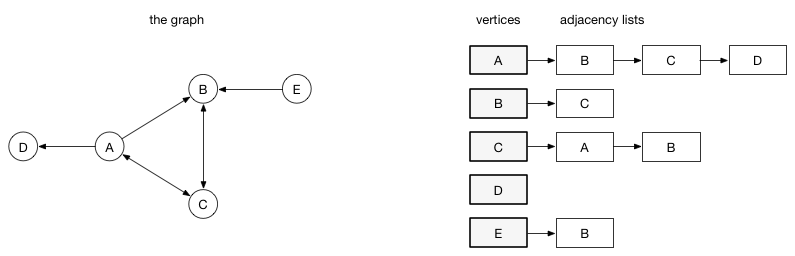
邻接列表只描述了指向外部的边。A 有一条边到B,但是B没有边到A,所以 A没有出现在B的邻接列表中。查找两个顶点之间的边或者权重会比较费时,因为遍历邻接列表直到找到为止。
2,邻接矩阵
在邻接矩阵实现中,由行和列都表示顶点,由两个顶点所决定的矩阵对应元素表示这里两个顶点是否相连、如果相连这个值表示的是相连边的权重。例如,如果从顶点A到顶点B有一条权重为 5.6 的边,那么矩阵中第A行第B列的位置的元素值应该是5.6:
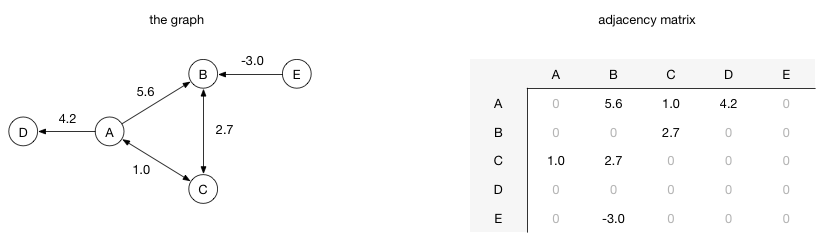
缺点:往这个图中添加顶点的成本非常昂贵,因为新的矩阵结果必须重新按照新的行/列创建,然后将已有的数据复制到新的矩阵中。
选择:稀疏图选择邻接列表,密集图选择邻接矩阵。
常用图相关算法
广度优先搜索和深度优先搜索
常用的图结构
状态机















 2172
2172











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









