







 本文介绍了决策树的基本原理、优缺点及适用数据类型。通过信息增益选择最佳划分特征,递归构建决策树。文中提供了Python代码示例,展示了如何划分数据集和构造决策树。
本文介绍了决策树的基本原理、优缺点及适用数据类型。通过信息增益选择最佳划分特征,递归构建决策树。文中提供了Python代码示例,展示了如何划分数据集和构造决策树。
http://cn.akinator.com/ “神灯猜名人”这个游戏很多人都玩过吧,问很多问题,然后逐步猜测你想的名人是谁。决策树的工作原理与这个类似,输入一系列数据,然后给出游戏答案。决策树也是最经常使用的数据挖掘算法。书上给了一个流程图决策树,很简单易懂。
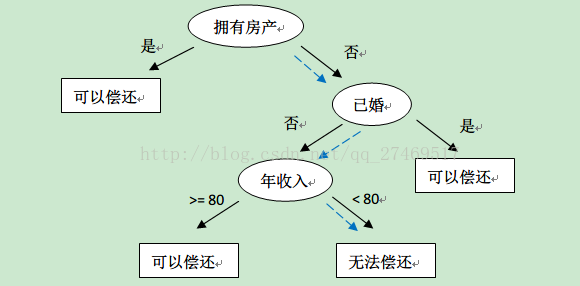
这里,椭圆形就是判断模块,方块就是终止模块。kNN 方法也可以完成分类任务,但是缺点是无法给出数据的内在含义。决策树的主要优势就在于数据形式容易理解。
==============================================================================
决策树
优点:计算复杂度不高,输出结果容易理解,对中间值缺失不敏感,可以处理不相关特征数据。
缺点:可能会产生过度匹配问题。
适用数据类型:数值型和标称型。
伪代码:
creatBranch():
if so return 类标签:
else:
寻找划分数据集的最好特征
划分数据集
创建分支节点
for 每个划分的子集
调用函数 creatBranch() 并增加返回结果到分支节点中
return 分支节点可以看出这是一个递归函数,在里面直接调用了自己。
==============================================================================
决策树的一般流程:
- 收集数据:可以使用任何方法
- 准备数据:树构造算法只适用于标称型数据,因此数值型数据必须离散化。
- 分析数据:可以使用任何方法,构造树完成以后,我们应该检查图形是否符合预期。
- 训练算法:构造树的数据结构。
- 测试算法:使用经验树计算错误率。
- 使用算法:此步骤可以适用于任何监督学习算法,而使用决策树可以更好地理解数据的内在含义。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1045
1045

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









