







本文只是对机器学习的流程做一个简单的描述,每个环节涉及的东西很多,不是本文介绍的范围,对其中比较重要的知识点稍微提及一下,具体的可以参考其他文章学习。先上一张流程图。
机器学习从数据准备到上线流程:
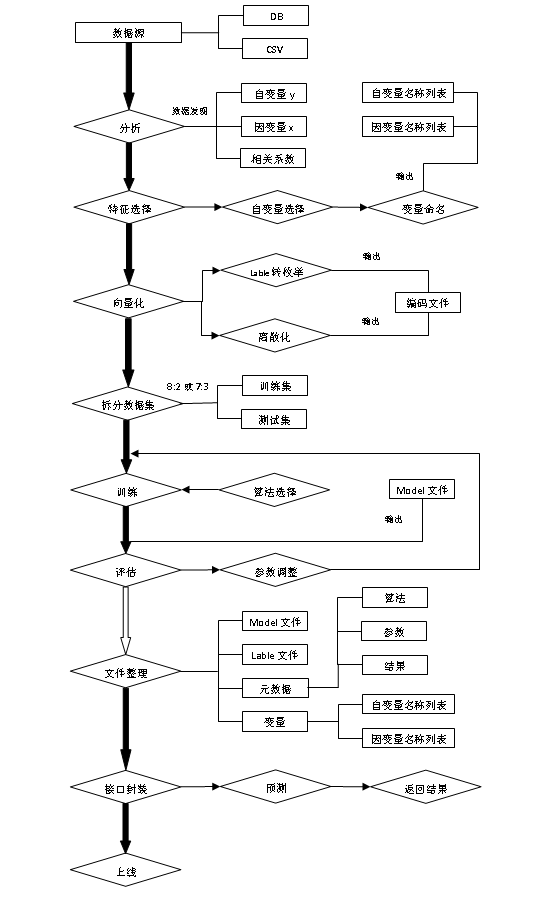
接下来根据流程图,逐步分析机器学习的流程。
1. 数据源:
机器学习的第一个步骤就是收集数据,这一步非常重要,因为收集到的数据的质量和数量将直接决定预测模型是否能够建好。我们可以将收集的数据去重复、标准化、错误修正等等,保存成数据库文件或者csv格式文件,为下一步数据的加载做准备。
2. 分析:
这一步骤主要是数据发现,比如找出每列的最大、最小值、平均值、方差、中位数、三分位数、四分位数、某些特定值(比如零值)所占比例或者分布规律等等都要有一个大致的了解。了解这些最好的办法就是可视化,谷歌的开源项目facets可以很方便的实现。另一方面要确定自变量(x1...xn)和因变量y,找出因变量和自变量的相关性,确定相关系数。
3. 特征选择:
特征的好坏很大程度上决定了分类器的效果。将上一步骤确定的自变量进行筛选,筛选可以手工选择或者模型选择,选择合适的特征,然后对变量进行命名以便更好的标记。命名文件要存下来,在预测阶段的时候会用到。
4. 向量化:
向量化是对特征提取结果的再加工,目的是增强特征的表示能力,防止模型过于复杂和学习困难,比如对连续的特征值进行离散化,label值映射成枚举值,用数字进行标识。这一阶段将产生一个很重要的文件:label和枚举值对应关系,在预测阶段的同样会用到。
5. 拆分数据集:
需要将数据分为两部分。用于训练模型的第一部分将是数据集的大部分。第二部分将用于评估我们训练有素的模型的表现。通常以8:2或者7:3进行数据划分。不能直接使用训练数据来进行评估,因为模型只能记住“问题”。
6. 训练:
进行模型训练之前,要确定合适的算法,比如线性回归、决策树、随机森林、逻辑回归、梯度提升、SVM等等。选择算法的时候最佳方法是测试各种不同的算法,然后通过交叉验证选择最好的一个。但是,如果只是为问题寻找一个“足够好”的算法,或者一个起点,也是有一些还不错的一般准则的,比如如果训练集很小,那么高偏差/低方差分类器(如朴素贝叶斯分类器)要优于低偏差/高方差分类器(如k近邻分类器),因为后者容易过拟合。然而,随着训练集的增大,低偏差/高方差分类器将开始胜出(它们具有较低的渐近误差),因为高偏差分类器不足以提供准确的模型。
7. 评估:
训练完成之后,通过拆分出来的训练的数据来对模型进行评估,通过真实数据和预测数据进行对比,来判定模型的好坏。模型评估的常见的五个方法:混淆矩阵、提升图&洛伦兹图、基尼系数、ks曲线、roc曲线。混淆矩阵不能作为评估模型的唯一标准,混淆矩阵是算模型其他指标的基础。
混淆矩阵
| 预测数据 | ||
J | G | ||
真实数据 | J | X1 | X2 |
G | X3 | X4 | |
备注:X1为作出正确判断的否定记录
X2为作出错误判断的肯定记录
X3为作出错误判断的否定记录
X4为作出正确判断的肯定记录
可以通过以下三个指标来评估模型的好坏:
准确率:P = X4/ ( X2 + X4)
召回率:R = X4/ ( X3 + X4)
调和平均数:F = 2PR/ ( R + P )
完成评估后,如果想进一步改善训练,我们可以通过调整模型的参数来实现,然后重复训练和评估的过程。
8. 文件整理:
模型训练完之后,要整理出四类文件,确保模型能够正确运行,四类文件分别为:Model文件、Lable编码文件、元数据文件(算法,参数和结果)、变量文件(自变量名称列表、因变量名称列表)。
9. 接口封装:
通过封装封装服务接口,实现对模型的调用,以便返回预测结果。
10. 上线:















 13万+
13万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









