









 本文详细介绍了基于RT-Thread实时操作系统上的lwip网络栈如何进行网卡驱动的移植与优化,包括网卡框架、驱动配置、吞吐速率测试及优化方法,如TCP参数调整、lwip内核参数优化、内存拷贝效率提升和网卡发送接收逻辑的改进。此外,还讨论了网卡MAC地址的管理策略,确保网络设备的稳定运行。
本文详细介绍了基于RT-Thread实时操作系统上的lwip网络栈如何进行网卡驱动的移植与优化,包括网卡框架、驱动配置、吞吐速率测试及优化方法,如TCP参数调整、lwip内核参数优化、内存拷贝效率提升和网卡发送接收逻辑的改进。此外,还讨论了网卡MAC地址的管理策略,确保网络设备的稳定运行。
基于RT-Thread的lwip网卡优化笔记
一、RT-Thread的lwip框架
RT-Thread的网络框架主要是实现eth_device,并通过eth_device_init注册,下面是eth_device的定义。
struct eth_device
{
/* inherit from rt_device */
struct rt_device parent;
/* network interface for lwip */
struct netif *netif;
struct rt_semaphore tx_ack;
rt_uint16_t flags;
rt_uint8_t link_changed;
rt_uint8_t link_status;
/* eth device interface */
struct pbuf* (*eth_rx)(rt_device_t dev);
rt_err_t (*eth_tx)(rt_device_t dev, struct pbuf* p);
};
网卡移植主要是要在驱动层实现eth_rx和eth_tx。eth_rx即网卡接收,eth_tx即网卡发送。一般来说,网卡驱动需要结合dma来使用,例如当需要发送数据时,lwip最终会调用到eth_tx函数指针进行发送,lwip将要发送的数据放到了pbuf中,我们需要从pbuf从读取数据放入网卡发送DMA中,启动发送;当网卡收到数据时,emac将产生中断,在中断里会唤醒接收线程,这个接收线程会调用eth_rx函数指针接收数据,我们需要申请pbuf,并将网卡DMA中的数据拷贝到pbuf中,最后给lwip返回这个pbuf。
lwip的ethernetif.c是一个供移植的文件,在RT-Thread上,RT-Thread已经全都定义好了,从下面的代码可以看出,eth_system_device_init_private函数创建了两个线程:erx和etx。一般来说,LWIP_NO_RX_THREAD宏都是没定义的,也就是erxmb信号量和erx线程会被创建,当emac接收数据并产生中断时,会调用eth_device_ready函数发送erxmb信号量唤醒erx接收线程,这个线程再去调用eth_rx接收函数。LWIP_NO_TX_THREAD宏可以定义也可以不定义,当定义这个宏时,发送数据时将会直接在lwip的tcpip线程调用eth_tx发送函数,当未定义这个宏时,发送的数据将会由tcpip线程通过邮箱的形式传给etx线程,由etx线程发出。
int eth_system_device_init_private(void)
{
rt_err_t result = RT_EOK;
/* initialize Rx thread. */
#ifndef LWIP_NO_RX_THREAD
/* initialize mailbox and create Ethernet Rx thread */
result = rt_mb_init(ð_rx_thread_mb, "erxmb",
ð_rx_thread_mb_pool[0], sizeof(eth_rx_thread_mb_pool)/4,
RT_IPC_FLAG_FIFO);
RT_ASSERT(result == RT_EOK);
result = rt_thread_init(ð_rx_thread, "erx", eth_rx_thread_entry, RT_NULL,
ð_rx_thread_stack[0], sizeof(eth_rx_thread_stack),
RT_ETHERNETIF_THREAD_PREORITY, 16);
RT_ASSERT(result == RT_EOK);
result = rt_thread_startup(ð_rx_thread);
RT_ASSERT(result == RT_EOK);
#endif
/* initialize Tx thread */
#ifndef LWIP_NO_TX_THREAD
/* initialize mailbox and create Ethernet Tx thread */
result = rt_mb_init(ð_tx_thread_mb, "etxmb",
ð_tx_thread_mb_pool[0], sizeof(eth_tx_thread_mb_pool)/4,
RT_IPC_FLAG_FIFO);
RT_ASSERT(result == RT_EOK);
result = rt_thread_init(ð_tx_thread, "etx", eth_tx_thread_entry, RT_NULL,
ð_tx_thread_stack[0], sizeof(eth_tx_thread_stack),
RT_ETHERNETIF_THREAD_PREORITY, 16);
RT_ASSERT(result == RT_EOK);
result = rt_thread_startup(ð_tx_thread);
RT_ASSERT(result == RT_EOK);
#endif
return (int)result;
}
下面的代码是注册lwip网卡驱动的过程。
struct emac_device *edev = &g_emac_device[EMAC0_100M];
lwip_sys_init();
edev->module = EMAC0_100M;
edev->irq = VC0768_IRQ_EMAC0_DMA;
edev->mac_base = VC0768_EMAC0_BASE;
edev->dma_base = VC0768_EMAC0_BASE + REG_EMAC_DMA_OFFSET;
edev->phy_type = PHY_TYPE_INT;
edev->phy_addr = DEFAULT_INT_PHY_ADDR;
edev->speed = SPEED100M;
edev->duplex = FULLDUPLEX;
edev->auto_nego = true;
sprintf(edev->name, "%s", EMAC0_NAME);
rt_memcpy(edev->dev_addr, mac_addr, sizeof(mac_addr));
edev->tx_buf = (u32 *)rt_malloc_align(EMAC_TX_BUF_SIZE * TRANSMIT_DESC_SIZE, RT_CPU_CACHE_LINE_SZ);
edev->rx_buf = (u32 *)rt_malloc_align(EMAC_RX_BUF_SIZE * RECEIVE_DESC_SIZE, RT_CPU_CACHE_LINE_SZ);
memset(edev->tx_buf, 0, EMAC_TX_BUF_SIZE);
memset(edev->rx_buf, 0, EMAC_RX_BUF_SIZE);
emac_clk_init(edev);
emac_phy_init(edev);
emac_dma_init(edev);
emac_mac_init(edev);
emac_tx_sem = rt_sem_create("emac rx on sem", 0, RT_IPC_FLAG_FIFO);
edev->parent.eth_rx = emac_rx;
edev->parent.eth_tx = emac_tx;
edev->parent.parent.init = emac_ops.init;
edev->parent.parent.control = emac_ops.control;
rt_kprintf("%s %d\n", __func__, __LINE__);
eth_device_init(&(edev->parent), edev->name);
request_irq(edev->irq, vmc_interrupt, 0, edev->name, edev);
enable_irq(edev->irq);
netif_set_link_up(edev->parent.netif);
二、网卡驱动
VC0768有两个EMAC,分别是EMAC0和EMAC1,其中EMAC0最高支持到100Mbps,EMAC1最高支持到1000Mbps,EMAC0内部自带PHY,外部只需加上网络变压器即可通信,EMAC1则需要外接千兆PHY,例如开发板上接的就是Realtek的RTL8211F。在软件配置上,EMAC0和EMAC1的配置是差不多的,但EMAC1需要额外配置相应的引脚。
网卡驱动移植最重要的就是配置网卡DMA,VC0768的网卡DMA分为发送DMA和接收DMA,以接收DMA举例。DMA的缓存的个数以及每个块的大小都是可以配置的,例如uboot中配置的DMA单个接收块有256个,每个块大小为2048字节(实际大于1518字节即可),DMA有链式(chain)模式和环形(ring)模式,以环形模式来说,在逻辑上,这就像是个环形的队列,队列的每个块大小是固定的。当EMAC接收到数据时,会自动放入到DMA的某块缓存中,下一次接收时,将自动放入下一块缓存中,即其本身具备地址自增功能。这就是一个最经典的生产者和消费者模型,需要确保DMA的数据及时读取,否则所有的DMA数据块被写满后,将会丢包。代码中可以判断对应块的status来判断这个块当前时属于CPU还是属于DMA,属于CPU即代码可以访问,属于DMA即这个块DMA正在使用。
三、网卡吞吐速率测试
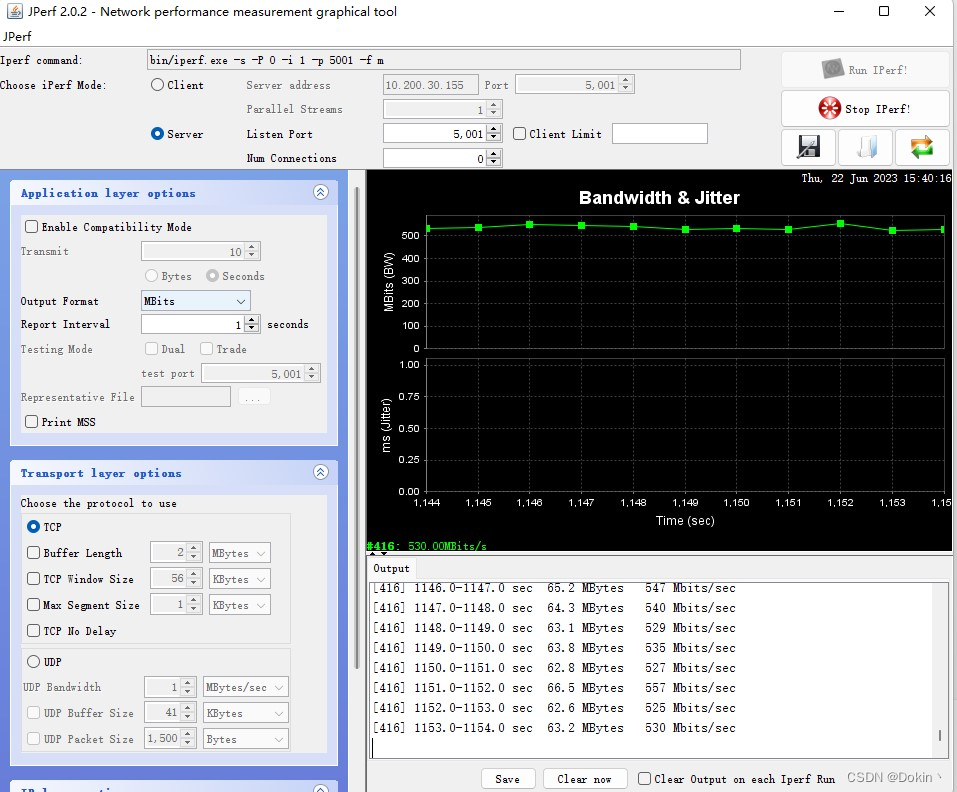
网卡吞吐速率测试一般使用iperf工具,iperf有很多版本,最新的是iperf3,iperf3的功能比较齐全。但iperf和iperf3并不通用,有些设备只支持iperf,那么对端也只能使用iperf。最简单的就是服务器端执行iperf -s,客户端执行iperf -c xx:xx:xx:xx,xx为服务端的ip地址。iperf还可以设置发包数量、tcp窗口大小等参数。iperf是个命令行工具,Jperf则是基于iperf的图形化工具,可以简单轻松的对iperf进行配置,如下所示。
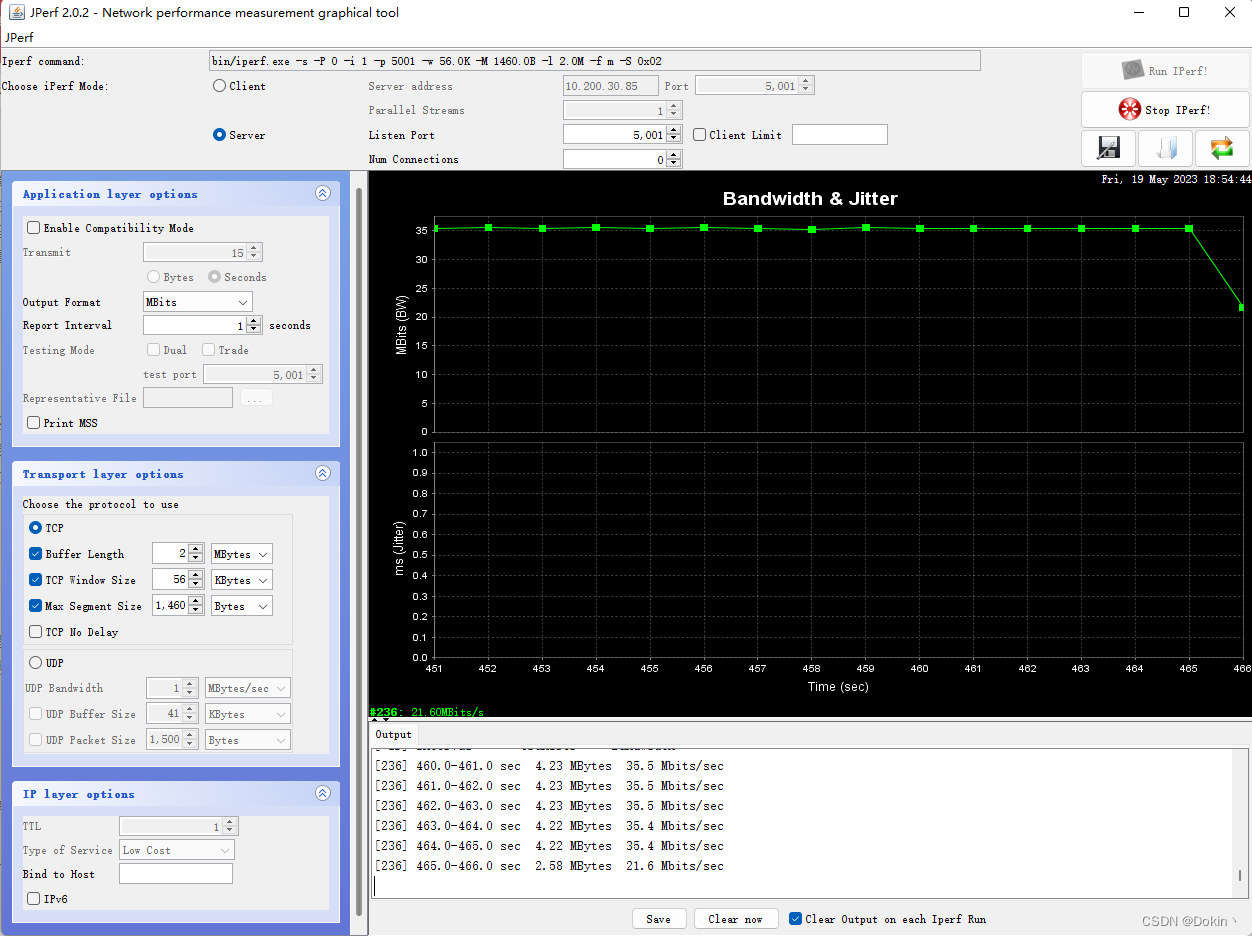
四、网卡吞吐速率优化
网卡吞吐速率优化是一个比较繁琐的性能优化过程,里面涉及到很多,包括TCP参数、lwip参数、内存拷贝效率、网卡收发逻辑等,下面是几个比较重要的优化点。
4.1 TCP参数优化
- TCP_MSS:即Maxitum Segment Size,TCP单次传输最大的有效字节数,这个值最大可以为1460字节,因此需要改成1460字节。
- TCP_WND:即TCP的滑动窗口大小,不过实测这个值对吞吐速率影响不大,窗口大小是会双方自动调节的。
4.2 lwip参数优化
lwip的opt.h文件有很多lwip的默认配置,如果想修改配置,修改lwipopt.h文件即可。lwip的参数优化主要就是修改lwipopt.h这个文件。
-
内存申请方式优化:lwip共有三种内存分配方式,第一种是使用C库的malloc,第二种是lwip自己实现的动态内存堆分配,第三种是使用lwip自己实现的动态内存池分配。C库的malloc是最不推荐使用的,内存大的情况下,推荐使用内存池分配。内存池相比于内存堆,优点是分配和释放速度快且不会产生内存碎片,缺点是容易浪费空间,因为内存池里的块大小是不变的。具体的改动如下。各种类型的pbuf的个数、大小也需要合理设置,不至于在吞吐速率高时,pbuf不够用。
#define MEM_LIBC_MALLOC 0 #define MEM_USE_POOLS 1 #define MEMP_USE_CUSTOM_POOLS 1 -
LWIP_NETIF_TX_SINGLE_PBUF宏需要改为0,虽然官方说这个宏是为了让多个pbuf尽可能合成一个,有利于DMA发送,但实际上这个宏定义了之后会有拷贝的操作,影响效率,需要斟酌是否需要改为0。
-
LWIP_STATS宏设置为0,这个是lwip内部统计功能,关闭可以提高代码执行效率。
4.3 内存拷贝优化
4.3.1 rt_memcpy优化
系统主频为1.2GHz,但实测拷贝12.5MB(100Mbit)数据,使用原生的rt_memcpy需要600ms,这会验证影响网卡的收发效率,因为lwip里面有不少pbuf拷贝的操作,例如网卡发送时,需要将pbuf中的payload拷贝到网卡DMA中发送。看rt_memcpy的源码可以发现,4字节对齐时,以long为字长进行拷贝,当内存非4字节对齐时,直接使用单字节方式进行拷贝,没有考虑2字节对齐的情况。且4字节拷贝时,可以使用neon指令进行拷贝,速度会更快。因此可以对rt_memcpy做如下优化:
void *rt_memcpy(void *dst, const void *src, rt_ubase_t count)
{
#define UNALIGNED(X, Y) \
(((long)X & (sizeof (long) - 1)) | ((long)Y & (sizeof (long) - 1)))
#define BIGBLOCKSIZE (sizeof (long) << 2)
#define LITTLEBLOCKSIZE (sizeof (long))
#define TOO_SMALL(LEN) ((LEN) < BIGBLOCKSIZE)
char *dst_ptr = (char *)dst;
char *src_ptr = (char *)src;
long *aligned_dst;
long *aligned_src;
int len = count;
unsigned short *test_dst;
unsigned short *test_src;
/* 增加neon拷贝 */
if((len > 63) && (!((long)dst_ptr & 3)) && !((long)src_ptr & 3))
{
/* 此处只做演示,可能会溢出 */
if (len & 63)
len = (len & -64) + 64;
asm volatile (
"NEONCopyPLD: \n"
" VLDM %[src]!,{d0-d7} \n"
" VSTM %[dst]!,{d0-d7} \n"
" SUBS %[len],%[len],#0x40 \n"
" BGT NEONCopyPLD \n"
: [dst]"+r"(dst), [src]"+r"(src), [len]"+r"(len) : : "d0", "d1", "d2", "d3", "d4", "d5", "d6", "d7", "cc", "memory");
return dst_ptr+len;
}
/* 原生的4字节拷贝 */
if (!TOO_SMALL(len) && !UNALIGNED(src_ptr, dst_ptr))
{
aligned_dst = (long *)dst_ptr;
aligned_src = (long *)src_ptr;
while (len >= BIGBLOCKSIZE)
{
*aligned_dst++ = *aligned_src++;
*aligned_dst++ = *aligned_src++;
*aligned_dst++ = *aligned_src++;
*aligned_dst++ = *aligned_src++;
len -= BIGBLOCKSIZE;
}
while (len >= LITTLEBLOCKSIZE)
{
*aligned_dst++ = *aligned_src++;
len -= LITTLEBLOCKSIZE;
}
dst_ptr = (char *)aligned_dst;
src_ptr = (char *)aligned_src;
}
/* 增加2字节对齐时的拷贝 */
if( !((long)src_ptr & 0x01) && !((long)dst_ptr & 0x01))
{
test_dst = (unsigned short*)dst_ptr;
test_src = (unsigned short*)src_ptr;
while (len > 1)
{
*test_dst++ = *test_src++;
len -= 2;
}
dst_ptr = (char *)test_dst;
src_ptr = (char *)test_src;
}
/* 原生的单字节拷贝 */
while (len--)
{
*dst_ptr++ = *src_ptr++;
}
return dst;
#undef UNALIGNED
#undef BIGBLOCKSIZE
#undef LITTLEBLOCKSIZE
#undef TOO_SMALL
#endif
}
优化的效果如下:
- rt_memcpy优化2字节拷贝后udp发送速率从30Mbps提升到48Mbps,TCP发送速率从22Mbps提升到30Mbps,tcp接收仍然是6Mbps。
- rt_memcpy4字节对齐时加入neon指令进行拷贝,udp发送仍然是48Mbps,TCP发送速率从30Mbps提升到36Mbps,TCP接收仍然是6Mbps。
优化2字节对齐的拷贝,性能有较明显的提升,原因是Ethernet II头部是6字节目的地址+6字节源地址+2字节长度,共14字节,后面紧跟着payload,如下图所示。当payload是4字节对齐时,目的地址所在的内存是2字节对齐的。lwip发送数据时,传下来的pbuf->payload就是这样的情况,pbuf->payload是一个2字节对齐的地址,而不是4字节对齐的,因此优化2字节对齐时,对lwip整体性能也有提升。

网上有一个开源的rt_memcpy加强版,使用汇编指令,实测效果比neon指令略差一些,但比原生的rt_memcpy要强得多。地址如下:https://github.com/mysterywolf/rt_memcpy_cm
4.3.2 使用uboot下的memcpy.S
实测同一段内存拷贝测试程序,在uboot下执行只需要8ms,而在melis下执行需要102ms,差了整整10倍多。因此将uboot下arch/arm/lib/memcpy.S直接拿来用,实测性能有大幅度的提升,udp发送提高到94Mbps,tcp发送提高到61Mbps。正常来说,百兆网udp打流可以到将近100Mbps,例如99Mbps,tcp可以到90多Mbps,因此还是存在一定的优化空间的。猜测tcp速率上不来和tcp接收有关系,因为tcp接收的速率仍然只到6Mbps,还要再进一步排查。
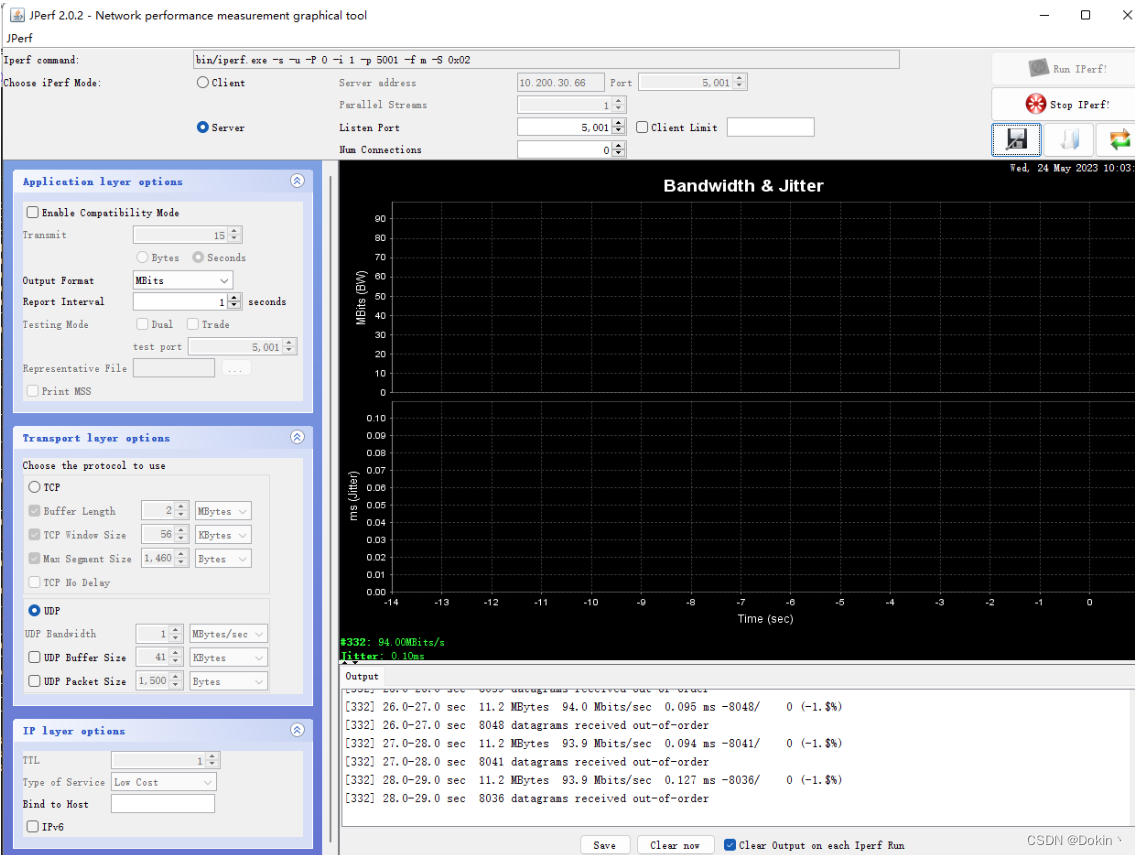
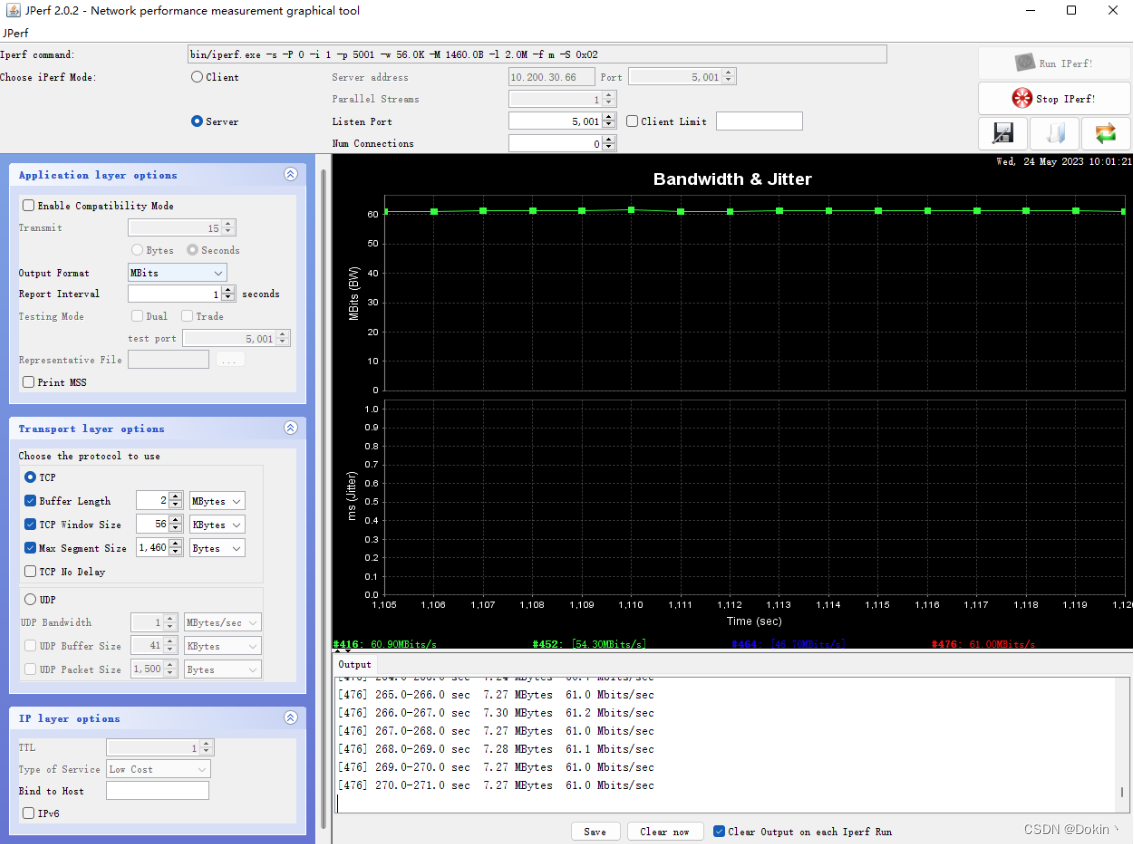
4.4 开启MMU和D-Cache
前面搞了半天,结果发现MMU和D-Cache没有开启,开启MMU和D-Cache之后,系统性能直接原地起飞,前面memcpy拷贝性能问题也不复存在了,即memcpy直接达到了最高速度,因此最后lwip的opt.h中的memcpy等函数直接使用C库的,不再使用rtthread的。
#if !defined MEMCPY || defined __DOXYGEN__
#define MEMCPY(dst,src,len) memcpy(dst,src,len)
#endif
/**
* SMEMCPY: override this with care! Some compilers (e.g. gcc) can inline a
* call to memcpy() if the length is known at compile time and is small.
*/
#if !defined SMEMCPY || defined __DOXYGEN__
#define SMEMCPY(dst,src,len) memcpy(dst,src,len)
#endif
/**
* MEMMOVE: override this if you have a faster implementation at hand than the
* one included in your C library. lwIP currently uses MEMMOVE only when IPv6
* fragmentation support is enabled.
*/
#if !defined MEMMOVE || defined __DOXYGEN__
#define MEMMOVE(dst,src,len) memmove(dst,src,len)
#endif
开启MMU和D-Cache后,在内存使用上有两种选择,一种是cache内存,即write-back类型,另一种是uncache内存。
cache内存这种类型需要做好DMA和D-Cache的数据同步,比较麻烦,简单来说就是:
- 发送数据:数据从pbuf拷贝到tx dma buff后,需要调用rt_hw_cpu_dcache_clean将D-Cache中对应区域数据刷新到tx dma buff中。
- 接收数据:网卡将数据放到rx dma buff后,需要调用rt_hw_cpu_dcache_invalidate使D-Cache中的数据无效,确保CPU直接从rx dma buff读取数据。
uncache内存就是数据不经过D-Cache,非常适合DMA的使用场景。
具体的内存区域和类型划分是在MMU设置页表时指定。
4.5 网卡收发优化
4.5.1 lwip发送优化
前文提到了lwip在发送报文时,如果没有定义LWIP_NO_TX_THREAD宏,那么发送的数据会通过邮箱传递给etx线程,由etx线程代发,缺点是这里引入了一次操作系统的调度,这是需要时间上的开销的,优点是tcpip线程只需要专心处理数据,隔离性比较好。如果追求性能,可以考虑定义LWIP_NO_TX_THREAD这个宏。
4.5.2 网卡发送优化
前文提到,DMA有多个块,在中断里会判断发送是否完成,并释放发送完成的信号量。实际上网卡发送时,不必每次都等待这个信号量,因为当前发送可能正在进行,但是可以把数据装载到下一个DMA块里。所以发送时应直接取下一块DMA块,判断当前是否属于CPU,如果是属于CPU就直接使用,无需等待信号量;如果是属于DMA,说明所有的DMA发送块都写满了,这时候才需要等待发送完成。所以将DMA发送块的个数设置的稍大一些,在一定程度上也是可以提升性能的。
但是这种优化会引入一个小问题,就是RT-Thread的信号量没有二值型的,但在这个场景下二值信号量明显是更合适的,因此使用RT-Thread的事件集来代替信号量,优化后的伪代码如下:
/* DMA中断服务函数,发送完成后发送EMAC_EVENT_TX_COMPLETE事件 */
irqreturn_t vmc_interrupt(int irqno, void *param)
{
……
if (ints & DmaIntTxCompleted)
{
rt_event_send(emac_event, EMAC_EVENT_TX_COMPLETE);
}
……
}
/* 以太网底层发送函数 */
static rt_err_t emac_tx(rt_device_t dev, struct pbuf *p)
{
/* 省略拷贝pbuf到tx dma buff的过程 */
/* 启动发送 */
vmc_emac_resume_dma_tx(edev);
/* 查看下一个tx dma buff的状态*/
DmaDesc *txdesc_next = vmc_emac_is_last_tx_desc(edev, edev->TxNextDesc) ? edev->tx_desc_head : (edev->TxNextDesc + 1);
/* 下一个tx dma buff处于空闲状态,清空EMAC_EVENT_TX_COMPLETE事件,无需等待 */
if (vmc_emac_is_desc_empty(txdesc_next))
{
rt_event_recv(edev->emac_event, EMAC_EVENT_TX_COMPLETE, RT_EVENT_FLAG_OR | RT_EVENT_FLAG_CLEAR,
0, NULL);
}
/* 下一个tx dma buff处于繁忙状态,说明系统中所有的的tx dma buff全部被填满了,此时需要等待 */
else
{
err = rt_event_recv(edev->emac_event, EMAC_EVENT_TX_COMPLETE, RT_EVENT_FLAG_OR | RT_EVENT_FLAG_CLEAR,
rt_tick_from_millisecond(500), NULL);
if (err != RT_EOK)
{
rt_kprintf("wait next tx dma failed\n");
}
}
vmc_txq_reclaim(edev);
}
优化网卡底层发送函数之后,吞吐速率有进一步提升:
- 百兆MAC的TCP发送从83Mbps提升到93Mbps,UDP发送从85Mbps提升到94Mbps。
- 千兆MAC的TCP发送从350Mps提升到530Mbps,UDP发送从400Mbps提升到800Mbps。
下面分别是百兆和千兆的TCP上行吞吐速率。
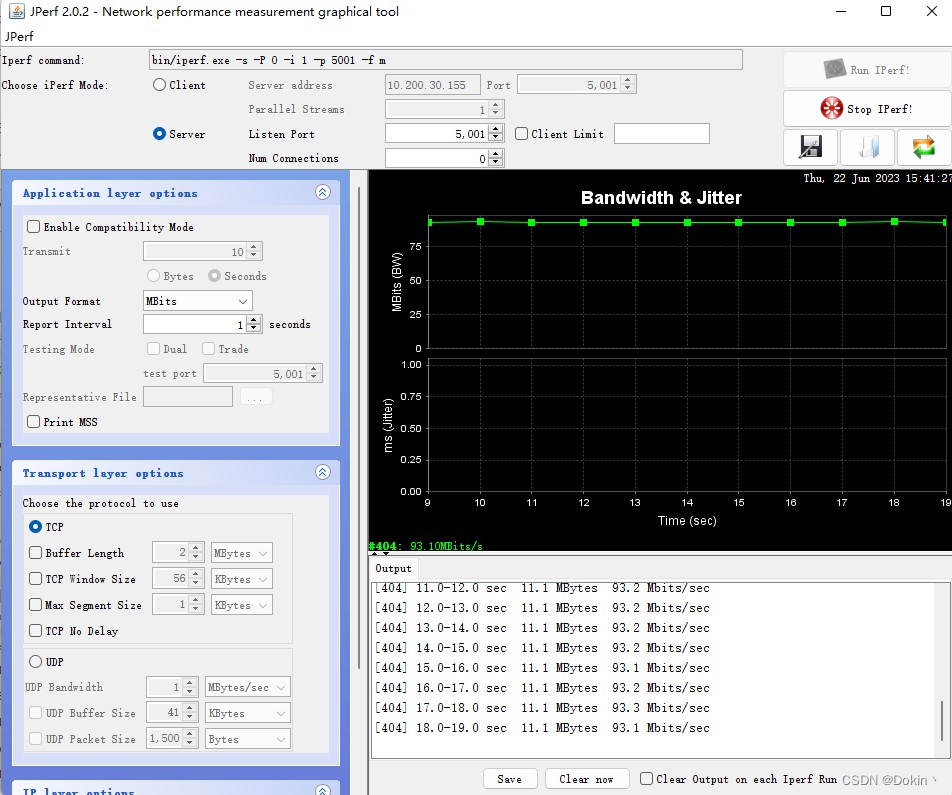
五、网卡MAC地址问题
网卡的MAC地址是通过软件设置的,如果MAC每次开机都随机生成,那么DHCP时,网关就会为其重新分配一个ip,反复重启多次,局域网的ip资源很快就会被沾满,因此MAC地址需要唯一且不变。正常产品开发流程中,设备的MAC地址会和产品的序列号等信息会在工厂生产时一起烧录到设备的信息区。我们调试阶段的话,可以利用设备的唯一信息来确保MAC地址的唯一性和不变性,例如用芯片的chip ID做mac地址,或者将MAC地址信息写入文件里,这样只会文件不存在时首次生成MAC地址,后续直接读取文件里的MAC地址即可。下面提供一种将MAC地址写入文件的做法:
#include <rtthread.h>
#include "lwip/inet.h"
#include "lwip/netif.h"
#include "log.h"
#include "init.h"
#include "stdint.h"
#include <sunxi_hal_gpio.h>
#include "drv_emac.h"
#include "ethernetif.h"
#include "ktimer.h"
#define EMAC0_NETIF_NAME "e0"
#define EMAC1_NETIF_NAME "e1"
#define EMAC_CFG_FILE "/mnt/E/config.txt"
#define NET_IS_IP4_VALID(nif) (netif_is_up(nif) && \
!ip_addr_isany(&((nif)->ip_addr)))
static void netif_status_callback(struct netif *netif)
{
if (NET_IS_IP4_VALID(netif))
{
__log("%s got ip", netif->name);
__log("address: %s", inet_ntoa(netif->ip_addr));
__log("gateway: %s", inet_ntoa(netif->gw));
__log("netmask: %s", inet_ntoa(netif->netmask));
}
else
{
__log("%s is down", netif->name);
}
}
static void test_emac_thread(void *p)
{
struct eth_device *eth_dev = NULL;
FILE *file = NULL;
rt_uint8_t mac_addr[6] = {0};
char buff[64];
struct timespec64 ts;
u32 randnum = 0;
int which = 0,i = 0,ret = 0,len = 0;
/* wait file system ready */
rt_thread_mdelay(3000);
/* get mac address from config.txt file */
file = fopen(EMAC_CFG_FILE, "r");
if(file == NULL)
{
__wrn("emac config file not exist,try to create it");
file = fopen(EMAC_CFG_FILE, "w");
if(file == NULL)
{
__wrn("emac config file create failed,use default configuration");
goto end_config;
}
__log("emac config file create success");
for(which = 0; which < EMAC_NUM_MAX; which++)
{
for(i = 0; i < 2; i++)
{
do_gettimeofday(&ts);
srand(ts.tv_nsec);
randnum = rand();
mac_addr[0 + (3 * i)] = (randnum & 0x00FF0000) >> 16;
mac_addr[1 + (3 * i)] = (randnum & 0x0000FF00) >> 8;
mac_addr[2 + (3 * i)] = (randnum & 0x000000FF);
}
mac_addr[0] &= 0xfe;
mac_addr[0] |= 0x02;
rt_memset(buff, 0, sizeof(buff));
sprintf(buff, "%02X:%02X:%02X:%02X:%02X:%02X\n",
mac_addr[0], mac_addr[1], mac_addr[2],
mac_addr[3], mac_addr[4], mac_addr[5]);
__log("set e%d mac:%02X:%02X:%02X:%02X:%02X:%02X", which,
mac_addr[0], mac_addr[1], mac_addr[2],
mac_addr[3], mac_addr[4], mac_addr[5]);
drv_emac_set_addr(which, mac_addr);
len = rt_strlen(buff);
ret = fwrite(buff, 1, len, file);
if(ret == len)
{
__log("write config file success");
}
else
{
__err("write config file failed");
}
}
}
else
{
__log("open config file ok");
for(which = 0; which < EMAC_NUM_MAX; which++)
{
rt_memset(buff, 0, sizeof(buff));
rt_memset(mac_addr, 0, sizeof(mac_addr));
if(fgets(buff, sizeof(buff), file) == NULL)
{
__wrn("emac config file is error,use default configuration.");
goto end_config;
}
sscanf(buff,"%02X:%02X:%02X:%02X:%02X:%02X",
(rt_uint32_t*)&mac_addr[0], (rt_uint32_t*)&mac_addr[1], (rt_uint32_t*)&mac_addr[2],
(rt_uint32_t*)&mac_addr[3], (rt_uint32_t*)&mac_addr[4], (rt_uint32_t*)&mac_addr[5]);
__log("set e%d mac:%02X:%02X:%02X:%02X:%02X:%02X", which,
mac_addr[0], mac_addr[1], mac_addr[2],
mac_addr[3], mac_addr[4], mac_addr[5]);
drv_emac_set_addr(which, mac_addr);
}
}
end_config:
if(file)
fclose(file);
drv_emac_init();
#ifdef CONFIG_VC0768_EMAC0
eth_dev = (struct eth_device*)rt_device_find(EMAC0_NETIF_NAME);
if(eth_dev)
{
#if LWIP_NETIF_STATUS_CALLBACK
netif_set_status_callback(eth_dev->netif, netif_status_callback);
#endif
}
#endif
#ifdef CONFIG_VC0768_EMAC1
eth_dev = (struct eth_device*)rt_device_find(EMAC1_NETIF_NAME);
if(eth_dev)
{
#if LWIP_NETIF_STATUS_CALLBACK
netif_set_status_callback(eth_dev->netif, netif_status_callback);
#endif
}
#endif
void rt_thread_exit(void);
rt_thread_exit();
}
int test_emac_sample(void)
{
rt_thread_t tid = RT_NULL;
tid = rt_thread_create("emac_sample", test_emac_thread, NULL, 2048, 22, 10);
if(tid)
rt_thread_startup(tid);
return 0;
}
late_initcall(test_emac_sample);
首次上电时,MAC地址的配置文件不存在,这时候会随机生成MAC地址,并写入文件,需要注意的是,MAC地址的第0字节要设置成单播地址,串口日志如下:
[WRN]: [test_emac_thread:0051]: emac config file not exist,try to create it.
[DBG]: [test_emac_thread:0058]: emac config file create success.
[DBG]: [test_emac_thread:0079]: set e0 mac:AE:7E:34:16:75:7A
[DBG]: [test_emac_thread:0088]: write config file success
[DBG]: [test_emac_thread:0079]: set e1 mac:3E:D9:4D:60:AA:40
[DBG]: [test_emac_thread:0088]: write config file success
lwIP-2.1.0 initialized!
[DBG]: [phy_monitor_thread_entry:0944]: e1 link up
[DBG]: [netif_status_callback:0024]: e1 got ip
[DBG]: [netif_status_callback:0025]: address: 10.200.30.85
[DBG]: [netif_status_callback:0026]: gateway: 10.200.30.250
[DBG]: [netif_status_callback:0027]: netmask: 255.255.255.0
非首次上电时,MAC地址的配置已存在,直接读取文件中的MAC地址,串口日志如下:
[DBG]: [test_emac_thread:0098]: open config file ok
[DBG]: [esFSYS_fread:0579]: EOF of regular file.
[DBG]: [test_emac_thread:0113]: set e0 mac:AE:7E:34:16:75:7A
[DBG]: [test_emac_thread:0113]: set e1 mac:3E:D9:4D:60:AA:40
lwIP-2.1.0 initialized!
[DBG]: [phy_monitor_thread_entry:0944]: e1 link up
[DBG]: [netif_status_callback:0024]: e1 got ip
[DBG]: [netif_status_callback:0025]: address: 10.200.30.85
[DBG]: [netif_status_callback:0026]: gateway: 10.200.30.250
[DBG]: [netif_status_callback:0027]: netmask: 255.255.255.0



















 8635
8635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











