






点击上方,选择星标或置顶,每天给你送干货 !
!
阅读大概需要7分钟
跟随小博主,每天进步一丢丢


作者: 龚俊民(昵称: 除夕)
学校: 新南威尔士大学
单位:Vivo AI LAB 算法实习生
方向: 自然语言处理和可解释学习
知乎: https://www.zhihu.com/people/gong-jun-min-74
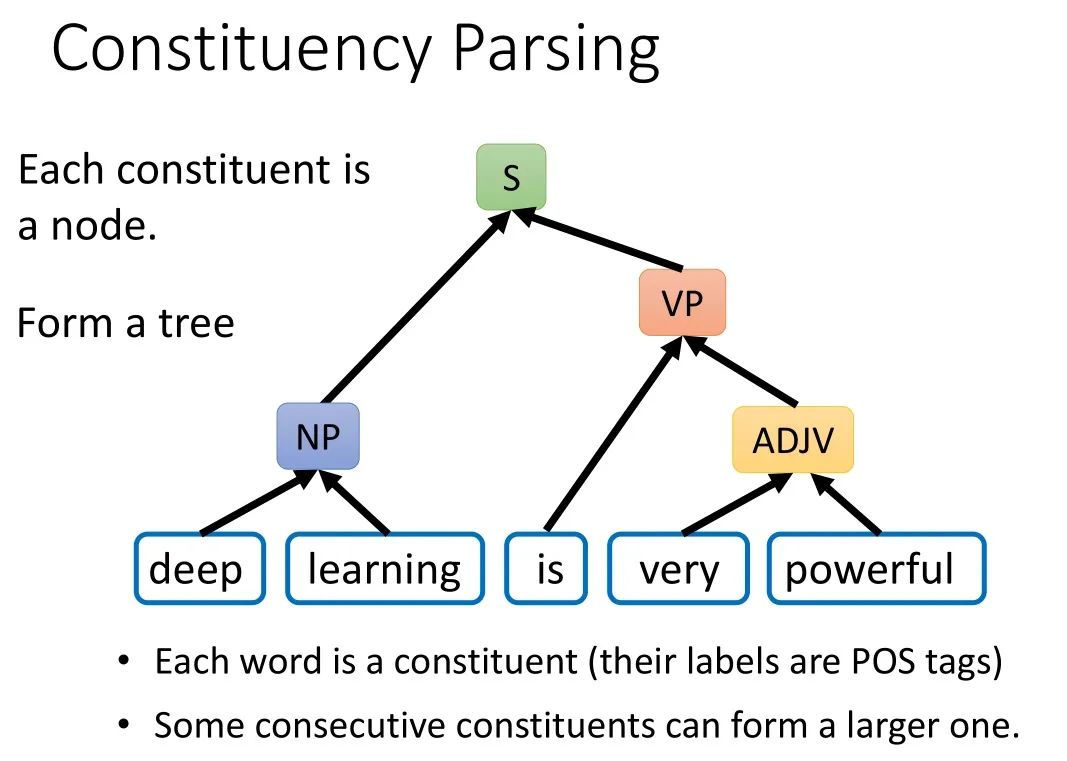
前言:NLP 任务中,句法分析有两种,一种是成分句法分析,另一种是依存句法分析。句法分析不适用于之前的 NLP 任务分类体系。它的输出形式相对来说会比较不一样。
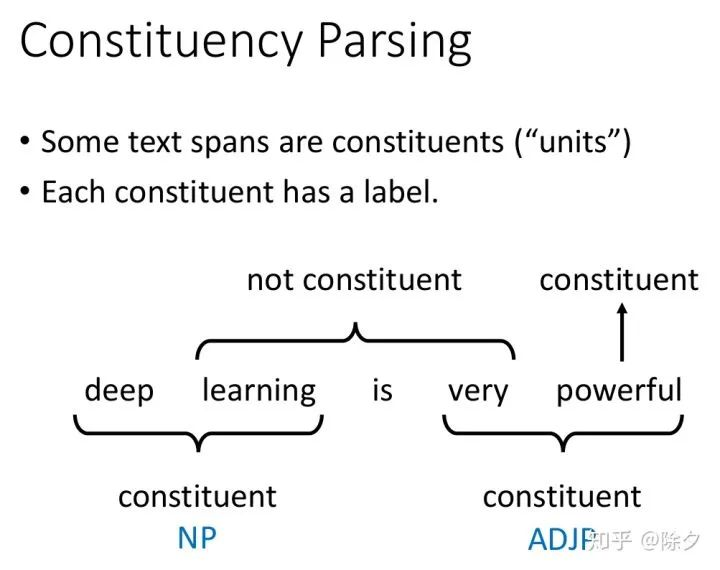
成分句法分析简单来说就是找到一个句子的组成成分。我们要怎样知道一个单位是不是成分呢。这需要语言学上的方法来鉴定。一般是我们凭着直觉判断的主谓宾。每一个成分都会有一个标签,比如 deep learning 的标签是 NP,very powerful 的标签是 ADJP。

成分句法分析的标签类型还是比较多的。它的组成更倾向于是短语级别的。所有词性标注的词项标签也都是可能的标签。
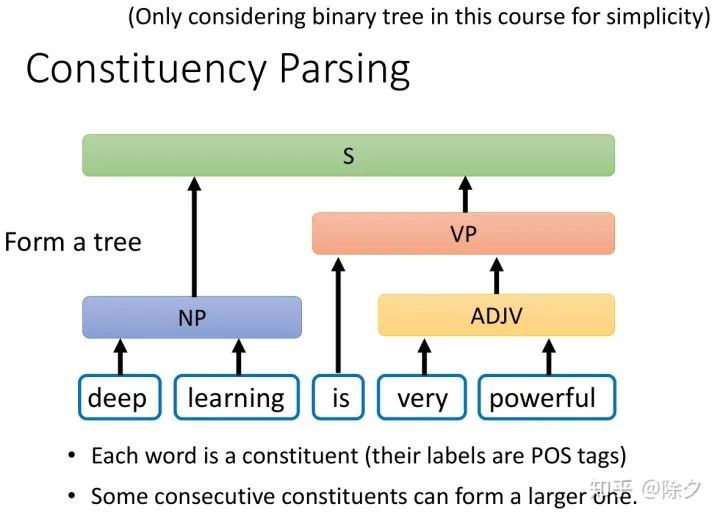
成分句法分析要做的是,给定一个句子,句子中每个词汇都是成分。它们的标签,就是它们的词性。接着,相邻的成分,可以组合成一个更大的单位。比如 deep 和 learning 可以组合起来成为一个名词短语。very 和 powerful 也可以组合起来,变成一个形容词短语。is 和 very powerful 又可以组合起来,变成一个动词短语。最后这个动词短语和名词短语组合起来,变成整个句子。
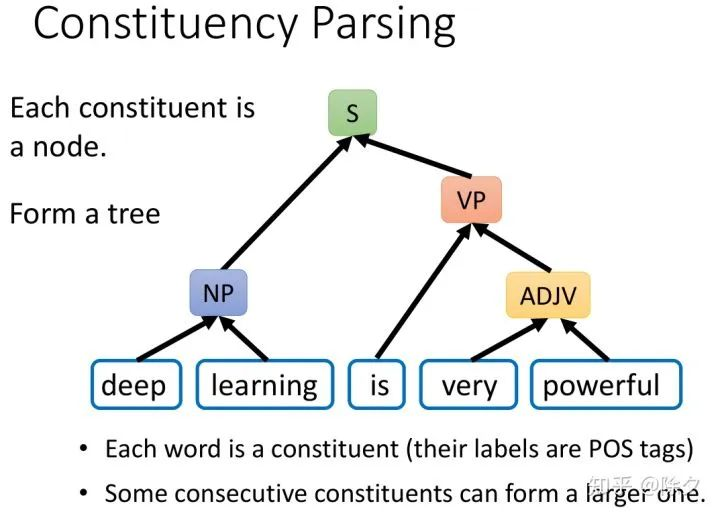
它最终呈现出一个树状的结构。每一个成分作为树中的一个节点。我们假设每一个节点都只会有两个分支。树状结构最底端,是词汇。当然在成分句法分析中,一个节点可以分出多种分支,但我们这里只考虑二叉树的情况。
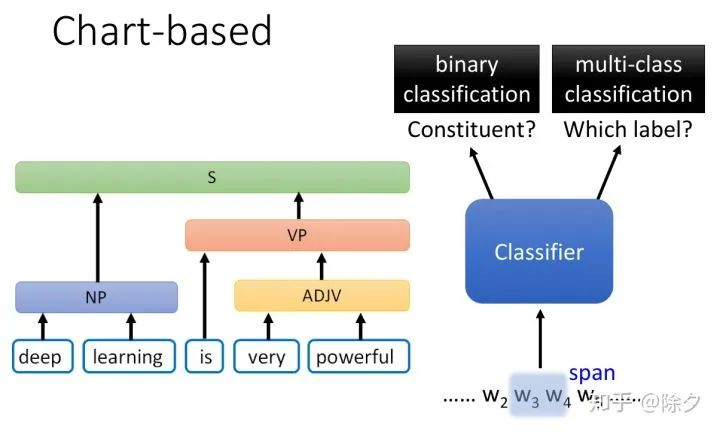
成分句法分析通用的解决方案是怎样的呢?一个是 char-based 方案。我们训练一个分类器,输入是一串 tokens,它决定这个 span 是不是成分。如果确定它是成分,接下来我们要用另一个分类器,对该成分确定它的标签。
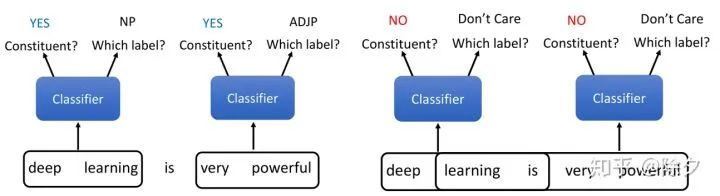
对于不是成分的短语,我们则不会关心它被分类出来的标签。
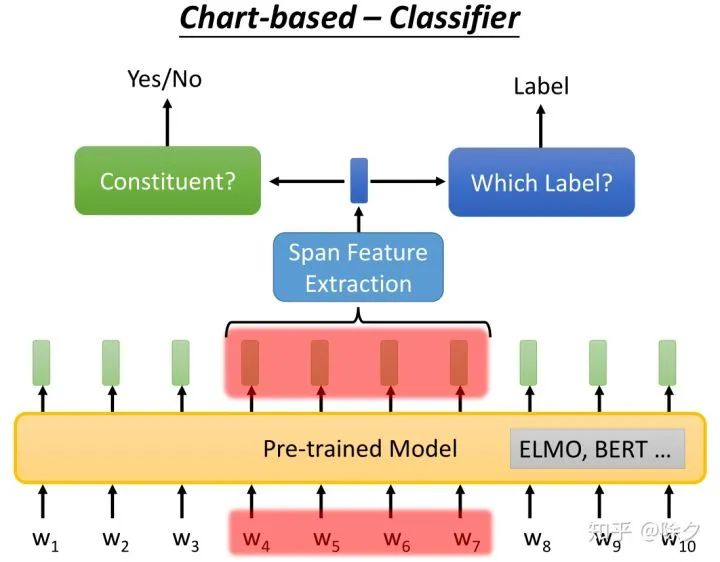
这个分类器的网络架构,和共指消歧的分类器架构其实大同小异。我们会把一串序列喂给 BERT 模型,得到融合了上下文信息的每个token的嵌入。接着我们把我们关心的那个 span,用一个 span feature extraction 去抽出一个向量。我们关心的是 w4-w7 是不是一个成分。一个分类器对该向量去分类它的成分,如果是成分,则让另一个去分类它的标签。接下来我们端对端地训练,就结束了。
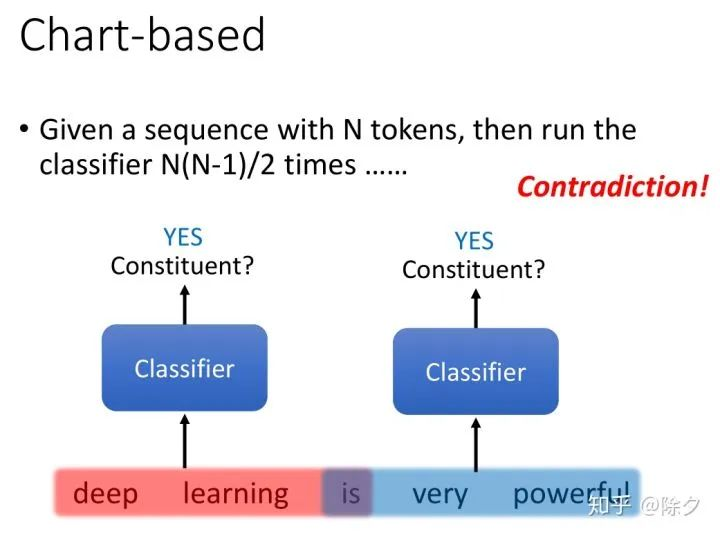
parsinng 看起来似乎很简单,但是也会有它任务独有的难点。对于一个有 N 个 tokens 的序列,我们需要跑 N(N-1)/2 次。就可以把所有的 span 都判断它是不是成分。但实际上,这个问题没有那么简单。这种方式会出现重叠成分的情况,即前半部分的成分和后半部分的成分中间共享了同样的 token。
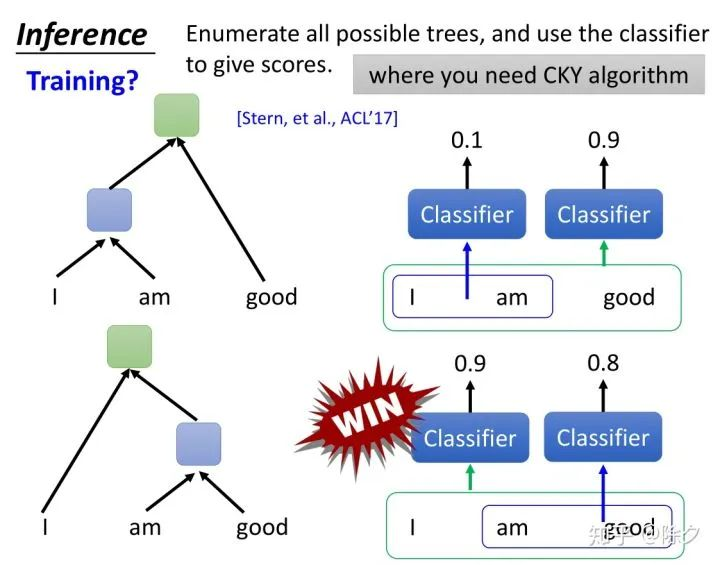
实际上在推断的时候,我们会穷举所有可能的成分树的结果。然后用模型对其一个个评分。接着,我们筛选出合法的树状结构,去看看哪一个得分最好。这样就可以避免成分重叠的情况。我们要如何穷举所有可能树状结构呢?我们需要用CKY算法。它详细如何做,可以参考一下过去的文献。既然我们推断的时候,是通过对每棵树评分取最好。在训练的时候,我们也不完全会把parsing的问题规范化为简单的二分类问题。因为训练时训练分类器,但推断时,是穷举树状结构,评出哪个树状结构最好。两个过程就会不一致。实际上训练的时候,是更为复杂的。它更倾向于对一棵树进行评分。它的损失不是简单的交叉熵,而是考虑了树状结构的损失。这个损失代表了树状机构的评分。

另一个方法叫作基于转移的方法。它的精神是把产生的句子加入到一个 Buffer 中,加上一连串的操作,就可以做到成分句法解析。我们接下来举一个实际例子说明。
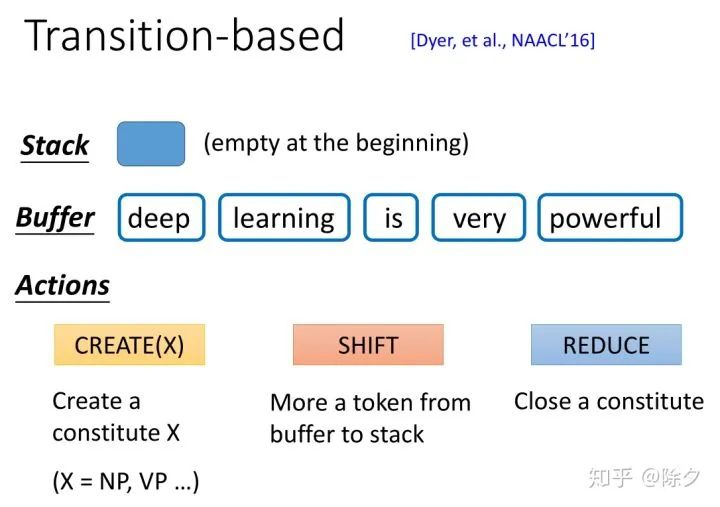
首先我们会有一个 Stack 数据结构 和 一个 Buffer。一开始,Stack 是空的,Buffer 里面则装有整个句子的 tokens。接着我们有三种候选操作,CREATE(x),表示创建一个成分,SHIFT,表示把Buffer 中的某个 token 放入 Stack 中。REDUCE,表示结束一个成分。
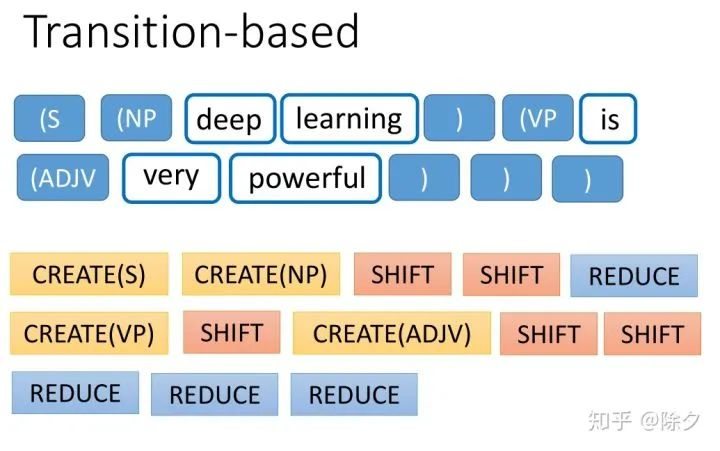
模型要根据 Stack 和 Buffer 中的内容,决定接下来要采取什么样的行为。一开始会 CREATE(S),S 代表一个句子,它用 (S 来表示。接着我们再 CREATE(NP),用 (NP 表示,并往后 SHIFT,把 Buffer 中的第一个 token,"Deep",挪到 Stack 中。再执行一次 SHIFT,把 Buffer 中的token, "learning",挪到 Stack 中。接下来根据 Stack 和 Buffer 中的内容,模型要决定结束成分的操作 REDUCE,用半括号 ) 表示,表示确定之前的 deep learning 是一个名词成分。接着我们往下 CREATE(VP),用 (VP 表示。再把 "is" SHIFT 到 Stack 中。动词短语还未结束,模型又会往下 CREATE(ADJV),创建一个形容词短语,用 (ADJV 表示。以此类推直到创建出一个完整的成分解析树。基于转移方法的重点在,怎样决定在哪一个时刻要采取什么行为。
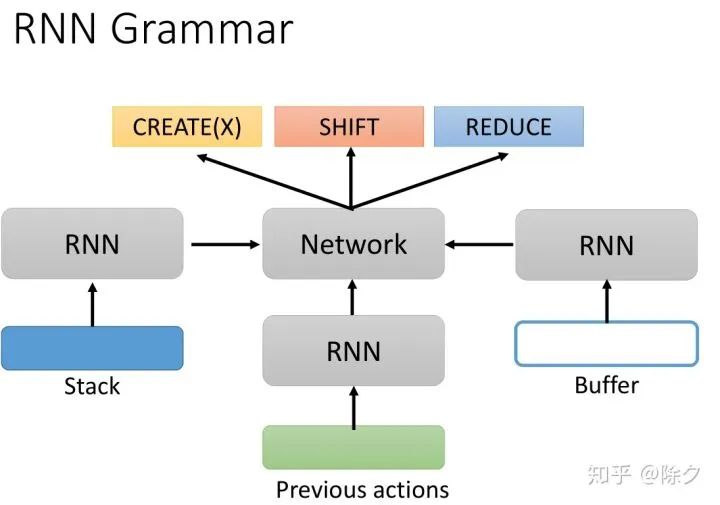
在以前是用一个 RNN 来决定要采取哪一个动作的。我们会把 Stack 中的内容和Buffer 中的内容,分别通过一个 RNN,再把之前的动作也通过一个RNN。这三个部分的特征相接后,再喂给一个网络做动作的分类。
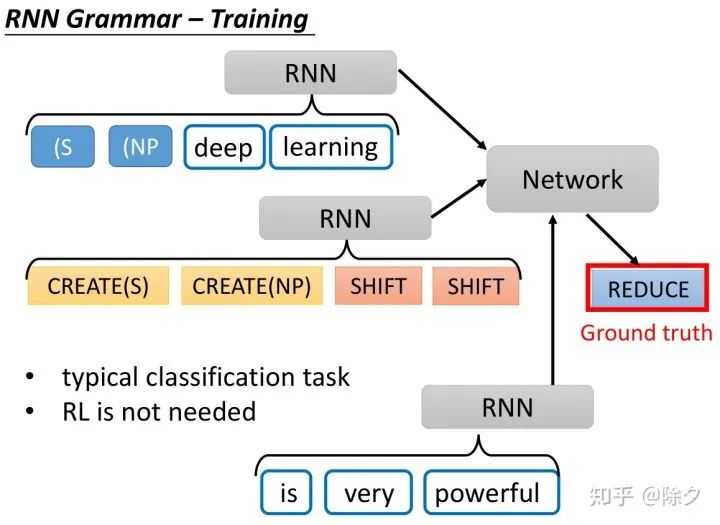
实际在训练的时候,我们可以把正确答案转换为行为操作的形式。这整个过程是一个一般的分类任务。我们只是把三种不同的动作,当作是三种不同的类别。我们不需要用到强化学习。

还有另外一种做法和基于转移的方法非常类似。只是讲法上略有不同。在 15 年的时候,Seq2Seq 模型,不像今天这么流行。最常用的 Seq2Seq 应用,都在翻译任务上面。它把句法解析问题,看作是翻译问题来做。
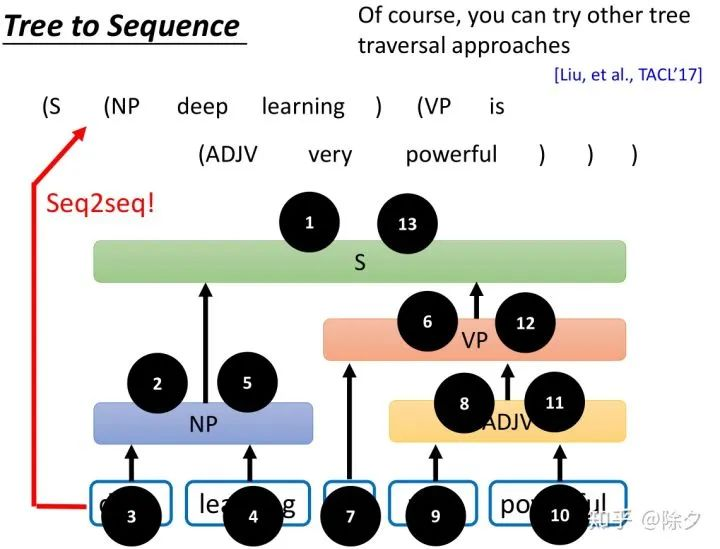
我们可以把树状的结构表示为一个序列,比如用深度优先遍历方法,由上而下,由左到右把每个节点按遍历顺序放在序列中。这样,我们就只需要一个 Seq2Seq 模型就可以做了。我们也可以采用别的树状结构转换为序列的方法。比如从下至上,层级的,既由下而上又由上而下的混合方法。最后结论是既由上而下,又由下而上构建会比较好。
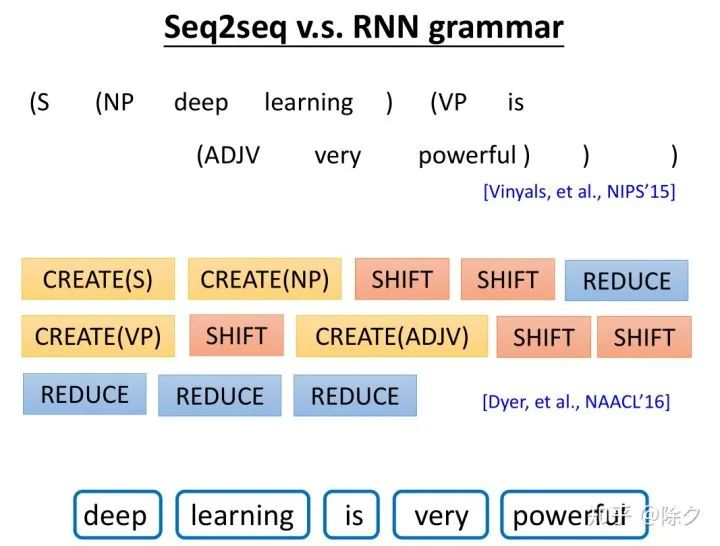
Seq2Seq 的方法和基于转移的 RNN grammar 的方法没有很大不同。因为树状结构转换的序列与动作序列,是存在一一对应的关系的。
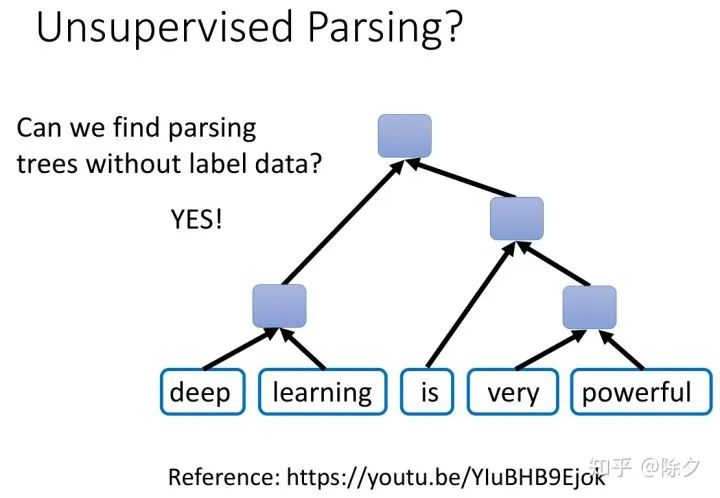
之前讲的都是无监督的成分句法解析,我们可不可以做一个无监督的句法解析呢?之前助教有做过无监督成分句法分析的讲解,讲解视频如下。
https://www.youtube.com/watch?v=YIuBHB9Ejok&feature=youtu.be
更多关于成分句法分析的综述和论文详解,这边推荐一个知乎大牛的资源:
https://zhuanlan.zhihu.com/p/45527481
https://zhuanlan.zhihu.com/godweiyang
本文图片来自李宏毅的课程,视频见(需要梯子):
https://www.youtube.com/watch?v=8rDN1jUI82g&feature=youtu.be
Reference
• [Vinyals, et al., NIPS’15] Oriol Vinyals, Lukasz Kaiser, Terry Koo, Slav Petrov, Ilya Sutskever, Geoffrey Hinton, Grammar as a foreign language, NIPS, 2015
• [Dyer, et al., NAACL’16] Chris Dyer, Adhiguna Kuncoro, Miguel Ballesteros, Noah A. Smith, Recurrent Neural Network Grammars, NAACL, 2016
• [Stern, et al., ACL’17] Mitchell Stern, Jacob Andreas, Dan Klein, A Minimal Span-Based Neural Constituency Parser, ACL,2017
• [Liu, et al., TACL’17] Jiangming Liu, Yue Zhang, In-Order Transition-based Constituent Parsing, TACL, 2017
添加个人微信,备注:昵称-学校(公司)-方向,即可获得
1. 快速学习深度学习五件套资料
2. 进入高手如云DL&NLP交流群

记得备注呦


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









