








本文介绍的论文题目是《BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer》
论文下载地址为:https://arxiv.org/abs/1904.06690
将Transformer运用到推荐系统中,前面也介绍过许多篇相关的论文了,如阿里的DSIN、BST等等,他们都使用Transformer的Encoder部分的网络结构作为模型中的一部分进行使用。同时,在自然语言处理领域,同样使用Transformer的Encoder部分的预训练模型Bert取得了巨大的成功,其一些训练的思路能否同样应用到推荐系统中呢?答案是肯定的,本篇介绍的文章就是如此,一起来了解一下。
1、背景
在推荐系统中,精确捕捉用户的兴趣,是比较关键的。而用户的兴趣是随着历史行为的变化而不断变化的,为了捕捉这种兴趣的变化,一些序列推荐算法被提出。如使用马尔可夫链,使用RNN模型等等。
无论是马尔可夫模型还是RNN模型,都是使用用户从前到后的历史行为序列信息,这种单向的结构有时对历史行为序列所能带来的作用是有一定限制的;同时,这种顺序性的假设有时候在实际生活中并不适用,如下图中,三种口红的点击顺序,对于最后的推荐结果影响并不是很大:
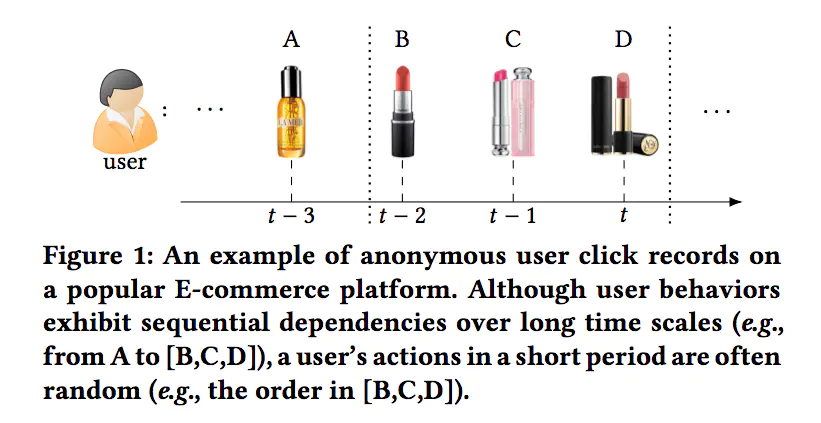
因此,本文认为双向模型对于序列推荐来说,更加有效。由于用户的行为序列很像是文本序列,而Bert模型算是当前自然语言处理领域数一数二的模型,其使用Transformer的Encoder进行预训练任务,能够有效利用双向信息,因此本文考虑将Bert用于推荐任务。接下来,咱们就来介绍BERT4Rec模型吧。
2、BERT4Rec模型介绍
使用BERT进行序列化推荐,其整体的模型结构如下:
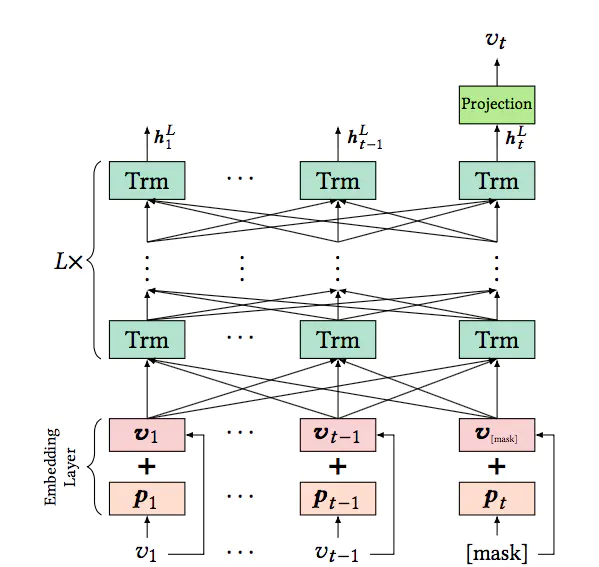
2.1 问题定义
在序列化推荐中,我们有如下的符号定义
| 结构 | 描述 |
|---|---|
| 用户集合 |
|
| 物品集合 |
|
| 用户历史行为序列 |
|
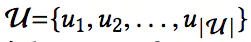
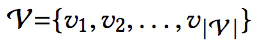
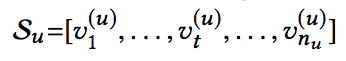
我们的目标是预测下一时刻用户与每个候选物品交互的概率:
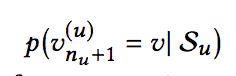
2.2 Embedding Layer
模型的输入主要是用户的历史交互序列,对交互序列中的每一个物品i,其Embedding包含两部分,一部分是物品的Embedding,用vi表示(整个Embedding矩阵用E表示,不仅用在输入层,还用在输出层),另一部分是位置信息的Embedding,用pi表示。这里的pi是可学习的,而不是像最开始提出的Transformer一样是固定的。
另一点需要指出的是,输入并不是使用用户所有的历史行为信息,而是使用最近N个行为。因为用户的行为序列长度差别很大,如果不加限制,可能导致模型过大,性能降低。
2.3 Transformer Layer
Transformer Layer的结构如下:
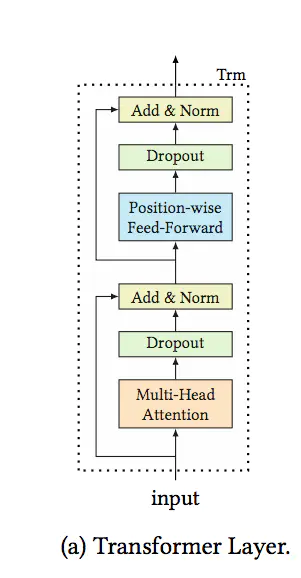
这里具体的Transformer的细节咱就不讲了,之前我写过一篇详细剖析整个过程的文章,感兴趣的同学可以查看:https://www.jianshu.com/p/2b0a5541a17c
对于模型框架中的第l层Transformer Layer,输入为Hl,首先是Multi-Head Self-Attention过程:
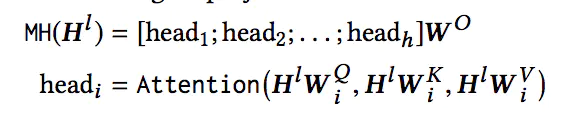
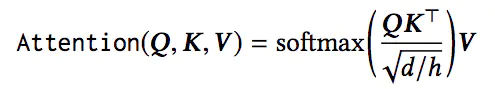
其次是DropOut和Add & Norm过程,这里的Add操作和ResNet类似,使得模型的层数可以非常深,而Norm是我们熟悉的BN操作,其计算方式如下:
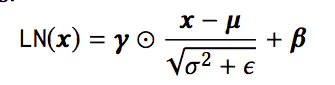
之后是Position-wise Feed-Forward Network,Position-wise的意思是说,每个位置上的输入分别输入到前向神经网络中,计算方式如下:
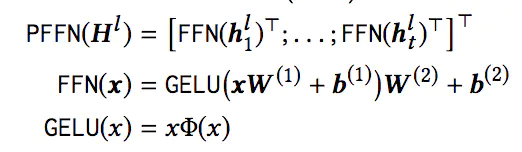
这里采用的激活函数是 Gaussian Error Linear Unit (GELU) ,而非RELU,这个激活函数还是第一次见,其出自论文https://arxiv.org/abs/1606.08415,
GELU的计算公式如下:
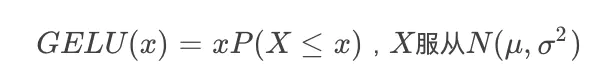
原文中和本文中均使用N(0,1)。GELU和Relu以及ELU的对比图如下:
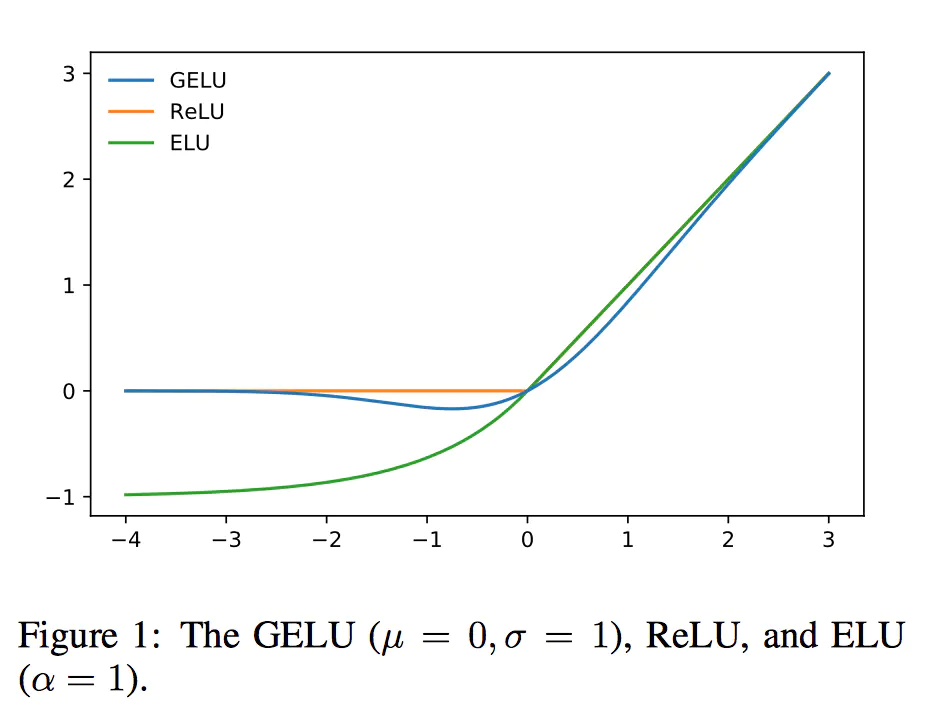
Gelu在relu的基础上加入了统计的特性,在论文中提到的好几个深度学习任务中都取得了更好的实验结果。
最后还是一个Dropout和Add & Norm过程。
2.4 Output Layer
在经过L层的Transformer Layer之后,得到的输出为HL,最后经过两层全连接网络得到最终的输出:
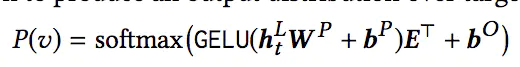
其中,最后一层的参数E,是物品的Embedding矩阵,和输入层是一样的矩阵。
2.5 模型训练和预测
首先再来仔细看一下BERT4Rec的结构,以及对比一下另外两个序列推荐模型:

我们的目的是预测用户下一个要交互的物品vt+1,对于传统的序列推荐模型,如上图中的RNN模型,输入是[v1,v2,...,vt],转换为对应的输出为[[v2,v3,...,vt+1],那么我们自然可以拿最后一个时刻的输出来作为物品进行推荐。
而在BERT4Rec中,并没有这样的转换过程,输入[v1,v2,...,vt-1],其输出只不过是包含了上下文信息的向量[h1,h2,...,ht-1]罢了。在上面的图片中,假设我们要预测用户t时刻的交互物品vt,如果直接把vt作为输入,那么其余每个物品在Transformer Layer中看到目标物品vt的信息,这样就造成了一定程度的信息泄漏。因此图中把对应位置的输入变成了[mask]标记。
训练和预测都可以采用上图中的方式,在预测下一个物品时,在输入序列的最后添加一个[mask]标记,共同作为输入。但是为了提升模型的泛化能力,让模型训练到更多的东西,同时也能够创造更多的样本,在训练阶段,借鉴了BERT中的Masked Language Model的训练方式,随机的把输入序列的一部分盖住(即变为[mask]标记),让模型来预测这部分盖住地方对应的物品:
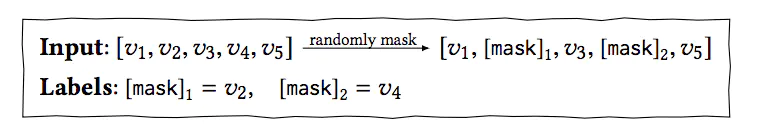
采用这种训练方式,最终的损失函数为:
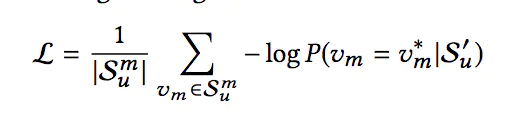
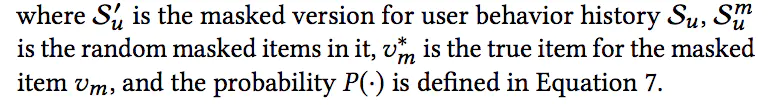
3、实验结果
简单看一下实验结果吧。
文章首先对比了模型和一些Base模型在4个数据集上的表现:
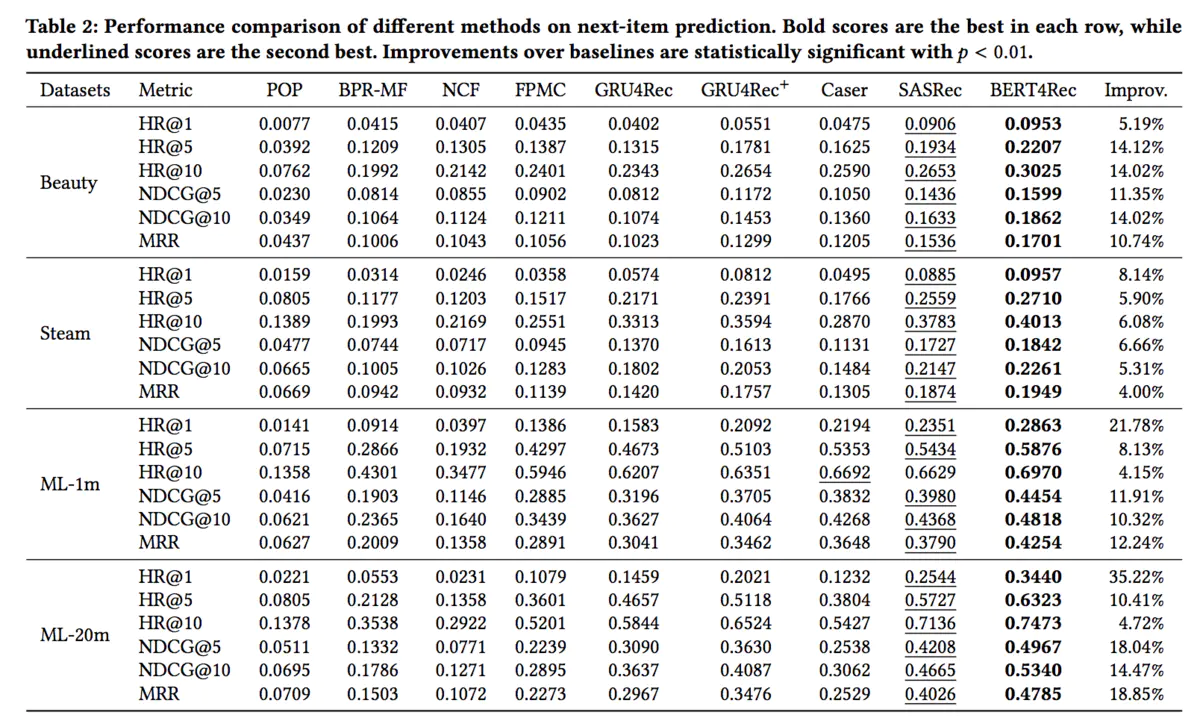
可以看到BERT4Rec模型相较于Base模型,其性能都有较大提升。
接下来,是参数的对比,首先是Embedding的长度d:
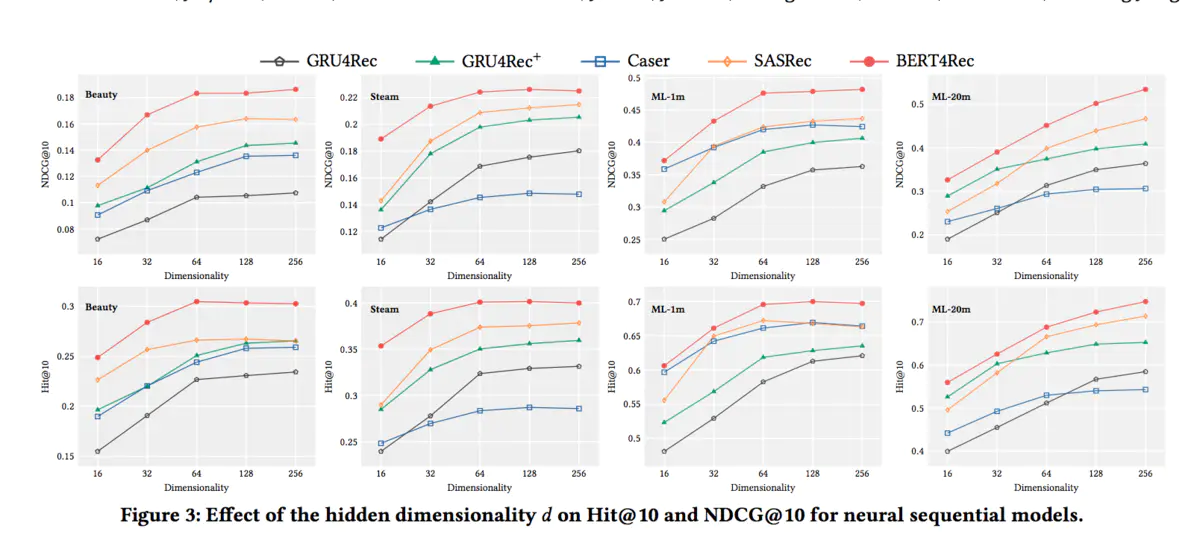
Embedding的长度越长,模型的效果更好。随后是训练时盖住物品的比例:
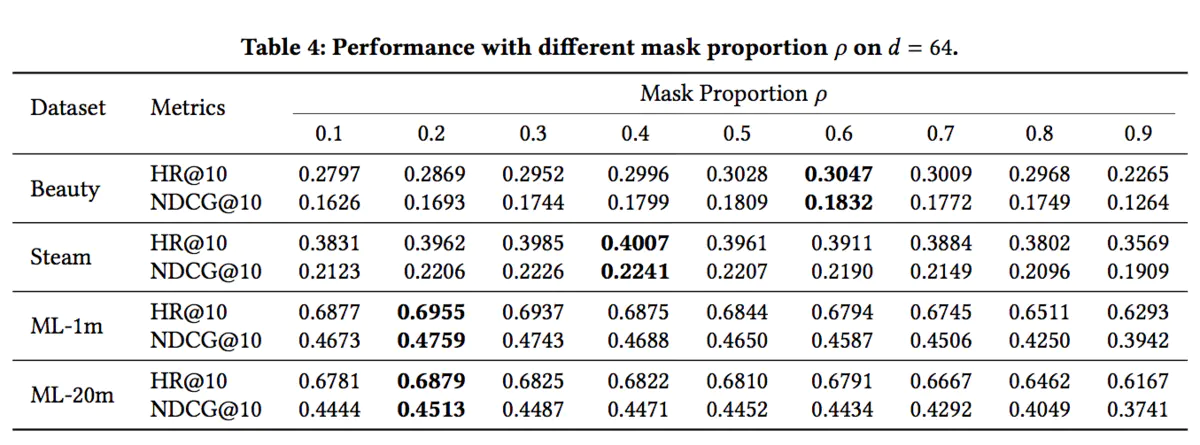
对于不同的数据集来说,最佳比例并不相同。然后是序列的最大长度N:
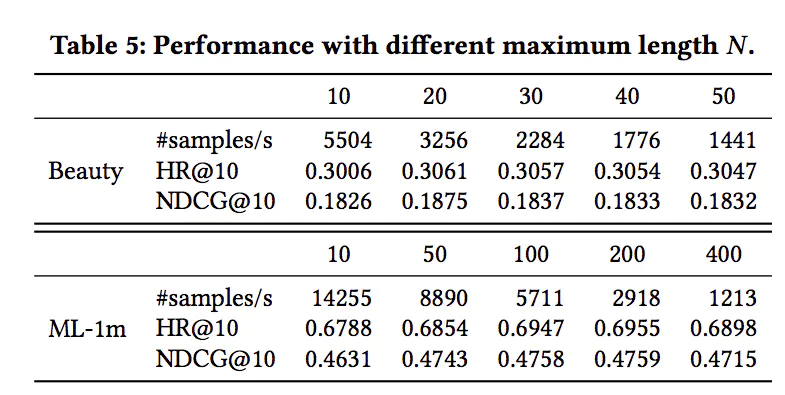
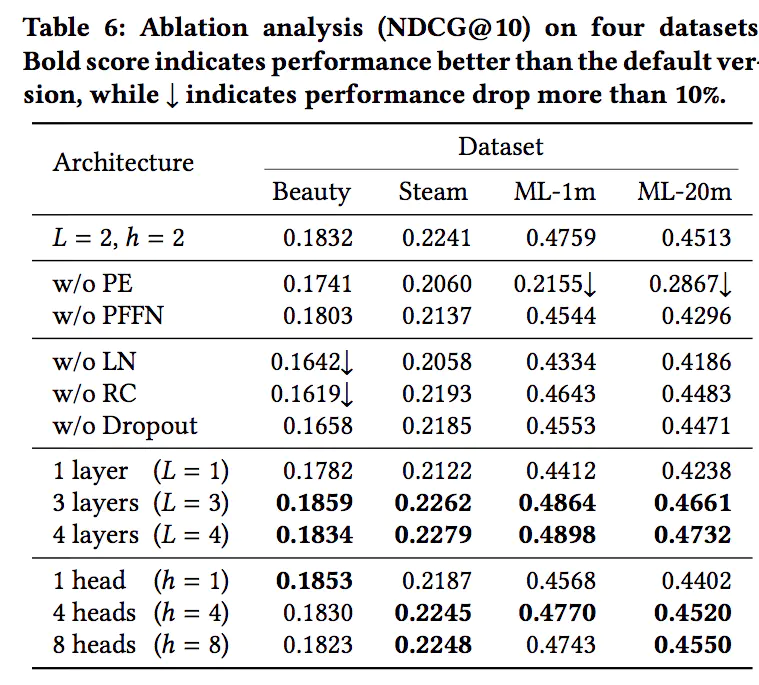
同样,不同的训练集,最佳的序列长度也不相同。最后,是对模型结构的一些对比试验,主要有是否使用PE(positional embedding),是否使用PFFN(position-wise feed-forward network),是否使用LN(layer normalization),是否使用RC(即Add操作,residual connection),是否使用Dropout,以及Transformer Layer的层数和Multi-head Attention中head的个数,结果如下:
4、BERT4Rec VS BST
好了,啰嗦了这么多,最后再多说一点,咱们之前也介绍过一个使用Transformer的推荐模型BST(Behavior Sequence Transformer),其结构如下:
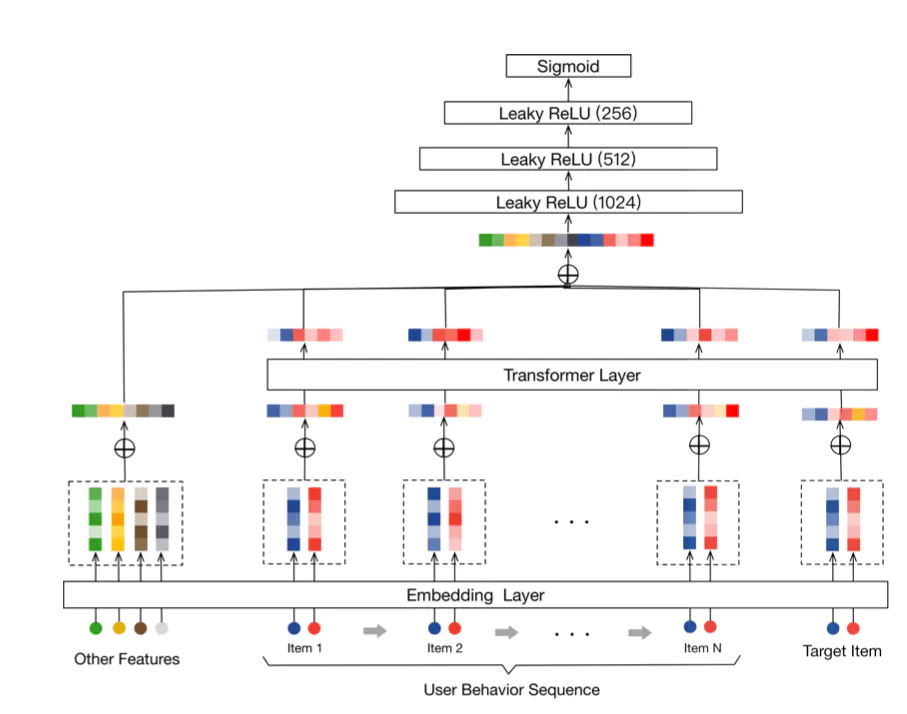
对BST模型来说,需要输入一个target item,模型输出的是点击这个target item的概率;而对BERT4Rec模型来说,模型一次性输出所有候选物品的点击概率,因此在参数差不多的情况下,但从性能而非预测精度来说,BERT4Rec肯定是更好的。因此个人认为,BST用在精排阶段更加合适,而BERT4Rec可以用于召回阶段,也可用于精排阶段。

















 653
653

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









