






每天给你送来NLP技术干货!
转载 | 知乎
作者 | 一点人工一点智能
原文链接 | https://www.zhihu.com/question/495386434/answer/2197591558
学术分享,侵删
01 多模态简介
1. 知识图谱的多模态数据来源
本节探讨多模态知识图谱的问题。前面曾多次提到,知识图谱的数据来源不仅仅是文本和结构化数据,也可以是图片、视频和音频等视觉或听觉形式的数据。多模态就是指视觉、听觉和语言等不同模态通道的融合。能够充分融合和利用语言、视觉和听觉等多种模态来源数据的知识图谱叫作多模态知识图谱。
一方面,凡是蕴含知识的原始数据都可以作为知识图谱构建的数据来源,例如对于图片,也需要完成类似于文本中的实体识别和关系抽取任务。另一方面,多种模态的数据也可以被用来增强知识图谱上实现实体对齐、链接预测和关系推理的效果,这就好比人类在完成推理任务时,也会充分利用视觉、听觉信号加强认知层的推理能力。
此外,如果将图片、视频中的实体采用类似于实体链接等技术与知识图谱中的实体进行链接,就可以充分利用知识图谱增强对多模态数据的分类、检索和识别等能力,后面会看到知识图谱被用来帮助解决图片的零样本分类问题。这些都是研究多模态知识图谱的意义所在。
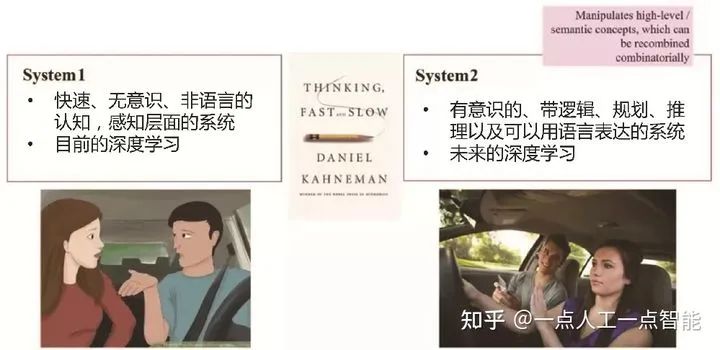
2.System 1和System 2
先来看一些观点。正如深度学习专家Yoshua Bengio在NeuralPS 2019的大会报告中所介绍的,在认知理论中,大家有这样的一个共识,即人的认知系统包含两个子系统,如图1所示。直觉系统System1,主要负责快速、无意识、非语言的认知,即所谓感知层面的系统,这是目前深度学习主要做的事情。逻辑分析系统System2,是有意识的、带逻辑、负责规划和推理以及可以用语言表达的系统,这方面深度学习能力还很有限,而知识图谱关注的正好是这部分的系统。这里有一个值得深思的问题,就是这两个系统是分离的两个系统,还是一个系统的两个部分?至少到目前为止,以语言和知识为代表的符号空间和以神经网络为代表的向量空间还是被割裂的两个不同的空间。我们有可能把这两个系统融为一体吗?
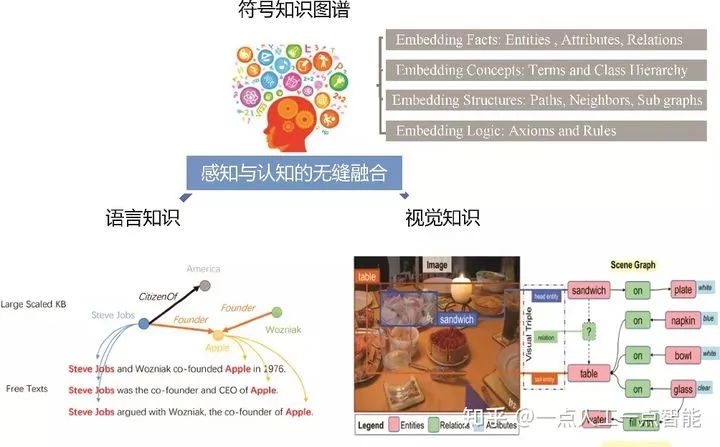
3. 知识图谱:衔接感知与认知
认知科学家道格拉斯·霍夫施塔特有一个观点认为“记忆是高度重建的。在记忆中进行搜取,需要从数目庞大的事件中挑选出什么是重要的,什么是不重要的,强调重要的东西,忽略不重要的东西。这种选择过程实际上就是感知。”DeepMind联合创始人德米什·哈萨比斯也曾提到:“我们能否从自己的感知构建,利用深度学习系统,并从基本原则中学习?我们能否一直构建,直到高级思维和符号思维?”所以,认知的核心过程与感知的关系非常密切,并可能就是一个过程。
知识图谱的向量表示使得我们可以利用表示学习获得概念、类层次、实体和关系的嵌入,并进而获得图结构、路径、子图的嵌入。同时,有关本体嵌入、规则学习(Rule Learning)的工作又使得逐步能够在向量空间实现一些简单的逻辑推理。各种嵌入的技术使得可以将来源于文本中的词、短语、句子,来源于图片或视频中的对象、语义关系,来源于知识图谱中的实体、概念和关系都投影到统一的表示空间,如图2所示。这是否为感知和认知的无缝融合提供了一种实现的可能呢?
4. 知识图谱的多模态本质
再来看多模态的概念。模态可以理解为某种类型的信息和(或)存储信息的表示形式,每一种信息的来源或者形式都可以称为一种模态。例如,人有触觉、听觉、视觉、味觉和嗅觉。再比如多种多样的传感器如雷达、红外等。同时,模态也可以有非常广泛的定义,比如可以把两种不同的语言当作两种模态,甚至在两种不同情况下采集到的数据集,也可认为是两种模态。目前,多模态在机器学习中比较热门的研究方向是图像、视频、音频、语义文本之间的多模态学习,而在这四者中讨论得最多的则是图像与文本的多模态。
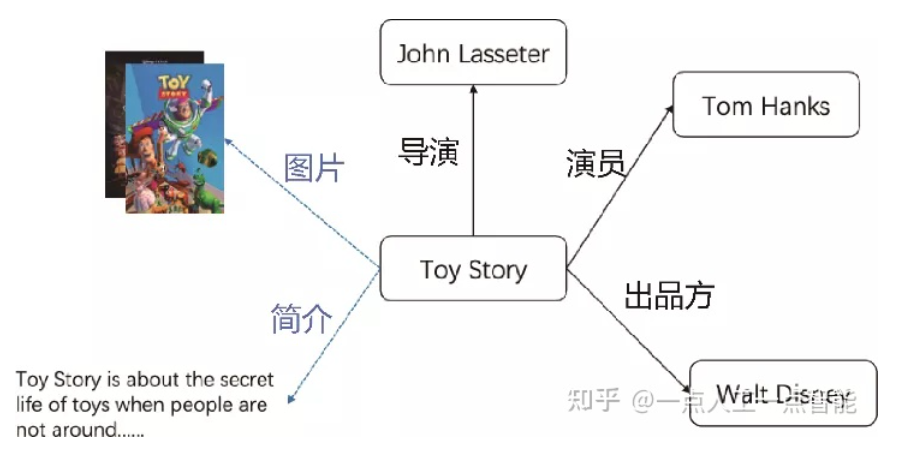
事实上,知识图谱本来就应该是多模态的。如图3所示,在很多搜索引擎提供的知识图谱搜索结果中,都已经包含多模态的数据。知识图谱是链接数据的概念。有关一个实体的数据可能是结构化的属性描述数据,也可能是文本描述型数据,也可能存在于一张图片或一段视频中。如果能够将有关这个实体的各种模态数据都关联起来,将有力地提升信息搜索的用户体验。当然,后面将会看到,构建多模态的知识图谱的价值不止在于提升搜索体验。

02 多模态的价值与作用
1. 模态知识互补
多模态有什么作用呢?首先,不同模态通常包含同一对象不同方面的知识。例如在电商场景中,一部分商品可能有丰富的图片信息,但缺乏结构化的属性描述,而另一类商品则可能拥有丰富的结构化图谱数据,但缺乏对应的文本描述信息。通常,这些模态之间的知识是互补的。如果能充分挖掘和关联不同模态中的知识,将使得不同模态之间相互增强。
2. 基于多模态知识的实体消歧
多模态的数据也可以用来帮助提升实体消歧的效果。例如,要将文本“有人看到李娜在北京的一家超市购物”中的实体“李娜”链接到知识图谱中。但图谱中可能包含两个不同的李娜。一个是网球选手,另外一个是歌手。假如仅仅依靠文本信息,则无法消除这个歧义。但如果这段新闻还配有对应的图片,同时知识图谱中李娜实体也关联对应的照片,则能通过图片对齐来提升实体消歧的效果,如图4所示。

3. 跨模态的语义搜索
进一步,假如能够将多种模态数据与知识图谱中对应的实体实现正确的实体链接,就可以实现跨多种模态的语义搜索。例如,将新闻文本、视频和图片中有关李娜的实体提及、实体图片和实体视频都与知识图谱中的对应的李娜进行实体关联,就可以实现更加精准的语义关联检索,如图5所示。目前的搜索引擎一部分实现了图片的实体关联,但在文本和视频方面的实体关联还有很大提升空间。

4. 利用多模态数据补全知识图谱
既然可以通过知识抽取技术从文本中抽取有价值的信息补全知识图谱,当然也可以从图片、视频和时序数据中抽取有价值的信息用来补全知识图谱。事实上,视觉领域也有相应的关系抽取任务。此外,图片和文本描述数据还被用来增强知识图谱中已有实体的特征表示,以提升链接预测的效果。
5. 利用知识图谱增强多模态数据处理能力
反过来,知识图谱的融入也可以大大增强多模态数据处理的能力。例如,知识图谱被用来提升视觉等场景下的零样本学习等低资源学习的预测效果。融入知识图谱的模型也能够大大提升视觉语义理解的能力,提高视觉场景图谱的构建效果,提高视觉问答的用户体验,并增强视觉等多模态学习模型的可解释性,如图6所示。

03 多模态知识图谱举例
有关多模态知识图谱的研究由来已久。在语义网的早期有一个称为Linked Media的领域,其主要目的是把Linked Data的思想扩展到多媒体数据领域,通过建立文本、图片和视频中所包含实体对象之间的语义链接来增强跨不同模态数据之间的信息检索能力。接下来介绍几个多模态知识图谱的示例。
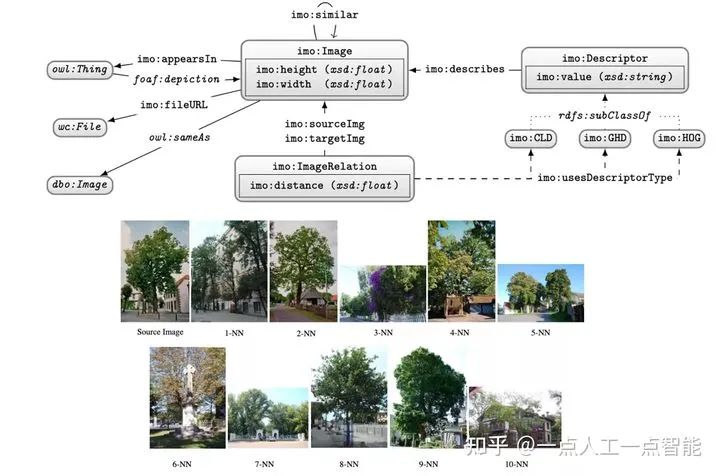
1. IMGpedia
作为模态知识图谱的先例,IMGpedia将语义知识图谱与多模态数据相结合。IMGpedia是一个大型的链接数据集,它从维基百科发布的图片中提取相关的视觉信息,同时为每张图像构建一个视觉实体(Visual Entity),并生成总计数量约1500万个相应的图像描述符。同时,将视觉实体与维基百科中对应的文章相关联,与DBpedia中的对应实体建立关联。
此外,IMGpedia还通过计算图片之间的相似度,建立了图片之间的相似性链接,其中的图像之间有4.5亿个视觉相似关系。IMGpedia的本体设计如图7所示。
2. MMKG
MMKG是一个融合有实体的结构化属性、数值特征(如实体坐标位置)和对应图像三种要素的多模态知识图谱。MMKG从三个典型的知识图谱出发构建,它选择在知识图谱补全文献中广泛使用的数据集FREEBASE-15K(FB15K)作为创建多模态知识图谱的起点,同时创建了基于DBpedia和YAGO的版本,称为DBpedia-15K(DB15K)和YAGO15K,并且将FB15K中的实体通过sameAs关系与其他知识图谱中的实体对齐。
在构建图像关系的过程中,MMKG从搜索引擎中获取了知识图谱中实体的相关图像,以生成对应的实体-图像关系。MMKG主要利用这种多模态的信息实现sameAs的链接预测任务,并取得了不错的效果,证明了多关系链接预测与实体匹配可以从多模态信号中受益,同时知识图谱补全也可以很好地利用多模态信息。
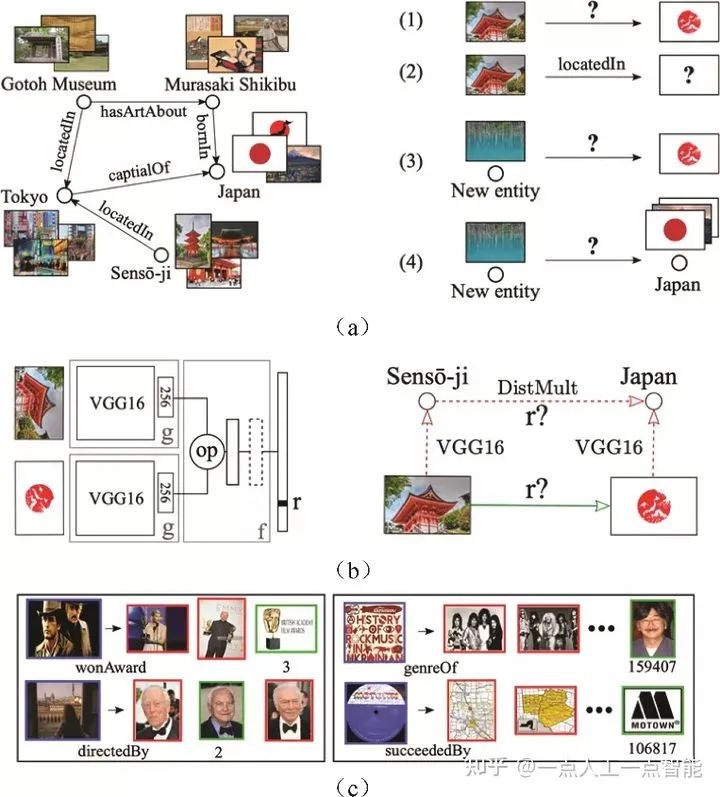
3. ImageGraph
与前面介绍的两个多模态知识图谱不同,ImageGraph中的每个实体都是图片,它旨在通过将大量图片组织成图片图谱,并建立图片实体之间的关联,解决视觉图像概念的关系推理问题,希望以此促进超出基本图像检索的复杂视觉检索应用的发展。其构造过程基于FreeBase的子集FB15K并沿用了其中的语义关系。与前文所提的数据集类似,通过爬取各大搜索引擎并基于Wikipedia URIs的视觉图像检索以及数据清洗,获得对应的图片。ImageGraph总计包含14870个实体、564010个三元组和1330个不同的关系类型。
ImageGraph提出了四个任务,以证明该图谱的存在意义。如图8所示,首先将知识图谱划分为seen类与unseen类的部分,然后给定一对unseen的图像,要求预测其中的关系;或者给定unseen类图像与一个关系,预测出尾实体的seen类图像,或者给定一个不属于知识图谱的全新unseen图像以及一个划分在unseen类的图像,对关系进行预测;给定一个不属于知识图谱的全新unseen图像以及一个划分在seen类的图像,对关系进行预测。最后的实验结果表明,这种图片实体构成的图谱有利于促进图片的相关性检索和搜索。
4. Richpedia
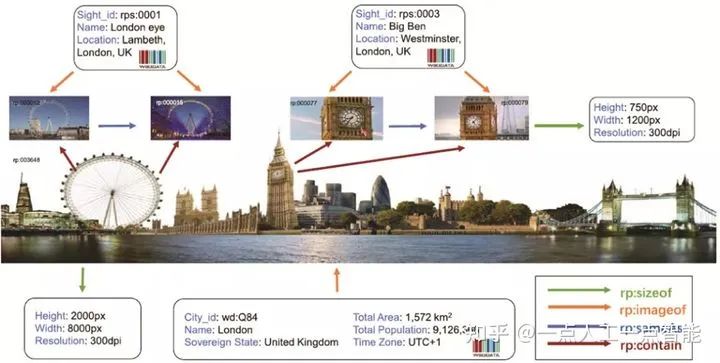
Richpedia的目标是构建一个大规模、全面的多模态知识图谱。Richpedia定义了一个更全面的视觉关系本体,其中包含了图谱实体、文本实体、图像实体及其之间的关系。如图9所示,首先构建了图像模态伦敦眼图像与文本模态知识图谱实体(DBpedia实体:London eye)之间的多模态语义关系(rpo:imageof),由于两个实体出现在同一张图上,所以之后还构建了图像模态实体伦敦眼与图像模态实体大本钟之间的多模态语义关系(rpo:nextTo)。
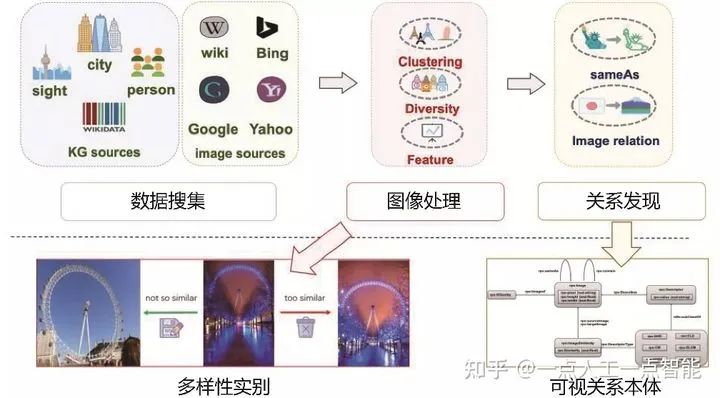
作者在构造图谱的过程发现了两个普遍问题:其一,实际多模态图谱中的图像资源有很大一部分是长尾分布,即平均每一个文本知识图谱实体在Wikipedia中只有很少的视觉信息;其二,由于视角或其他原因,一些图片丢失了原本包含在内的实体位置关系
针对第一个问题,Richpedia借助外部的其他数据来源(如维基百科、谷歌、必应和雅虎四大图像搜索引擎)来获得相应图像实体填充Richpedia,并且在这过程中对图像实体进行预处理和筛选,例如除去相似性高的图片,除去不相关的图片和多样性检测。针对第二个问题,作者利用基于规则的关系抽取模板,借助Wikipedia图像描述中的超链接信息,生成图像实体间的多模态语义关系。
04 多模态知识图谱研究
1. 多模态关系预测与推理
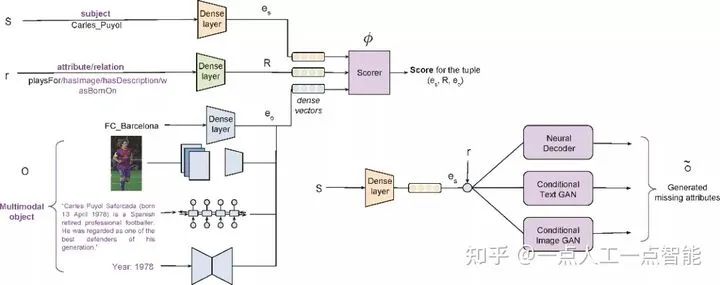
构建多模态知识图谱的一个重要作用是可以充分利用不同模态的数据实现关系预测与推理。通常的做法是,分别考虑知识图谱的结构信息(例如可以使用TransE或图神经网络)以及视觉和语言等多模态信息。通过将各个模态信息映射到同一个公共向量空间,实现不同模态间的信息交互。如图10所示,该工作使用了不同神经编码器学习实体和多模态数据的嵌入表示,同时在这个基础之上,将生成的向量表示作为属性生成任务的输入,以生成缺失的多模态属性,例如文本和图像等属性信息等。

多模态数据的另一个作用是用来提升知识图谱补全的效果。例如,可以为每个实体设置两种知识表示:基于结构的表示和基于图像的表示,并联合训练图像模型和结构知识模型。最后利用这些包含了多种模态信息的实体向量表示提升知识图谱补全和三元组分类的效果。
2. 多模态知识问答
前面介绍过知识图谱问答可以和视觉问答任务相互补充。利用外部知识库增强视觉问答的效果也是近年来比较受关注的研究领域。例如,Out of the Box模型在视觉问答方面把视觉图像、问题文本语义、文本内的知识等多模态信息融合后,根据图片问题信息,从知识库中抽取一个相应的子图,通过融合外部知识库中获取的事实(Facts)来解决视觉问答中所面临的深度语义理解问题,如图11所示。

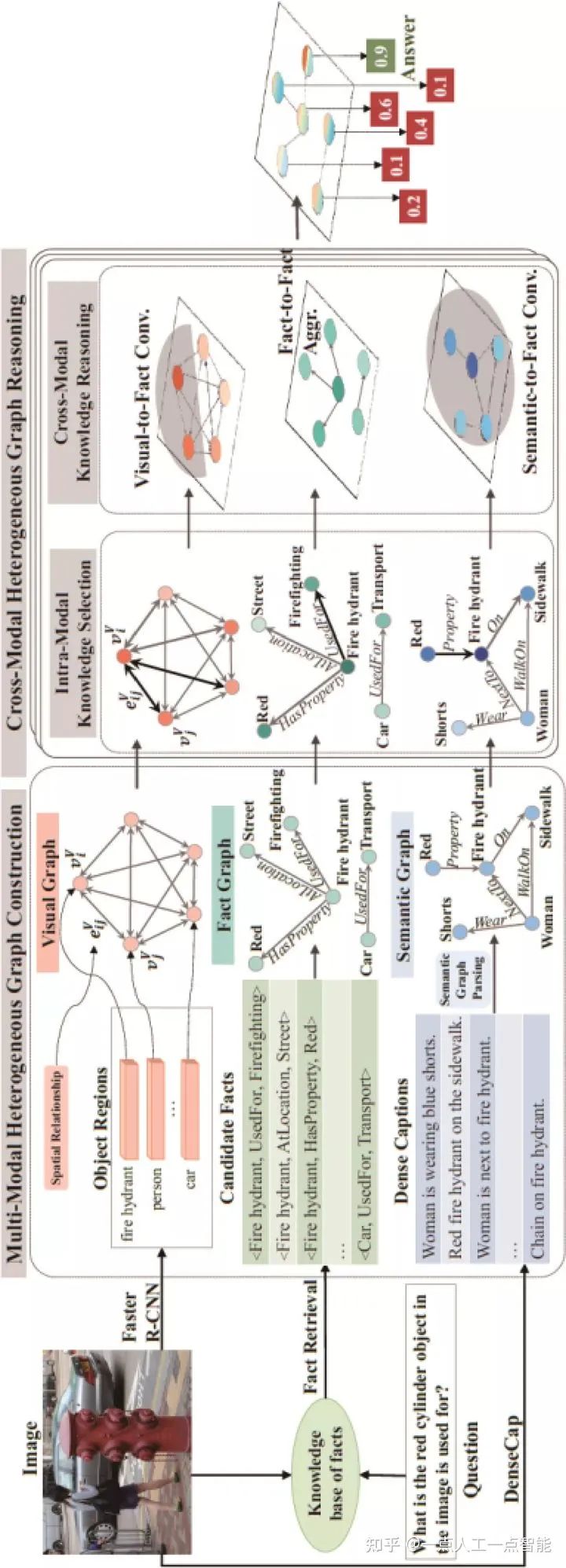
在需要外部知识的视觉问答任务上,前文虽然很好地融合了多模态信息与知识图谱,但最后的判别子图中每个节点都是固定形式的视觉-问题-实体的嵌入表示,这使得模型无法灵活地从不同模态中捕获线索。如图12所示,Mucko模型将图像表示成一个多模态的异构图,其中包含来自不同模态三个层次的信息,分别是从图片构建的视觉图、从问句构建的语义图和从知识图谱构建的事实图,以期望三者互相补充和增强VQA任务的信息。具体来说,视觉图包含了图像中的物体及其位置关系的表示,语义图包含了用于衔接视觉和知识的高层语义信息,事实图则包含图像对应的外部知识。然后对于该三个模态的图,首先进行每个模态内的知识选择,即节点和边的注意力权重,然后通过基于注意力机制的异构图卷积网络方法关联不同模态的信息,从不同图中自适应地收集互补线索并进行汇聚,进行最后的答案预测。
3. 场景图与知识图谱的融合
在视觉任务中,场景图通过将图像编码为抽象的语义元素(即对象及其相互作用),有助于视觉理解和可解释的推理。常识知识图谱则可以用来编码关于世界的事实性知识和抽象概念。场景图与知识图谱怎样融合也是一个比较受关注的研究领域。例如,GB-Net探讨了这两种图结构的统一表示,其中场景图被视为常识知识图谱的图像条件化实例,如图13所示。其中场景图中的每个实体或谓词实例都必须链接到其在常识中的对应实体或谓词类。同时,论文提出了一种异构图推理框架,该框架允许同时利用场景和知识图谱中的丰富结构和常识知识。

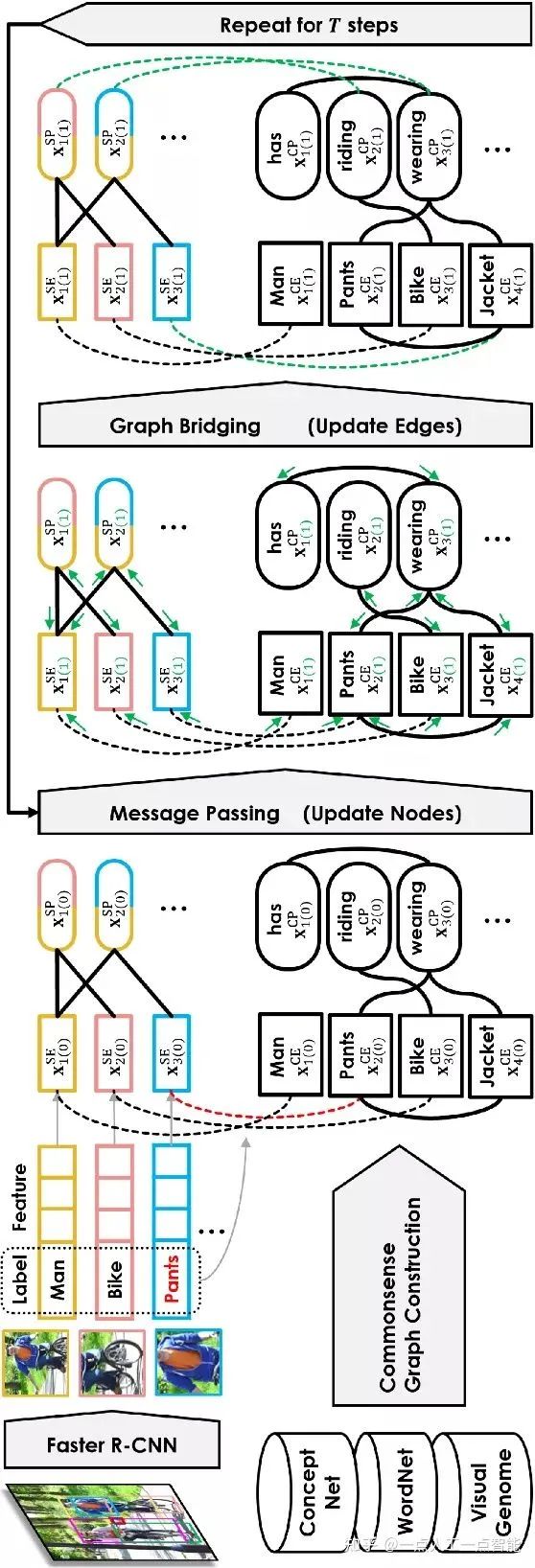
4. 多模态知识图谱推荐
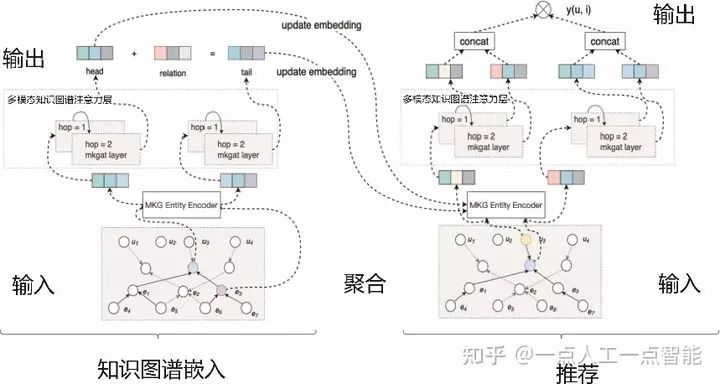
多模态信息当然也可以用来提升推荐系统的效果。对于基于知识图谱的传统推荐算法,虽然利用有价值的外部知识作为辅助信息,但大多忽略了多模态知识图谱中数据类型的多样性。MKGAT多模态知识图谱注意力网络将多模态知识图谱引入推荐系统中,在MMKG上进行信息传播,然后使用所得到的聚合嵌入表示进行推荐,证明了可以成功应用多模态知识图谱提高推荐系统的质量,如图14所示。
05 多模态知识图谱总结
知识图谱是链接数据(Linked Data)的概念,本来就是多模态的,现有很多商用知识图谱都已经通过知识图谱将各种模态的数据进行关联,并提供了多模态语义搜索能力。多模态知识图谱可以发挥不同模态数据中所包含知识的互补性,相互增强、相互补充。一方面,可以利用多模态数据进一步补全知识图谱;另一方面,知识图谱也可以提升多模态任务的效率。多模态知识图谱有很多值得深入研究的方向,例如:多模态关系预测与推理、多模态知识问答、多模态实体对齐与实体链接、多模态推荐计算等。目前,有关多模态知识图谱的研究,不管是技术方法还是图谱数据的构建,都还有很大的发展和创新空间。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!














 570
570











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









