






每天给你送来NLP技术干货!
来自:NLP工作站
作者:刘聪NLP
写在前面
今天给大家带来一篇通过语义匹配进行抽取式摘要的论文「MatchSum」,发表于ACL2020,全名《Extractive Summarization as Text Matching》。
paper:https://arxiv.org/pdf/2004.08795.pdf
github:https://github.com/maszhongming/MatchSum介绍
目前大多数抽取式摘要,大多对原始文档中的句子进行表征,并构建句子间的关系模型,最终选择分数较高的多个句子组成摘要;但是这往往会导致模型更倾向于选择高度概括的句子,而忽略了多个句子之间的耦合。该论文讨论了句子级(Sentence-level)和摘要级(Summary-Level)方法的优势和局限性,其中,句子级方法就是一句一句地进行抽取;摘要级方法就是对若干句进行抽取。并提出了一个新的摘要级框架MatchSum,将抽取式摘要定义为一个语义文本匹配问题,即一个好的摘要应该比不合格的摘要在语义上更类似于原始文档。
句子级和摘要级方法比较
定义一个文档,包含个句子;侯选摘要为,其中,;金标准摘要为;对于和的句子级分数为:
402 Payment Required
其中,为侯选摘要中的句子,为侯选摘要的句子个数,为侯选摘要句子与金标准摘要之间ROUGE分数。摘要级分数为:
其中,是将侯选摘要中所有句子作为一个整体,然后与金标准摘要计算ROUGE分数。
通常认为,最佳摘要(Best-Summary )是指所有候选摘要中摘要级得分最高的摘要。但在真实情况下,往往会出现句子级分数较低但摘要级分数较高的摘要,称之为珍珠摘要(Pearl-Summary)。也就是,存在一个侯选摘要,并且。显然,当一个候选摘要为珍珠摘要时,那么句子级方法就很难提取它。
为了确认珍珠摘要在真实数据集中是否会出现,在6种数据集上进行比较,数据集详情如下表所示,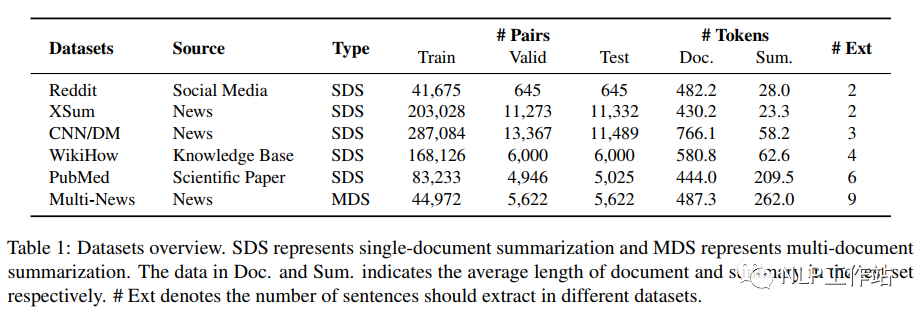 对于每个文档,将所有候选摘要按照句子级分数降序排序,并定义为最佳摘要的排名索引;也就是,如果,意味着最佳摘要是由得分最高的句子组成的;如果是,那么最佳摘要就是珍珠摘要。通过下图可以看出,对于所有的数据集,大多数最佳摘要都不是由得分最高的句子组成的,这说明句子级方法很容易陷入局部优化,错过了更好的候选摘要。
对于每个文档,将所有候选摘要按照句子级分数降序排序,并定义为最佳摘要的排名索引;也就是,如果,意味着最佳摘要是由得分最高的句子组成的;如果是,那么最佳摘要就是珍珠摘要。通过下图可以看出,对于所有的数据集,大多数最佳摘要都不是由得分最高的句子组成的,这说明句子级方法很容易陷入局部优化,错过了更好的候选摘要。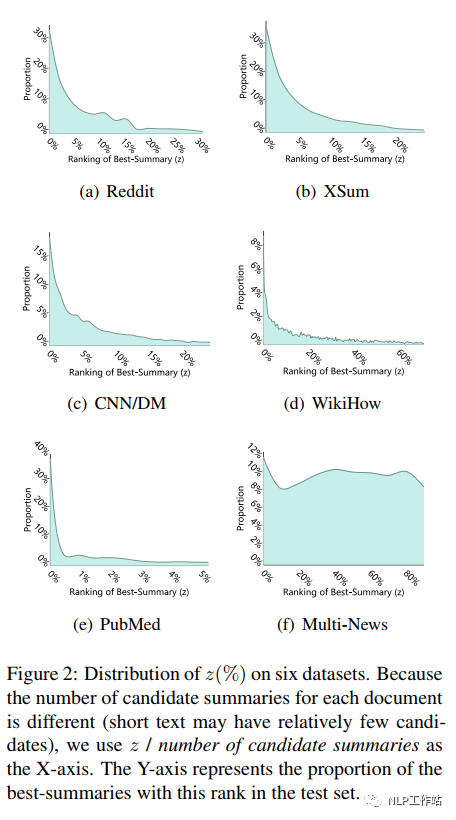 并且从下图中我们可以看出,摘要级方法的性能增益随着数据集的不同而不同。
并且从下图中我们可以看出,摘要级方法的性能增益随着数据集的不同而不同。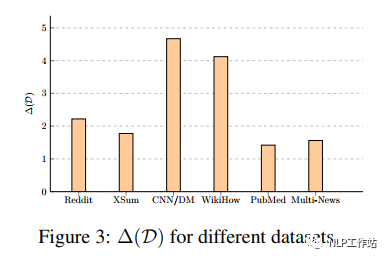
模型结构
为了解决上述问题,该论文提出了一个摘要级框架,可以直接对摘要进行评分和提取,即,将抽取式摘要任务转换为一个语义文本匹配问题,对原始文档和候选摘要(从原始文本中提取)进行语义空间中匹配,找到摘要级的最佳摘要。
Siamese-BERT
构建一个基于BERT模型的暹罗网络,如下图所示,计算原始文档与侯选摘要之间的语义相似度得分,即将原始文档输入到BERT-D模型中,取其[CLS]向量作为文档向量;将侯选摘要输入到BERT-C模型中,取其[CLS]向量作为摘要向量,其中BERT-D与BERT-C参数共享;最后利于余弦相似度计算文档向量与摘要向量之间距离,作为最终得分。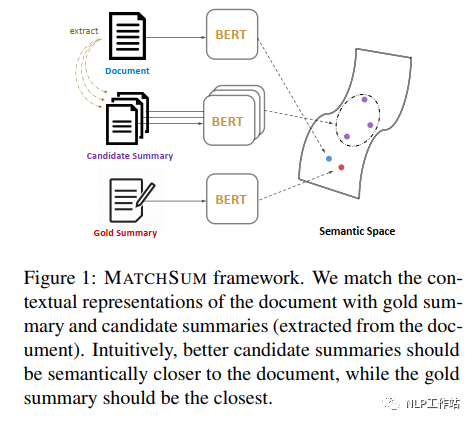 在训练过程中,采用triplet loss更新权重,其中,(1)金标准摘要与原始文档的距离小于侯选摘要与原始文档的距离;
在训练过程中,采用triplet loss更新权重,其中,(1)金标准摘要与原始文档的距离小于侯选摘要与原始文档的距离;
402 Payment Required
(2)对侯选摘要按照ROUGE分数降序排列,排名差距较大的候选摘要对之间的距离也应该较大。
其中,是边际值,是一个超参数,用于区分候选摘要的好坏。最终损失如下:
在推理阶段,从文档D中抽取所有候选摘要C中寻找最佳的摘要。
Candidates Pruning
如果将所有的句子直接排列组合,虽然比较简单,但是存在组合爆炸问题;那么如何确定候选摘要集的大小至关重要。该论文引入内容选择模块对原始文档进行裁剪。该模块为每个句子的重要性进行评分,并删除与当前文档无关的句子,获取删减文档
402 Payment Required
。其中,内容选择模块最终使用不包含trigram blocking策略的BertSum模型。最后对删减文档中所有的句子直接排列组合。实验结果
针对6种摘要数据集进行实验,内容选择模块规格以及句子排列组合规格如下表所示, 从下表中可以发现,在6种数据集上,MatchSum均取得了sota的效果。
从下表中可以发现,在6种数据集上,MatchSum均取得了sota的效果。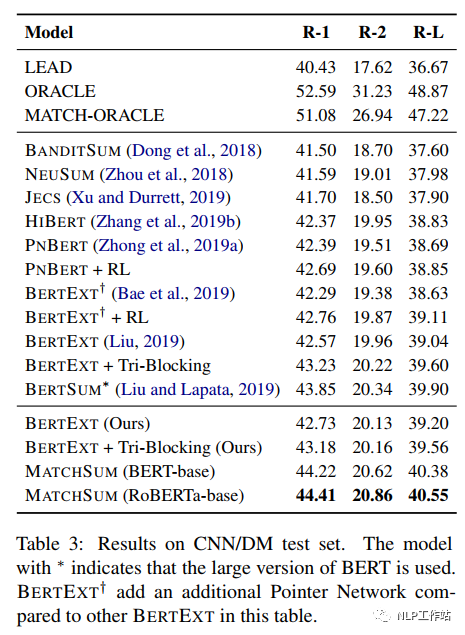 MatchSum模型可以灵活地选择任意数量的句子组成侯选摘要,而其他大多数方法只能提取固定数量的句子。
MatchSum模型可以灵活地选择任意数量的句子组成侯选摘要,而其他大多数方法只能提取固定数量的句子。 虽然Trigram Blocking策略是一种简单而有效的冗余去除方法,但仅限于CNN/DM数据集。
虽然Trigram Blocking策略是一种简单而有效的冗余去除方法,但仅限于CNN/DM数据集。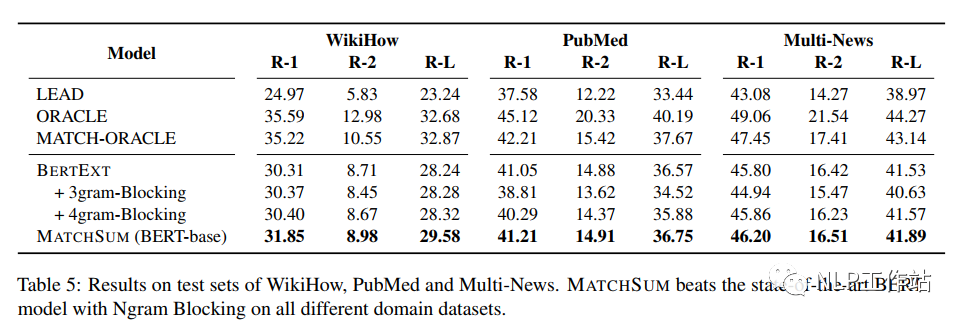
总结
该篇论文将抽取式摘要任务转化为一个语义匹配任务的思路,主要是解决了抽取式摘要中信息冗余的问题,相较于BertSum方法中的Trigram Blocking策略,MatchSum方法灵活性以及泛化性更好。但是也额外增加了很大的计算成本,虽然采用暹罗网络可以避免重复计算原始文档的表征,但是侯选摘要集的表征依然耗费大量的时间成本,在工业落地时会成为一个隐患。
那么是否,可以在不重复表征的情况下,利用语义匹配任务的思路解决该问题,值得思考。
放假ing,但是也要学习。
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套! 后台回复【五件套】
下载二:南大模式识别PPT 后台回复【南大模式识别】投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!














 626
626











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









