






每天给你送来NLP技术干货!
来自:圆圆的算法笔记
作者:Fareise
Prompt是当下NLP领域研究的热点之一,在ACL 2022中有很多prompt相关的工作。最近梳理了5篇ACL 2022中prompt的代表性工作,主要研究点集中在如何通过预训练或迁移学习生成更好的prompt,以及prompt在小样本学习、翻译、图文任务等场景中的应用。下面给大家分别介绍一下这5篇工作,也可以参考我之前更新的prompt相关文章。
1
预训练prompt在小样本场景的应用

论文题目:PPT: Pre-trained Prompt Tuning for Few-shot Learning
下载链接:https://arxiv.org/pdf/2109.04332.pdf
本文主要研究优化prompt tuning在few-shot learning场景下的效果,核心思路是利用预训练实现soft prompt embedding的初始化。如下图,prompt tuning使用可学习的隐空间prompt embedding进行finetune,代替明文的hard prompt,相比hard prompt实现了端到端的学习,并且需要finetune的参数量也非常小,取得了比较好的效果。然而,作者通过实验发现,prompt tuning在few-shot learning上效果较差。作者提出了Pre-trained Pormpt Tuning方法来提升prompt tuning在few-shot learning问题上的效果。
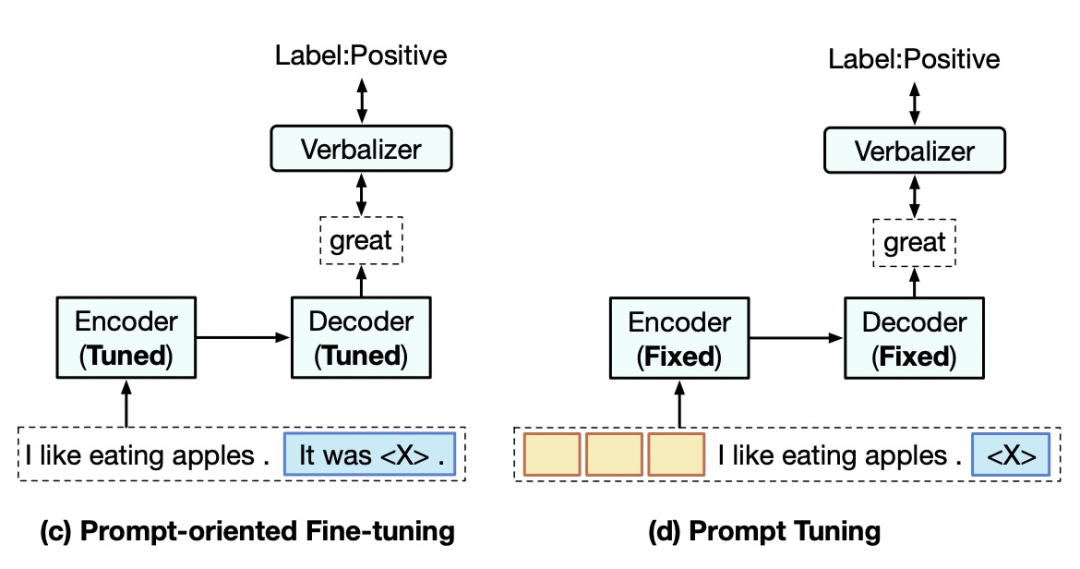
首先,作者对3种prompt tuning的优化策略在few-shot learning问题上分别进行了效果对比,包括hard prompt和soft prompt结合、label到text映射方法选择以及使用真实单词的embedding进行soft prompt的随机初始化。通过对比实验发现,hard+soft prompt结合的方法可以提升效果,但是仍然比finetune效果差。Label到text的映射方法对于效果影响很大,选择能够表达label对应含义的常用单词会带来最好效果。而使用单词embedding进行soft prompt的初始化在大模型上并没有明显的效果提升。
基于以上实验结果,作者提出了Pre-trained Pormpt Tuning解决few-shot learning问题,核心思路是对soft prompt进行预训练,得到一个更好的soft prompt初始化表示。对于每种类型的任务,设计一个和其匹配的预训练任务,得到soft prompt embedding的预训练表示。
本文以sentence-pair classification、multiple-choice classification、single sentence classification三种任务介绍了如何针对每种下游任务设计预训练任务学习soft prompt embedding。例如对于sentence-pair classification,作者设计了如下预训练任务。将2个句子对拼接在一起,如果两个句子来自同一个文档相邻两句话,则label为yes(完全一致);如果两个句子来自同一个文档但距离较远,则label为maybe;其他句子对label为no:
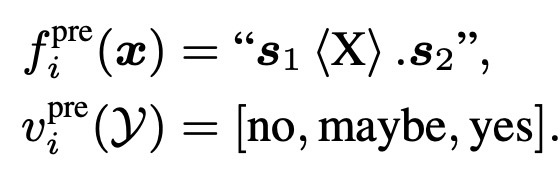
类似的,作者构造了multiple-choice classification和single sentence classification的预训练任务:
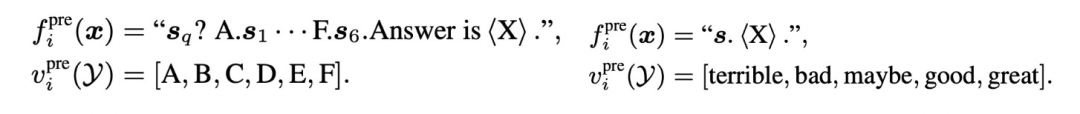
利用上述预训练任务,引入soft prompt embedding进行预训练,在下游任务finetune时,保持和预训练任务相同的形式,使用预训练好的prompt embedding作为初始化。以sentence-pair classification为例,整个过程如下图:

2
利用迁移学习提升prompt效果

论文题目:SPoT: Better Frozen Model Adaptation through Soft Prompt Transfer
下载链接:https://arxiv.org/pdf/2110.07904.pdf
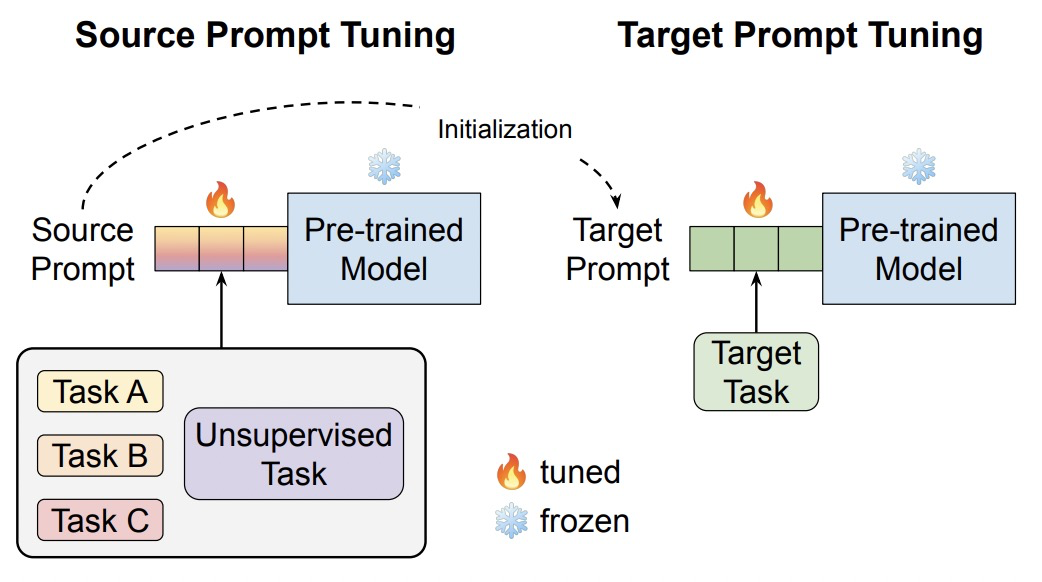
这篇文章同样研究如何使用迁移学习优化soft prompt tuning方法,核心思路是在source task上预训练soft prompt embedding,作为target task上的初始化。。
本文提出的SPoT方法如下图所示,在预训练语言模型和下游prompt tuning中间增加了一步Source Prompt Tuning,可以理解为soft prompt的预训练。预训练阶段会使用无监督任务、多个有监督任务联合学习soft prompt。在得到预训练的soft prompt后,再将其以初始化的方式应用到目标任务中。
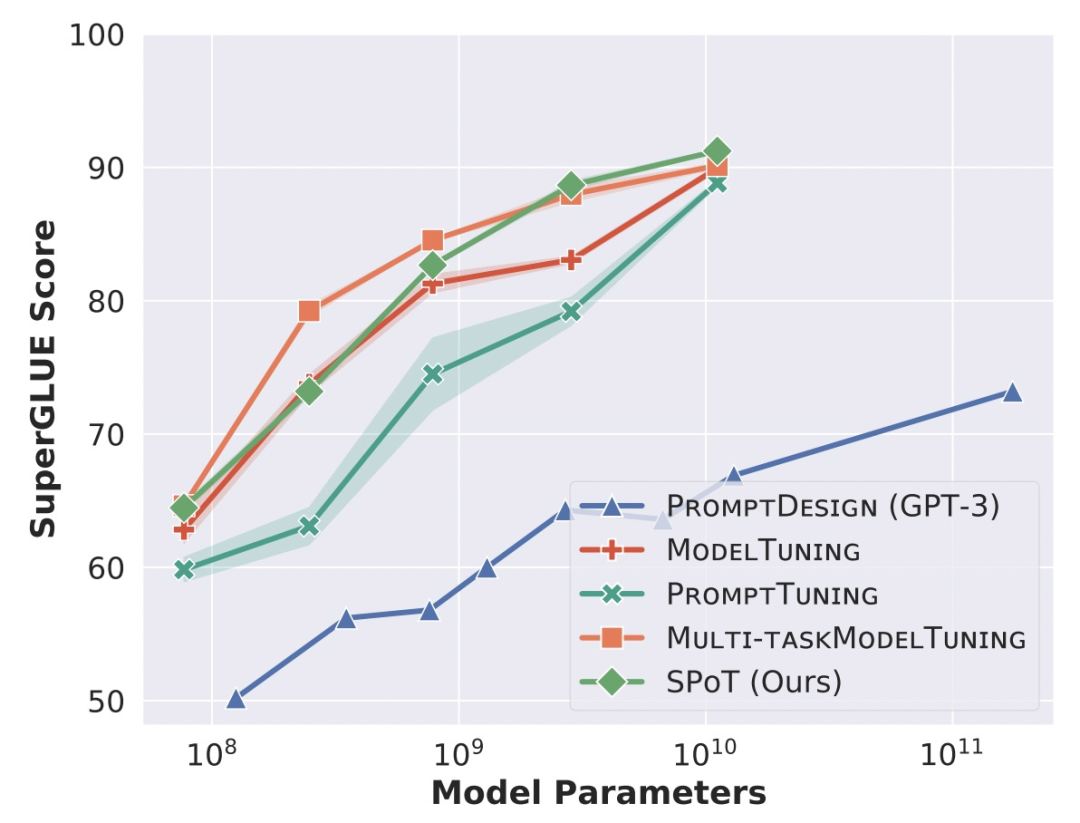
从下图的实验结果可以看出,SPoT Tuning的方法,即使用多个任务进行soft prompt预训练,效果明显好于基础的prompt tuning,甚至可以和模型直接finetune的效果不相上下。而人工设计的prompt方法效果比finetune或soft prompt tuning要差得多。
接下来,作者探索了使用每个task的soft prompt embedding来描述不同task之间的可迁移性。作者通过计算每对task的soft prompt embedding之间的相似度来描述两个任务之间的相关性,绘制成了如下左侧热力图,相似task的soft prompt embedding相似度更高,证明soft prompt embedding可以反映task之间的相关性。
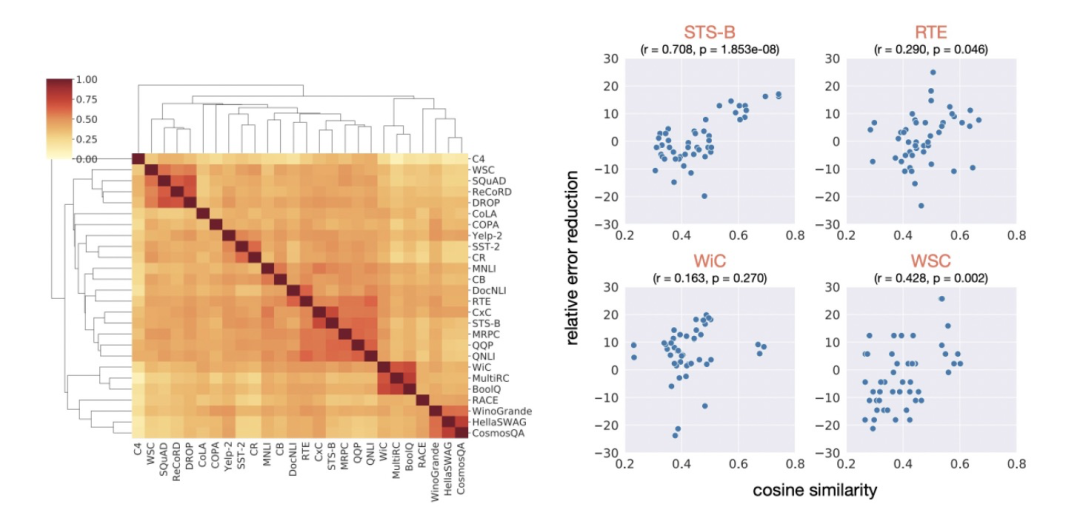
接下来,作者利用这种embedding相似度关系作为选择迁移学习中source task和target task的依据。从上面右侧图(每个点代表一个任务的source prompt,横坐标表示这个source prompt embedding和当前任务embedding相似度,纵轴代表使用这个source prompt进行迁移的效果提升幅度),可以看出,embedding相似度越高的,进行prompt迁移的效果提升越明显,存在一个明显的正相关关系。
3
图文领域小样本下的prompt方法研究

论文题目:A Good Prompt Is Worth Millions of Parameters: Low-resource Prompt-based Learning for Vision-Language Models
下载链接:https://arxiv.org/pdf/2110.08484.pdf
本文针对基于prompt解决小样本场景下的图文任务(包括图文问答、看图说话、类目预测),主要研究了3个问题:prompt设计对zero/few shot的图文任务效果的影响、训练样本足够多的情况下prompt设计对效果的影响、不同预训练任务对zero/few shot的图文任务效果的影响。
下面介绍一下本文提出的FEWVIM小样本图文学习模型架构,整体架构如下图所示,包括模型结构、预训练任务、prompt设计3个方面。
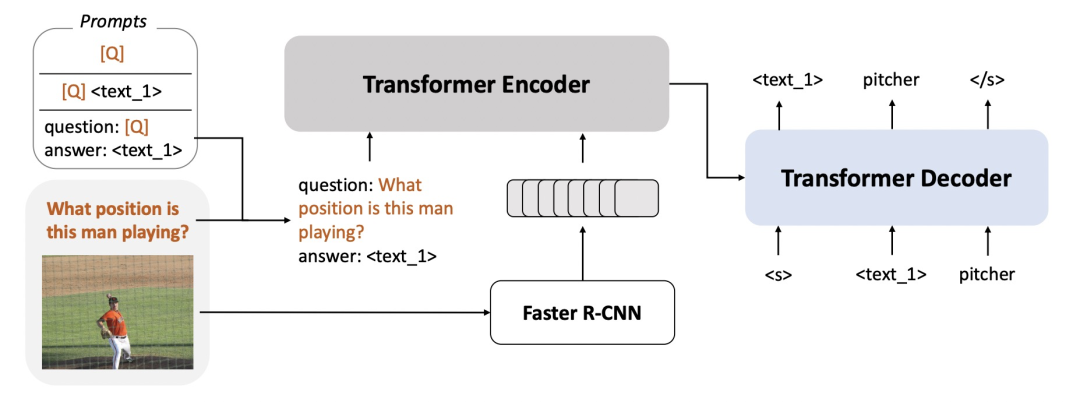
在模型结构方面,FEWVIM整体框架采用了Encoder-Decoder的架构。利用Fast-RCNN进行图像的object detection,并生成每个检测出的目标对应region的表示,这种基于OD的方法是一般的图文任务常见做法之一。这些图像表示和文本表示拼接到一起,输入一个Transformer Encoder中。
在预训练任务方面,预训练的任务包括Prefix LM(将文本分成两个部分,前半部分和图像一起输入到Encoder中,Decoder预测文本的后半部分)以及MLM(随机mask掉15%的文本span,在Decoder中预测被mask掉的span)。
在预训练结束后,基于prompt将预训练图文模型应用到下游任务中。本文针对VQA和Captioning构造的prompt模板如下表所示,将两个任务都看成是序列生成任务。例如VQA的第一个模板,由于问题+<text_1>特殊token组成,输入到Encoder中,在Decoder中预测后续文本作为回答。

在实验结果中发现,prompt设计对zero/few shot效果影响较大,尤其是zero-shot的效果更容易受到prompt设计的影响。在预训练任务方面,MLM任务对VQA任务更好,PrefixLM对Captioning任务更好。这是由于MLM任务和基于prompt的VQA任务类似,都是预测mask span;而PrefixLM和Captioning更相似,都是根据前文进行生成。因此预训练任务和下游任务越相似,效果就越好。
4
小样本翻译问题下的prompt tuning

论文题目:MSP: Multi-Stage Prompting for Making Pre-trained Language Models Better Translators
下载链接:https://arxiv.org/pdf/2110.06609.pdf
本文主要研究如何更好的使用prompt方法解决小样本翻译问题。直接使用预训练语言模型解决翻译的问题存在3个问题。首先,针对翻译任务设计合适的prompt模板是比较困难的。其次,预训练语言模型的预训练任务往往是对句子中的某些部分进行还原,输入和输出是相同语言且语义不相同的。而翻译任务要求输入和输入是两种语言且语义相同。这种预训练任务和翻译任务的差异导致很难直接将预训练语言模型应用到翻译任务中取得较好效果。最后,主流的预训练语言模型如GPT使用了decoder-only的单向结构,可能不是编码源语言句子的最优方法。
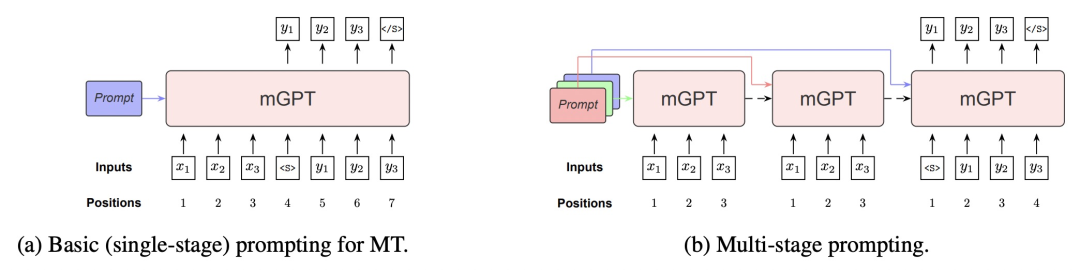
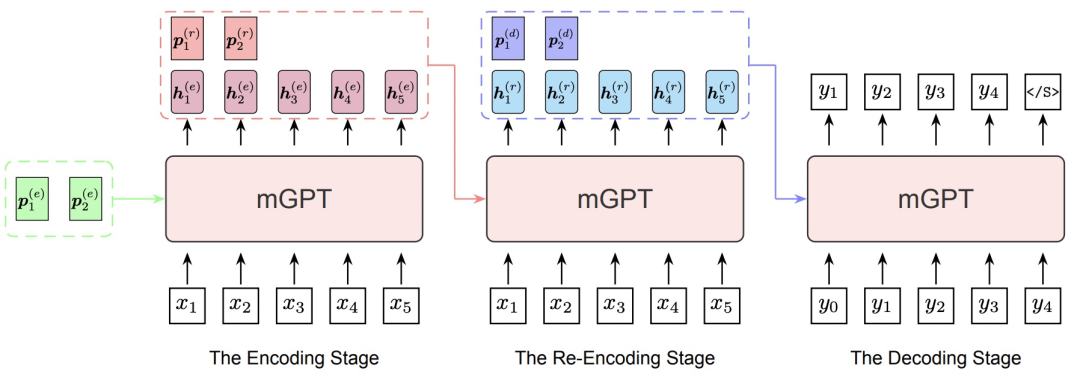
为了解决上述3个问题,本文提出了多阶段的MSP方法。针对第一个问题,文中使用前面工作中提出的continuous prompts而非text prompt,使用可训练的向量,在隐空间构造prompt。针对第二个问题,本文提出了多阶段prompting。多阶段prompting包含3个阶段,每个阶段会使用不同的隐空间prompt。第一个阶段使用预训练语言模型对源语言输入进行编码;第二个阶段利用第一阶段的编码结果,和另一个prompt,对源语言进行再编码;第三阶段利用第二阶段的编码和该阶段对应的prompt进行解码得到预测结果。3个阶段每个阶段都有一个对应的prompt。此外,本文使用GPT模型结构在101种语言的数据集上预训练了mGPT模型,作为整个方法的backbone。
5
如何设计最好的prompt示例顺序

论文题目:Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity
下载链接:https://arxiv.org/pdf/2104.08786.pdf
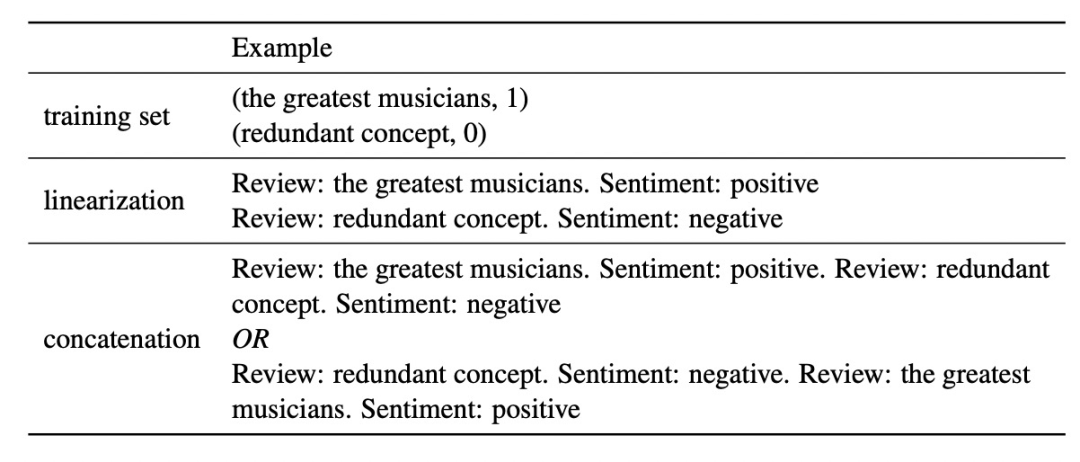
在引入多个prompt示例的时候(如下表的例子),示例不同的排列顺序会对预测效果产生非常大的影响。文中通过实验分析发现,表现不好的prompts示例拼接顺序,往往都是那些根据这个拼接顺序进行预测的时候,label的分布特别不均衡的。比如预测good和bad两种情况,某个顺序拼接prompts示例作为context进行预测时,99%的情况下都预测成good,那么这种顺序的拼接效果就不好。
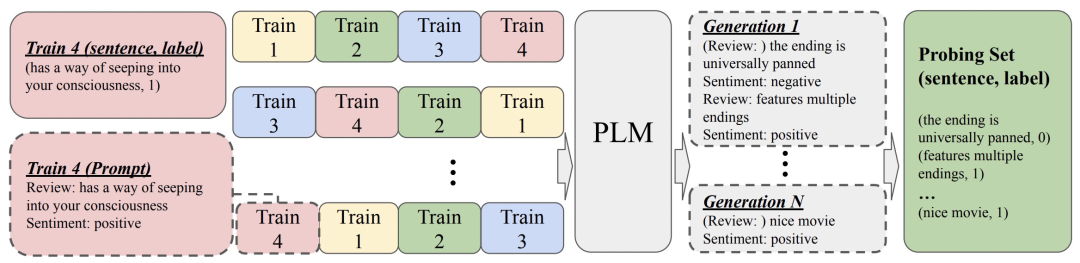
基于这个分析结果,本文采用了如下拼接顺序优选的方法。首先构造所有可能的拼接顺序,输入到预训练语言模型中,用这些不同顺序拼接的句子分别作为context,让预训练语言模型生成后续的句子,这些句子构成了一个probing set。接下来计算每种顺序的拼接context下,产生的label的分布情况,通过熵来评估label的分布是否均匀,选择label分布均匀的拼接顺序。本文提出的方法示意图如下:
6
总结
本文为大家介绍了ACL 2022 Prompt相关的5篇代表工作。从这些工作中可以看出,目前prompt的研究热点是如何通过预训练、迁移学习等方法生成更高质量的隐空间prompt,提升在图文任务、翻译任务等多种场景下的效果。
最近文章
EMNLP 2022 和 COLING 2022,投哪个会议比较好?
一种全新易用的基于Word-Word关系的NER统一模型,刷新了14种数据集并达到新SoTA
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套! 后台回复【五件套】
下载二:南大模式识别PPT 后台回复【南大模式识别】投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!














 571
571











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









