






每天给你送来NLP技术干货!
来自:AI Station
论文标题:
Few-shot Named Entity Recognition with Entity-level Prototypical Network Enhanced by Dispersedly Distributed Prototypes
作者单位:国防科技大学
论文链接:https://arxiv.org/abs/2208.08023
01
—
方法介绍
Few-shot NER的三阶段:Train、Adapt、Recognize,即在source域训练,在target域的support上微调,在target域的query上测试。
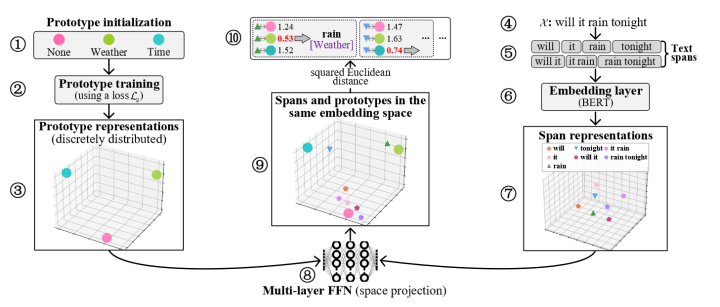
如上图,左边(1-3)表示的是原型的loss1(训练目标为各个原型分散分布),右边(4-7)表示的是span的representation获取,中间(8)是一个多层FFN(为了使得原型表示和span表示最终映射到同一个向量空间),中间(9-10)则是计算原型和span在同一个空间的loss2(为了使得实体span更靠近原型表示)
02
—
和过往工作相比
1、使得Adapt阶段不只是通过对support集中的实体词表示平均得到实体原型表示,而是能够进行finetune(文中提到Ma et al. (2022) claim that the finetuning method is far more effective in using the limited information in support sets.)
2、过往的原型网络的训练方法使得最终的原型表示较接近,本文通过构造loss1(上一段提到的)使得原型表示分散开
03
—
实验结果
这里仅挑选附录部分的FEW-NERD实验结果
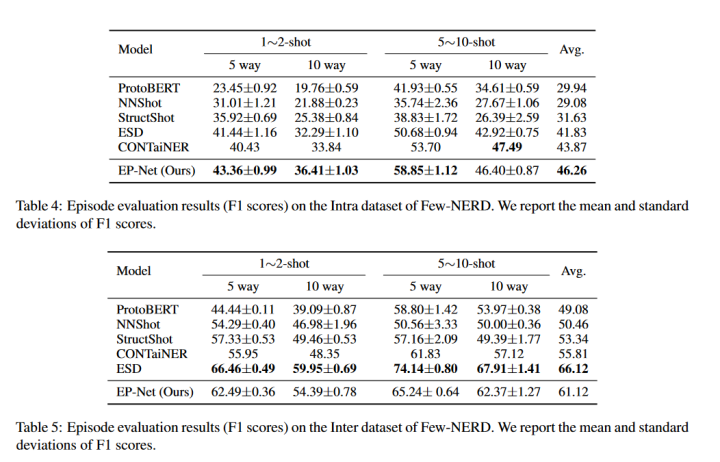
从实验结果来看,在INTRA上效果较好,在INTER上不如ESD。其中INTRA是指source和target之间的实体的粗粒度类型无交集,INTER则在粗粒度上有交集(细粒度上无交集)。(另外,2022年还有一篇SOTA文章Decomposed metalearning for few-shot named entity recognition,这里没有进行对比)
04
—
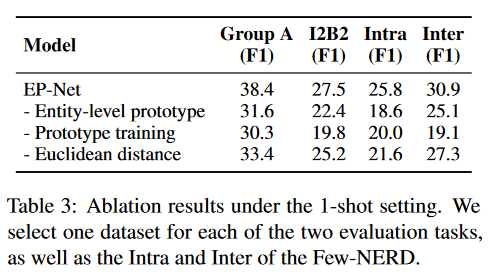
消融实验
1、使用token-level
2、缺少loss1(把原型打散的loss,方法介绍中有说)
3、使用cosine similarity而不是Euclidean distance来衡量span-prototype相似度
📝论文解读投稿,让你的文章被更多不同背景、不同方向的人看到,不被石沉大海,或许还能增加不少引用的呦~ 投稿加下面微信备注“投稿”即可。
最近文章
EMNLP 2022 和 COLING 2022,投哪个会议比较好?
ACL'22 | 快手+中科院提出一种数据增强方法:Text Smoothing
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套! 后台回复【五件套】
下载二:南大模式识别PPT 后台回复【南大模式识别】投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!













 1628
1628











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









