







 该博客介绍了一种创新的SpanProto模型,用于解决少量NER任务,采用两阶段方法进行跨度提取和提及分类。模型首先通过转换标签为边界矩阵聚焦边界信息,然后利用原型学习捕捉实体语义。在每个episode中,模型更新同一类型实体的原型,并用分类损失函数训练。对于误报,模型将其视为未知类型的特殊实体,避免影响现有原型。
该博客介绍了一种创新的SpanProto模型,用于解决少量NER任务,采用两阶段方法进行跨度提取和提及分类。模型首先通过转换标签为边界矩阵聚焦边界信息,然后利用原型学习捕捉实体语义。在每个episode中,模型更新同一类型实体的原型,并用分类损失函数训练。对于误报,模型将其视为未知类型的特殊实体,避免影响现有原型。
Introduction
我们提出了一个开创性的基于跨度的原型网络(SpanProto),它通过一个两阶段的方法来解决少量的NER问题,包括跨度提取和提及分类。在跨度提取阶段,我们将顺序标签转化为全局边界矩阵,使模型能够专注于明确的边界信息。对于提及分类,我们利用原型学习来捕捉每个标记的跨度的语义表示,并使模型更好地适应小说类实体。
模型分为两个部分,通过表填充方式解决mention识别问题,使用原型网络解决mention分类问题。
Model
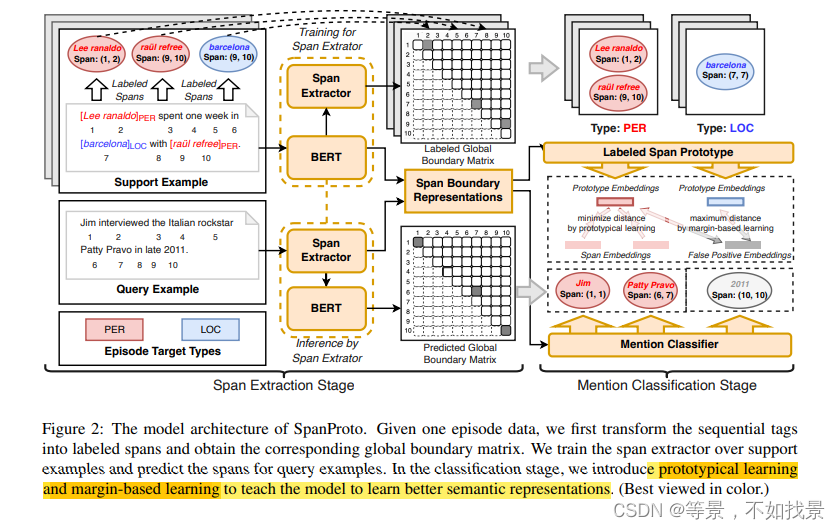
第一部分:mention识别是通过pointer network解决的。损失函数时二分类交叉熵损失函数。
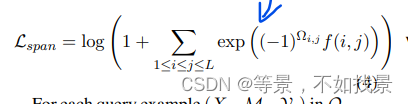
第二部分:原型学习实现关系分类。在每一个episode中,通过平均化相同实体类型的span的表示得到对应class的原型。损失函数是分类损失函数。
当识别出的flase positive类型,则将the false positive can be viewed as a special entity mention, which has no type to be assigned in Ttrain, but could be an entity in other
episode data. In other words, the real type of this
false positive is unknown. Thus, a natural idea is
that we can keep it away from all current prototypes
in the semantic space. S




















 1002
1002

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











