






来自:知识工场
进NLP群—>加入NLP交流群
前 言
比喻在创造性表述中扮演着至关重要的角色,可以支持更类人的对话系统,帮助故事、诗歌生成等下游任务。合适的评估指标就像是指引比喻生成(Simile Generation, SG)研究的明灯,可以帮助模型之间进行更高效的比较。
然而,现有的评估指标(例如BLEU、Rouge)存在一系列的局限性:
(1)明喻组件较其他上下文应该得到更多关注;
(2)明喻任务是个开放式(open-ended)的生成任务,对于同一个句子可以有多种合理的改写结果;
(3)创新性的生成任务(例如故事、对话生成)往往对青睐的结果有不同维度的评价指标。
因此,构建一个全面的、高效的、可靠的评估系统对于比喻改写任务非常重要。本文介绍了复旦大学知识工场实验室的最新工作《HAUSER: Towards Holistic and Automatic Evaluation of Simile Generation》,该工作已经被ACL2023 录用。此工作建立了HAUSER,一个全面且自动化的比喻生成(Simile Generation, SG)任务评估系统。该工作基于语言学理论,从三个维度设计五个标准,以期全面评估SG任务;基于大规模知识库/语料集、预训练模型,将每个评估标准量化为自动化指标;进行大量的实验,验证提出的自动化指标能较传统自动化指标更准确地反映SG模型的表现效果。

Paper: https://arxiv.org/abs/2306.07554
Datasets and Code:https://github.com/Abbey4799/HAUSER
研究背景
比喻在人类日常表达中扮演着重要的角色,使平铺直叙的句子富有想象力和易于理解。例如,罗伯特·伯恩斯(Robert Burns)写道:“我的爱人就像一朵红红的玫瑰(My Luve is like a red, red rose.)”,用比喻的方式描绘了心爱之人的美丽。在这个比喻中,本体“爱人”(Topic)通过隐含的属性(Property)“美丽”和谓词(Event)“是”与喻体(Rose)“红玫瑰”进行了比较。在这里,本体、属性、谓词和喻体是四个主要的明喻组件(Simile Component)。作为一种重要的修辞手法,比喻在文学作品和对话中被广泛使用。

图1:明喻通过共同属性将两个概念联系起来的示例
比喻生成(Simile Generation, SG)是自然语言处理中的关键任务,旨在将平铺直叙的句子改写成生动的比喻句。在图2中,原句为“He yelps and howls.”,通过插入短语“like a wolf”,句子被转化为生动形象的比喻句“He yelps and howls like a wolf.”。改写比喻的能力可以帮助各种下游任务,例如在故事或诗歌生成任务中使生成的内容更富有想象力,在对话生成任务中使生成的回应更加人性化。

图2:语言模型生成的明喻没有人类书写的明喻生动通顺示例
自动评估在明喻改写任务(Simile Generation, SG)中至关重要,因为它能够实现对模型的高效、系统和可扩展的比较。然而,现有研究对于有效的SG评估缺乏关注。广泛采用的传统指标(例如BLEU)在SG评估中存在一些局限性:
(1)在SG评估过程中,明喻组件(Simile Component)应该比其他单词更受关注(例如,图1中的“He”和“Wolf”),然而现有的指标没有考虑到这些关键组成部分。
(2)SG任务是开放性的,同一个句子可以改写为多个合理的生成结果(例如,图1中的大叫的人可以与“狼”、“水牛”或“老虎”进行比较)。因此,基于和少量正确答案的重叠词数(Word Overlap)的传统度量指标不足以准确衡量生成明喻的整体质量。如图2所示,常用的BLEU指标认为第二个候选结果具有最高质量,因为它与唯一的参考标准有更多的重叠单词,而人类认为第一个候选结果最合理。
(3)现有的度量指标不足以提供细致全面的SG评估。这是因为创造性生成任务对于期望生成结果有不同的标准,例如故事生成需要新颖性和复杂性,对话生成需要逻辑一致性等。
然而,建立一个全面、高效和可靠的SG评估系统并非易事,有三个主要挑战:
(1)应采用什么标准来全面、非冗余地评估SG任务?
(2)创造性生成任务的人工评估既耗时又主观模糊,如何将每个标准量化为指标,从而实现高效、客观的SG评估?
(3)所提出的度量指标是否真的可以引导SG模型在实际应用中的效果改进?
RQ1: Criteria Design
为解答第一个研究问题,如表1,基于语言学理论我们从三个维度设计了五个标准:
(1)相关性(Relevance) :本体和喻体之间的相关性,因为比喻的基础是通过比较它们共享的属性来在二者之间建立联系。
(2)逻辑一致性(Logical Consistency) :原始句和生成的明喻句之间的逻辑一致性,因为比喻的目标是在不改变语义的情况下对原始句子进行润色。
(3)情感一致性 (Sentiment Consistency) :原始句和生成的明喻句之间的情感一致性,因为比喻往往传达了特定的情感极性。
(4,5)创造性(Creativity) 和语义丰富度(Informativeness) :因为新颖或语义丰富的比喻更具文学色彩。
总体而言,这5个标准可以归类为三个维度:质量(同时考虑相关性、逻辑和情感一致性)、创造性、语义丰富度。
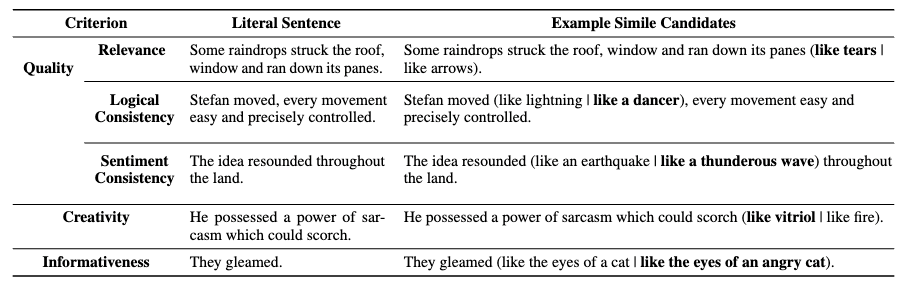
表1:评估标准示例。基于语言学理论,我们从三个维度设计了五个标准
RQ2: Criteria Formulation
为实现高效、客观的SG评估,我们将每个标准量化为自动指标。整体流程如图3:
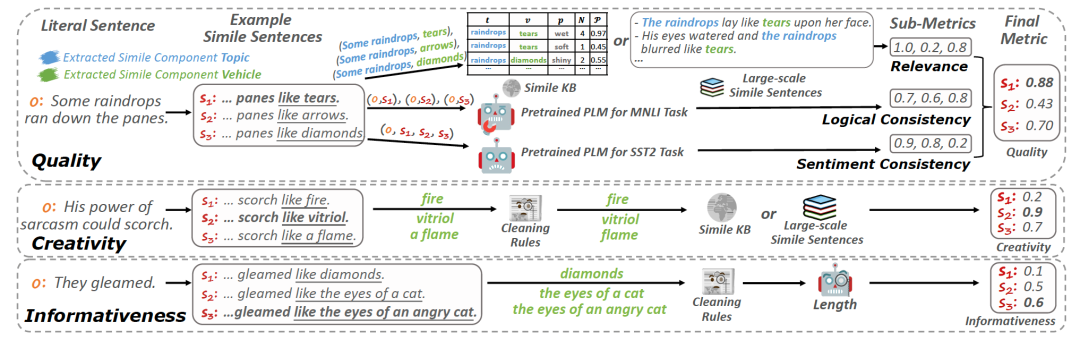
图3:HAUSER自动评估指标设计框架
质量(Quality)
相关性(Relevance)
对于相关性得分,如果一个明喻的组件相关,它们往往在明喻句中共现且具有共享的属性。因此,计算相关性得分需要大规模的明喻句作为参考、以及关于明喻组件的属性知识。对于一个明喻句,相关性得分定义如下:
其中,从明喻句s中提取出了 个本体-喻体对,每对表示为 。 是包含明喻对 的明喻句集合,每个明喻句表示为e。 是在明喻句e的上下文中,明喻对 共享属性的概率。
获取频率信息 和属性知识 的一种有效方法是利用大规模的概率比喻知识库MAPS-KB(He等,2022),该知识库包含以(topic, property, vehicle)形式的数百万个比喻三元组,并设计频率以及两个概率度量指标来建模每个三元组。具体而言,概率度量指标合理性(Plausibility)代表本体、喻体共享属性的概率。相关性得分r可以按如下计算:
需要注意的是,该评估指标与MAPS-KB没有直接关联,因为可以通过参考大量的比喻句子获取频率信息,并且可以通过其他知识库获取属性知识。更多方法超出了本文的范围。不过,我们额外提供了一种近似计算相关性得分的方法。如果我们假设在每个句子中本体-喻体对共享属性的概率为1,那么相关性得分可以近似计算为:
其中, 代表在大规模语料库中包含明喻对 的明喻句数量。我们在后续实验讨论了语料规模对指标有效性的影响。
逻辑一致性(Logical Consistency)
对于一个生成的明喻,我们将<原句(1),明喻(s)>句子对输入到现有的已经预训练好的MNLI模型中。该模型确定句子对之间的关系是蕴含(entailment)、无关(neutral)还是矛盾(contradiction)。逻辑一致性分数 定义如下:
其中 表示MNLI模型预测句子对 的关系为矛盾(表示为 )的概率。
情感一致性(
Sentiment Consistency
)
质量高的明喻句往往强化了原有句子的情感极性。因此,我们首先利用在GLUE SST-2数据集上微调的模型对每个明喻进行分类,判断其是积极的还是消极的。然后,情感一致性分数 定义如下:
其中 是模型预测的原句的情感极性(积极或消极)。 和 分别表示模型预测明喻 和原句 的情感极性为 的概率。
加权组合(Combination)
由于SG任务的目标是改善原有文本的质量,无法比较基于不同文本生成的明喻的质量。因此,对于每个原始文本,使用明喻候选项之间的归一化得分。明喻的归一化相关性得分 定义如下:
其取值范围为0到1。然后,以相同的方式获得每个明喻的归一化逻辑一致性得分和情感一致性得分。最后,明喻的质量定义为以下三个部分的加权组合:
其中α、β和γ是超参数。
创造性(Creativity)
与其他开放式生成任务不同,明喻组件使我们能够自动评估创造力。根据语言学家,比喻句的创造力取决于喻体。如果本体-喻体对在语料库中频繁共现,或者如果许多本体与其喻体进行比较,那么比喻的创新性可能较低。因此,在设计创造力评估指标时,我们采用大规模语料库作为参考。明喻s的创造力得分计算如下:
对数变换旨在减小极端值的影响。
语义丰富度(Informativeness)
一个包含更多词语的喻体,其内容会更丰富。因此,对于给定的明喻s,我们采用从中提取的喻体的平均长度作为语义丰富度得分,定义为:
其中从明喻 中提取出 个喻体。
RQ3: Metrics Effectiveness
在本节中,我们设计了一系列实验来验证我们的自动评估指标的有效性。以质量得分(Quality)为例,我们首先计算了我们的指标和传统指标与人类打分的相关系数。根据表2以及图4可见,我们的指标较传统指标提出的自动化指标能更准确地反映SG模型的表现效果。
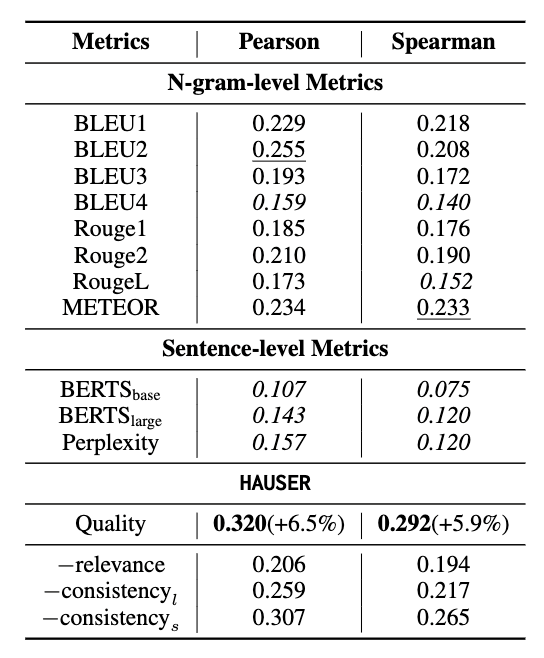
表2:自动评估指标与人工评分之间的相关性。p值大于0.05的所有测量结果都以斜体显示。最佳结果用粗体数字标记。排名第二的结果用“__”标记。"−"表示删除子指标。

图4:自动评估指标与人工评分之间的相关性的可视化结果
接着,我们对比了自动评估指标的排序与人工排序结果。根据表3,我们的指标可以得到更准确的排序结果。
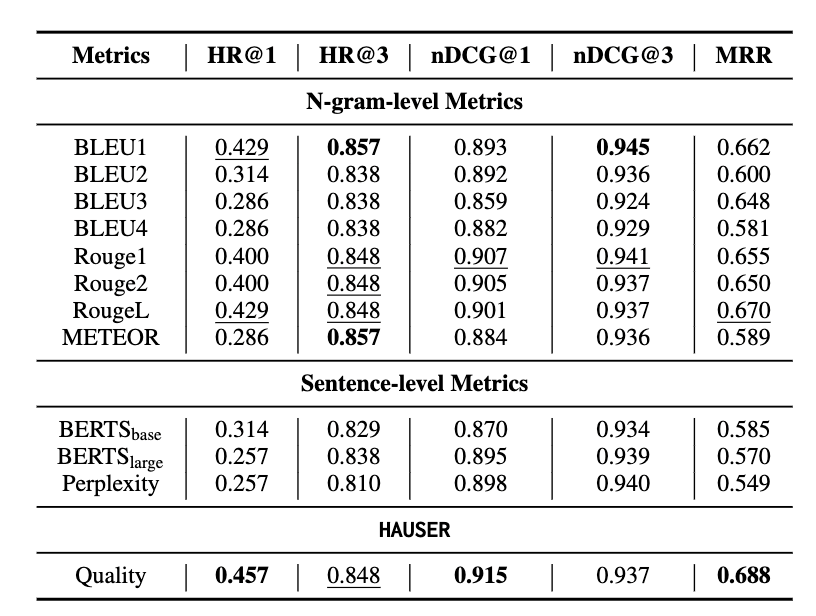
表3:自动评估指标排序结果对比
我们还计算了指标之间的相关程度。根据表4,我们设计的各指标彼此之间没有显著相关性,证明我们的指标不是冗余的。
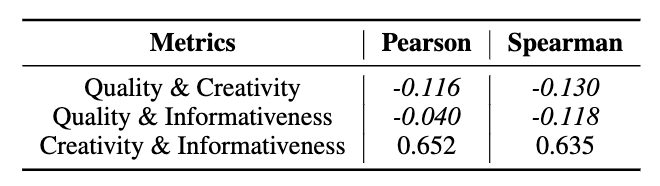
表4:自动评估指标之间的成对相关性
特别地,我们进行了案例分析,证明我们设计的自动评估指标对于各种方法都是有效的。根据表5,经过我们的指标排名后,不同方法生成的候选项与人工排名之间的相关性更高,从而证明了我们指标的有效性。
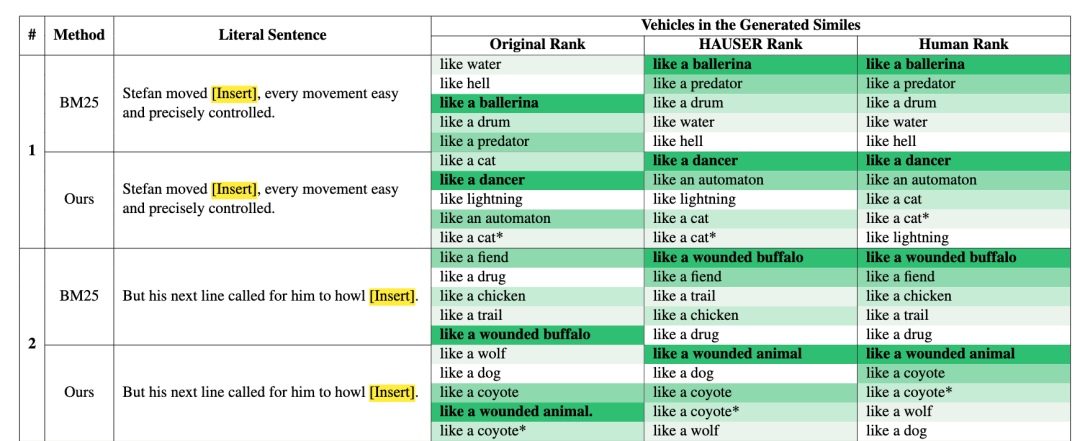
表5:部分案例分析的结果。越深的绿色代表人类标注的更高排名
总 结
在这项工作中,我们系统地研究了比喻生成(Simile Generation, SG)任务的评估。我们建立了一个全面和自动化的SG任务评估系统HAUSER(a Holistic and AUtomatic evaluation system for Simile gEneRation task),包括来自三个维度的五个评判标准,并为每个标准设计自动化评估指标。大量实验证实了我们的指标的有效性。

论文&文稿作者:

责任编辑:王文

进NLP群—>加入NLP交流群


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









