






深度学习自然语言处理 分享
整理:pp
 摘要:语言代理通过对基础模型进行推理,展示了自主决策能力。最近,人们开始利用多步骤推理和行动轨迹作为训练数据,努力训练语言代理以提高其性能。然而,收集这些轨迹仍然需要大量人力,要么需要人工注释,要么需要实现各种提示框架。在这项工作中,我们提出了 AT,这是一个能以 ReAct 风格实现代理轨迹自主注释的框架。其核心角色是一个 ActRe 提示代理,负责解释任意行动的原因。在随机抽样外部行动时,ReAct 风格的代理可以向 ActRe 代理查询该行动,以获得其文本理由。然后,通过将 ActRe 的后验推理预置到采样行动中,合成新的轨迹。这样,ReAct 式代理就会为失败的任务执行多个轨迹,并选择成功的轨迹作为失败轨迹的补充,进行对比性自我训练。通过二值化奖励的策略梯度法,利用积累的轨迹进行对比性自我训练,可促进多轮语言代理自我完善的闭环。我们使用开源的 Mistral-7B-Instruct-v0.2 进行了 QLoRA 微调实验。在 AlfWorld 中,使用 AT 训练的代理一次成功率为 96%,4 次迭代成功率为 100%。在 WebShop 中,AT 代理的单次成功率达到了人类的平均水平,经过 4 轮迭代改进后,其成功率接近人类专家。AT 代理的性能明显优于现有技术,包括使用 GPT-4 的提示、高级代理框架和完全微调的 LLM。
摘要:语言代理通过对基础模型进行推理,展示了自主决策能力。最近,人们开始利用多步骤推理和行动轨迹作为训练数据,努力训练语言代理以提高其性能。然而,收集这些轨迹仍然需要大量人力,要么需要人工注释,要么需要实现各种提示框架。在这项工作中,我们提出了 AT,这是一个能以 ReAct 风格实现代理轨迹自主注释的框架。其核心角色是一个 ActRe 提示代理,负责解释任意行动的原因。在随机抽样外部行动时,ReAct 风格的代理可以向 ActRe 代理查询该行动,以获得其文本理由。然后,通过将 ActRe 的后验推理预置到采样行动中,合成新的轨迹。这样,ReAct 式代理就会为失败的任务执行多个轨迹,并选择成功的轨迹作为失败轨迹的补充,进行对比性自我训练。通过二值化奖励的策略梯度法,利用积累的轨迹进行对比性自我训练,可促进多轮语言代理自我完善的闭环。我们使用开源的 Mistral-7B-Instruct-v0.2 进行了 QLoRA 微调实验。在 AlfWorld 中,使用 AT 训练的代理一次成功率为 96%,4 次迭代成功率为 100%。在 WebShop 中,AT 代理的单次成功率达到了人类的平均水平,经过 4 轮迭代改进后,其成功率接近人类专家。AT 代理的性能明显优于现有技术,包括使用 GPT-4 的提示、高级代理框架和完全微调的 LLM。
https://arxiv.org/abs/2403.14589
Q1: 这篇论文试图解决什么问题?
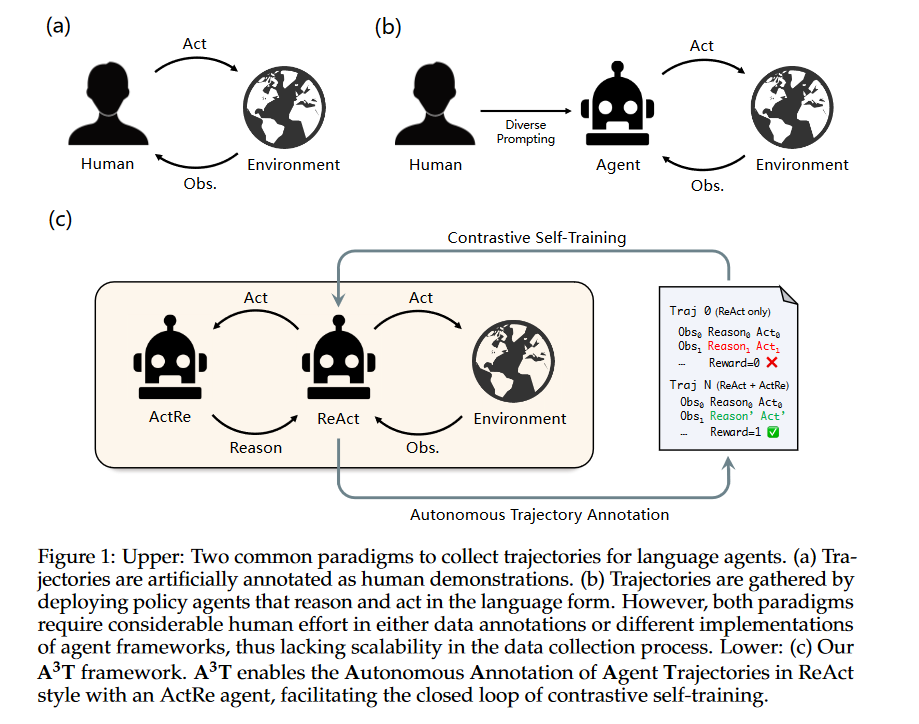 A:这篇论文提出了一个名为A3T(Autonomous Annotation of Agent Trajectories)的框架,旨在解决以下问题:
A:这篇论文提出了一个名为A3T(Autonomous Annotation of Agent Trajectories)的框架,旨在解决以下问题:
自动化轨迹注释:当前,收集用于训练语言代理的多步推理和行动轨迹数据需要大量的人工努力,无论是通过人工注释还是通过实施多种提示框架。A3T框架通过引入一个名为ActRe的提示代理来自动化这一过程,该代理能够解释任意行动的原因。
对比自训练:A3T框架利用ActRe代理和环境反馈来自主合成轨迹,并通过政策梯度方法和二值化奖励来进行对比自训练,以此提高任务成功率。
闭环自我改进:A3T框架通过自动化注释和对比自训练形成了一个闭环,使得语言代理能够通过多轮迭代不断自我改进。
减少人工监督:通过A3T框架,代理可以在最小程度的人工监督下自主收集高质量的轨迹数据,这些数据附带文本注释,适合进一步训练。
提高语言代理的自主性和性能:A3T框架的目标是提高语言代理在执行任务时的自主决策能力,并通过自我训练提高其在各种决策场景中的表现。
总的来说,A3T框架试图通过自动化轨迹注释和对比自训练,减少人工努力,提高语言代理的自主性和任务执行性能。
Q2: 有哪些相关研究?
A:这篇论文中提到了以下相关研究:
ReAct:ReAct是一种结合了推理和行动的语言模型,它通过人工注释的轨迹数据进行训练,以提高其在特定任务中的性能。
LLMs(Large Language Models):大型语言模型如GPT-4、GPT-3.5等,它们在多种决策场景中通过与环境的自主交互展示了出色的性能。
多步推理和行动轨迹:使用描述语言代理整个任务解决过程的多步轨迹作为训练数据,这些轨迹包括环境观察、内部推理文本和外部行动。
专家演示(Expert Demonstrations):利用专家演示来收集轨迹数据,但这种方法需要大量的人工劳动,限制了方法的可扩展性。
不同提示框架(Diverse Prompting Frameworks):通过实施不同的代理框架来收集多样化的轨迹数据,但这些框架的探索覆盖仍然受到提示技术全集的上界限制。
统一数据格式:提出了统一的数据格式,通过阐明代理轨迹中的子模块来简化数据收集过程。
探索性代理框架(Exploration-based Agent Frameworks):例如,Song等人提出的框架,它通过探索来收集轨迹数据,但这些轨迹缺乏能够引导语言代理更好行为的文本理由。
QLoRA(Quantized Language Model Fine-tuning):一种用于量化大型语言模型的微调方法,用于在实验中对Mistral-7B-Instruct-v0.2进行微调。
政策梯度方法(Policy Gradient Methods):使用政策梯度方法和二值化奖励来进行对比自训练,以提高语言代理的任务成功率。
对比学习(Contrastive Learning):在代理训练中使用对比学习来区分成功和失败的轨迹,以提高代理的性能。
这些相关研究为A3T框架的提出提供了背景和基础,A3T框架在此基础上通过自动化注释和对比自训练来改进语言代理的训练过程。
Q3: 论文如何解决这个问题?
 A:论文通过提出一个名为A3T的框架来解决上述问题,具体方法如下:
A:论文通过提出一个名为A3T的框架来解决上述问题,具体方法如下:
ActRe提示代理:A3T框架的核心是一个名为ActRe的提示代理,它能够解释任意外部行动的原因。当ReAct风格的代理随机采样一个外部行动时,它可以查询ActRe代理以获取该行动的文本理由。
自主轨迹注释:通过ActRe代理,ReAct风格的代理可以为每个失败的任务合成新的轨迹,通过将ActRe提供的后续推理预先添加到采样的行动中来实现。
对比自训练:ReAct风格的代理执行多个轨迹,选择成功的轨迹来补充其失败的轨迹,进行对比自训练。这一过程通过政策梯度方法和二值化奖励来实现,从而促进语言代理的闭环自我改进。
 4. 政策梯度方法:使用政策梯度方法来优化代理的参数,通过比较成功和失败轨迹的奖励来调整代理的行为,以此来提高代理在任务中的成功率。
4. 政策梯度方法:使用政策梯度方法来优化代理的参数,通过比较成功和失败轨迹的奖励来调整代理的行为,以此来提高代理在任务中的成功率。
迭代训练过程:通过多轮迭代的数据收集和代理训练,A3T框架不断积累和优化轨迹数据集,以此提高代理的性能。
实验验证:在文本具身环境AlfWorld和在线购物环境WebShop中进行实验,使用QLoRA对Mistral-7B-Instruct-v0.2进行微调,验证了A3T框架的有效性。
通过这些方法,A3T框架能够在最小程度的人工监督下自主收集高质量的轨迹数据,并利用这些数据通过对比自训练来提高语言代理的性能。
Q4: 论文做了哪些实验?
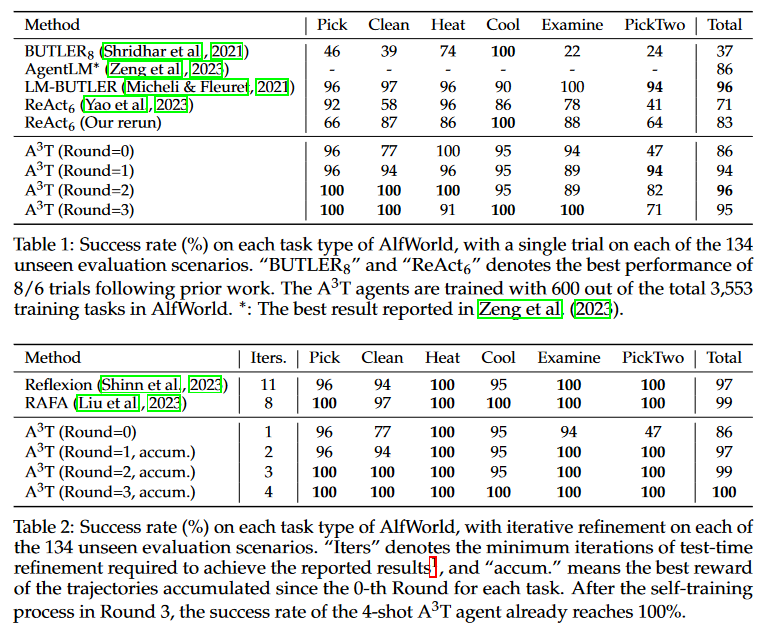
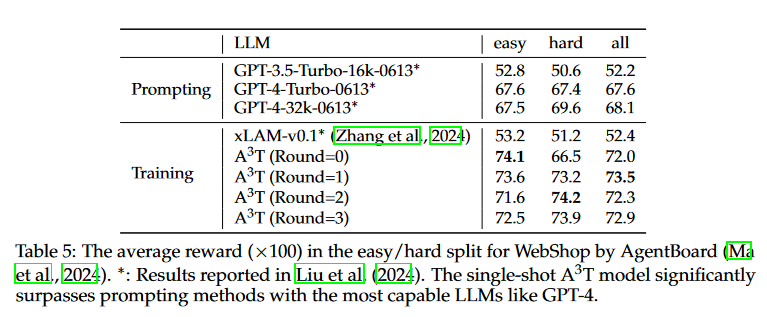
A:论文中进行了以下实验来验证A3T框架的有效性:
AlfWorld实验:
使用AlfWorld作为文本具身环境,代理需要通过推理和行动来完成多步骤任务。
实验涵盖了6种任务类型,使用了660个任务中的600个进行训练,60个进行验证。
与多个强基线模型进行比较,包括BUTLER、LM-BUTLER、AgentLM等。
进行了4轮轨迹收集和代理训练,初始轮使用ReAct提示进行引导。
报告了在AlfWorld上的单次尝试和迭代精炼设置下的成功率。
WebShop实验:
使用WebShop作为在线购物环境,代理需要根据给定的指令购买最合适的商品。
实验使用了11,587个任务中的2,300个进行训练和验证。
与ReAct提示和WebGUM等基线模型进行比较。
同样进行了4轮轨迹收集和代理训练。
报告了在WebShop上的单次尝试和迭代精炼设置下的平均奖励和成功率。
对比自训练的效果:
在AlfWorld和WebShop环境中,展示了经过多轮迭代后,代理在任务中的成功率和轨迹质量的提升。
展示了使用不同奖励阈值进行训练的效果,以及使用政策梯度方法与二值化奖励的优势。
消融研究:
对比了使用不同奖励配置的A3T框架的效果,包括仅使用成功轨迹进行监督微调的情况。
使用gpt-3.5-turbo-1106进行微调,与使用Mistral-7B-Instruct-v0.2的A3T框架进行比较。
案例研究:
展示了在WebShop环境中,A3T框架如何通过ActRe辅助合成轨迹,并与未辅助的失败轨迹进行比较。
这些实验结果表明,A3T框架能够有效地提高语言代理在多步骤决策任务中的性能,并且在多次迭代后能够显著缩小与人类专家性能的差距。
Q5: 有什么可以进一步探索的点?
A:论文中提出的A3T框架虽然取得了一定的成果,但仍有一些方向可以进行进一步探索:
高级策略和奖励设计:探索更高级的策略和奖励设计,可能会进一步提高代理的学习效率和任务性能。例如,可以考虑使用强化学习中的先进算法,如Actor-Critic方法或变分自编码器(VAE)来改进代理的行为策略。
多模态和复杂环境:将A3T框架应用于多模态环境,如结合视觉和语言的交互,以及更复杂的现实世界任务,以测试框架的泛化能力和鲁棒性。
长期自我改进:研究代理在长期自我改进过程中的行为变化,以及如何有效地平衡探索与利用,以实现持续的性能提升。
解释性和透明度:提高代理决策过程的解释性和透明度,使得A3T生成的行动和理由更容易被人类理解和验证。
对比学习和其他自监督学习方法:探索结合对比学习和其他自监督学习方法来进一步提升代理利用轨迹数据的能力。
更大规模的实验和验证:在更大规模的数据集和更多样化的任务上验证A3T框架的有效性,以及在现实世界应用中的潜力。
计算效率和资源优化:研究如何优化A3T框架的计算效率,减少训练和推理过程中的资源消耗,使其更适合部署在资源受限的环境中。
安全性和伦理考量:研究如何确保通过A3T框架训练出的代理在执行任务时的安全性,并符合伦理和社会标准。
人类与AI协作:探索A3T框架在人机协作场景中的应用,如何使代理更好地理解和配合人类的意图和行为。
这些方向不仅可以推动A3T框架的发展,也为语言代理和人工智能领域的研究提供了新的视角和挑战。
Q6: 总结一下论文的主要内容?
A:这篇论文的主要内容可以总结如下:
问题定义:论文旨在解决如何高效地训练语言代理(language agents)进行自主决策的问题,特别是在自动收集训练数据方面存在的挑战。
A3T框架:提出了一个名为A3T(Autonomous Annotation of Agent Trajectories)的框架,它能够在最小化人工监督的情况下,自主地注释代理的行动轨迹,并进行自我改进。
核心组件:
ActRe提示代理:解释任意行动的原因,辅助ReAct风格的代理合成新轨迹。
对比自训练:通过政策梯度方法和二值化奖励,利用成功和失败的轨迹进行对比学习。
实验验证:
在AlfWorld和WebShop两个环境中进行实验,验证了A3T框架的有效性。
与多个强基线模型进行比较,展示了A3T在单次尝试和迭代精炼后的成功率。
结果:
A3T在AlfWorld环境中达到了与人类专家相近的性能。
在WebShop环境中,A3T在多次迭代后的性能接近人类专家水平。
消融研究:通过消融实验进一步验证了A3T中各个组件的有效性,特别是政策梯度方法和二值化奖励的使用。
未来工作:论文提出了未来可能的研究方向,包括改进策略和奖励设计、应用到更复杂的环境、提高解释性和透明度等。
总体而言,这篇论文提出了一个创新的框架,通过自动化轨迹注释和对比自训练,显著提高了语言代理在多步骤决策任务中的性能,并展示了其在不同环境中的应用潜力。
以上内容均由KimiChat生成,深入了解论文内容仍需精读论文
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦















 1946
1946











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









