






知乎:北方的郎
链接:https://zhuanlan.zhihu.com/p/691070810
翻译自:https://www.superannotate.com/blog/mixture-of-experts-vs-mixture-of-tokens
事实证明,LLM的表现与模型大小和可扩展性呈正相关。这种扩展伴随着计算资源的扩展,也就是说,模型越大,成本就越高。

这是该行业面临的最大挑战之一。虽然专家混合(Mixture of Experts:MOE)最近被大肆宣传用于改进Transformer模型,但机器学习人员发现了一种更有前途的新方法——令牌混合(Mixture of Tokens:MOT)。MOE在尝试不同模型时表现出的某些缺点导致需要其他方法。在这篇博文中,我们将讨论这些新技术,并研究 MoT 在保持训练和推理成本的同时扩展大型语言模型的方式。
Mixture of Experts
Mixture of Experts 因显着优化 Transformer 的可扩展性而闻名。要理解这一点,我们首先要了解这些“专家”是谁。在 MoE 中,专家是专门执行一项或多项任务的模型。在标准Transformer模型中,令牌(token)由标准前馈层处理。MoE 没有采用这种方法,而是将每个token定向到一组专家以及一个称为控制器的小型网络。该控制器确保每个令牌仅由一小部分专家处理。进一步了解可以参考:https://arxiv.org/pdf/2310.15961.pdf
开关Transformer将每个令牌发送给控制器产生的得分最高的一位专家。这项技术导致参数大幅减少——从 1.6T 模型(T5 架构)到等效 1.4B vanilla Transformer 的 FLOPS 成本。
专家选择提供了一种略有不同的方法。不是让token选择前 k 个专家,而是专家自己选择前 k 个token。该方法保证了均匀的负载平衡(每个专家接收相同数量的令牌),并在训练效率和下游性能方面取得了显着的进步。然而,存在某些Token不被选择的风险。
当前方法的局限性
虽然大参数 MoE 架构的性能令人印象深刻,但它们在训练和推理过程中面临着一系列新的挑战。最值得注意的是:
训练不稳定性:这种方法谨慎地选择专家并将其与token匹配。这意味着控制器权重的微小变化可能会对控制器决策产生不成比例的影响。
负载不平衡: MoE 的问题是我们无法有效地平衡令牌和专家的分配方式,因为路由网络的选择没有受到有效的限制。这就是为什么有些令牌没有任何专家来处理它们(令牌丢弃),并且几乎所有令牌都只分配给少数专家(模型崩溃)。
信息泄漏:一些成功的 MoE 方法将序列中不同位置的令牌一起处理(即,通过比较批次中所有令牌的分数)。这造成了序列内信息泄漏并阻碍了它们在自回归解码中的实用性。
知识混合性:由于专家数量有限,传统 MoE 架构中的专家通常会积累广泛的知识。这种广泛的知识库削弱了个别专家的专业性和有效性。
知识冗余:多个专家在学习相似信息时有趋同的倾向,导致知识领域重叠和模型参数使用效率低下。
在他们最近的论文中,Cohere AI 的科学家讨论了解决MOE主要挑战之一的方法——必须将所有专家存储在内存中。他们通过将 MoE 架构与轻量级专家独特地结合起来,提出了参数极其高效的 MoE。他们的 MoE 架构优于标准 PEFT 方法,并且仅通过更新轻量级专家即可达到完全微调的效果——不到 11B 参数模型的 1%。
解决MOE的限制
在他们最近的论文中,Cohere AI 的科学家讨论了解决MOE主要挑战之一的方法——将所有专家存储在内存中。他们通过将 MoE 架构与轻量级专家独特地结合起来,提出了一种参数极其高效的 MoE。他们的 MoE 架构优于标准 PEFT 方法,并且仅通过更新轻量级专家即可达到完全微调的效果——不到 11B 参数模型的 1%。
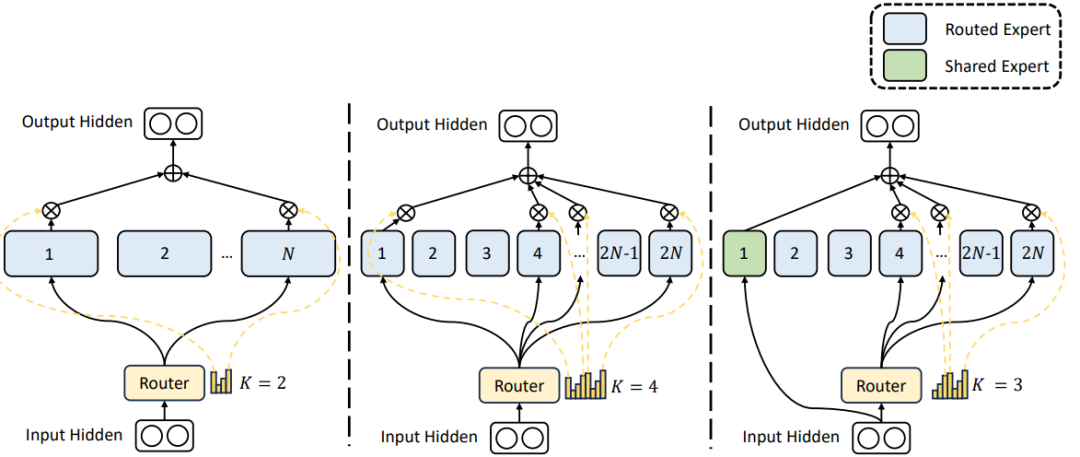
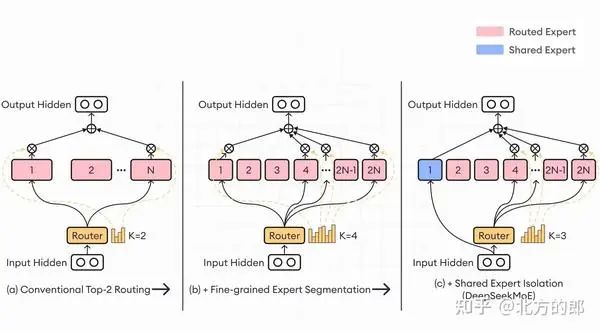
最近的一篇论文讨论了 MoE 的最后两个局限性,并提出了一种解决这些问题的新技术——DeepSeekMoE。这是新的 MoE 架构,旨在通过采用两个关键策略来增强专家专业化:细粒度专家分割和共享专家隔离。
细粒度专家分割(Fine-grained expert segmentation)涉及细分 FFN 中间隐藏维度,从而允许细粒度专家之间更细致地分配知识。这种细分使每个专家能够专注于更具体的知识领域,从而在保持恒定的计算成本的同时实现更高水平的专业化。
同时,共享专家隔离(shared expert isolation)策略将特定专家指定为“共享”,负责捕获不同背景下的共同知识。通过将一般知识集中在这些共享专家上,减少了其他专家学习过程中的冗余。这种方法提高了参数效率,并确保每位专家始终专注于独特且独特的知识领域。
DeepSeekMoE 经过扩展可训练 16B 模型,只需约 40% 的计算量,即可实现与 DeepSeek 7B 和 LLaMA2 7B 相当的性能。研究人员还计划将 DeepSeekMoE 扩展到 145B,突出其相对于 GShard 架构的优势,并展示与 DeepSeek 67B 相当的性能。
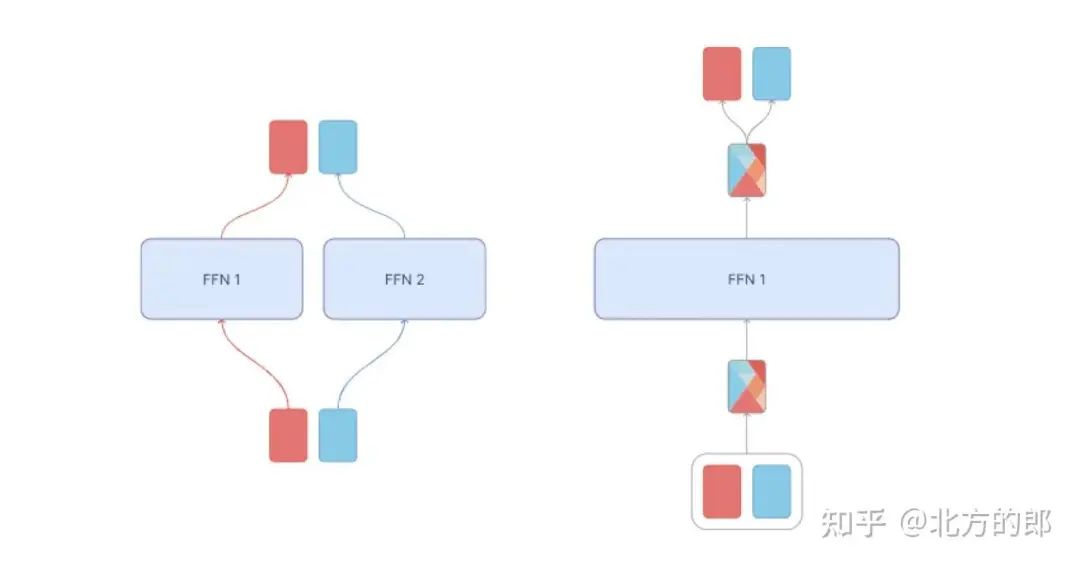
Token混合(Mixture of Tokens)
MoE 的几个缺点导致了混合Token(MoT)的兴起。这种对方法的轻微修改解决了所讨论的方法带来的许多问题。MoT 不是将token发送给专家,而是将不同示例中的token混合在一起,然后再将其提供给专家。这使得模型能够从所有token-专家组合中学习,并提高训练稳定性和专家利用率。在向专家提供token后,每种混合物都会被处理并重新分配回原始token。
token混合是如何进行的?首先,您需要为每个token设置重要性权重。这是通过控制器完成的,然后是对生成的token分数执行 softmax 层。因此,每个专家的token权重是独立计算的。最后,将每个token乘以其重要性权重,然后将它们全部加在一起。
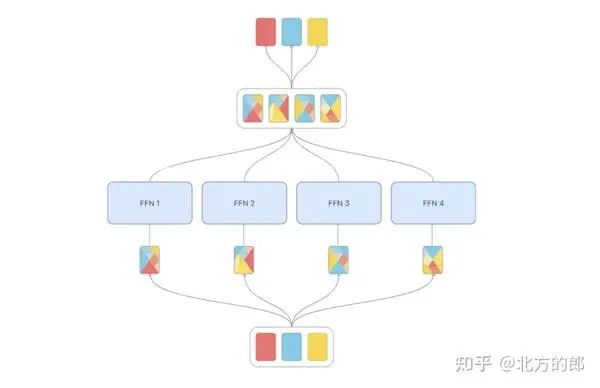
MoT 通过进行以下更改来解决 MoE 模型的问题:
混合来自不同示例的token,然后将其提供给专家;通过允许模型从所有token-专家组合中学习,这提高了训练稳定性和专家利用率。
token混合是一个完全可微的模型,这意味着它可以使用标准的基于梯度的方法进行训练。这避免了辅助损失或其他难以训练的技术的需要,从而更容易训练和部署。”
结论
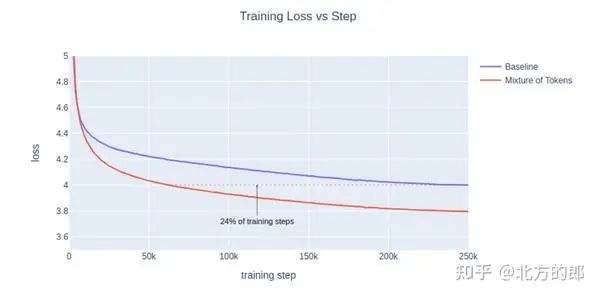
toke混合有可能显着提高LLM的表现和效率。与普通 Transformer 相比,它显示出训练时间减少了 3 倍的惊人结果。未来,我们预计 MoT 将继续带来更显着的改进。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦














 8760
8760











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









