






来自:包包的算法笔记
微软在4月23日发布了Phi-3,Phi-3用 3.8B 的小版本做到了 Mixtral-8x7B 一样的效果,换算到dense大约等于一个14B的水平。量化后大小约1.8G, 在 iPhone15 上一秒可以出 20 个 token。小版本训练用了3.3T token 训练,更大的模型用了4.5T token 。
在社交媒体上也得到了广泛的讨论。
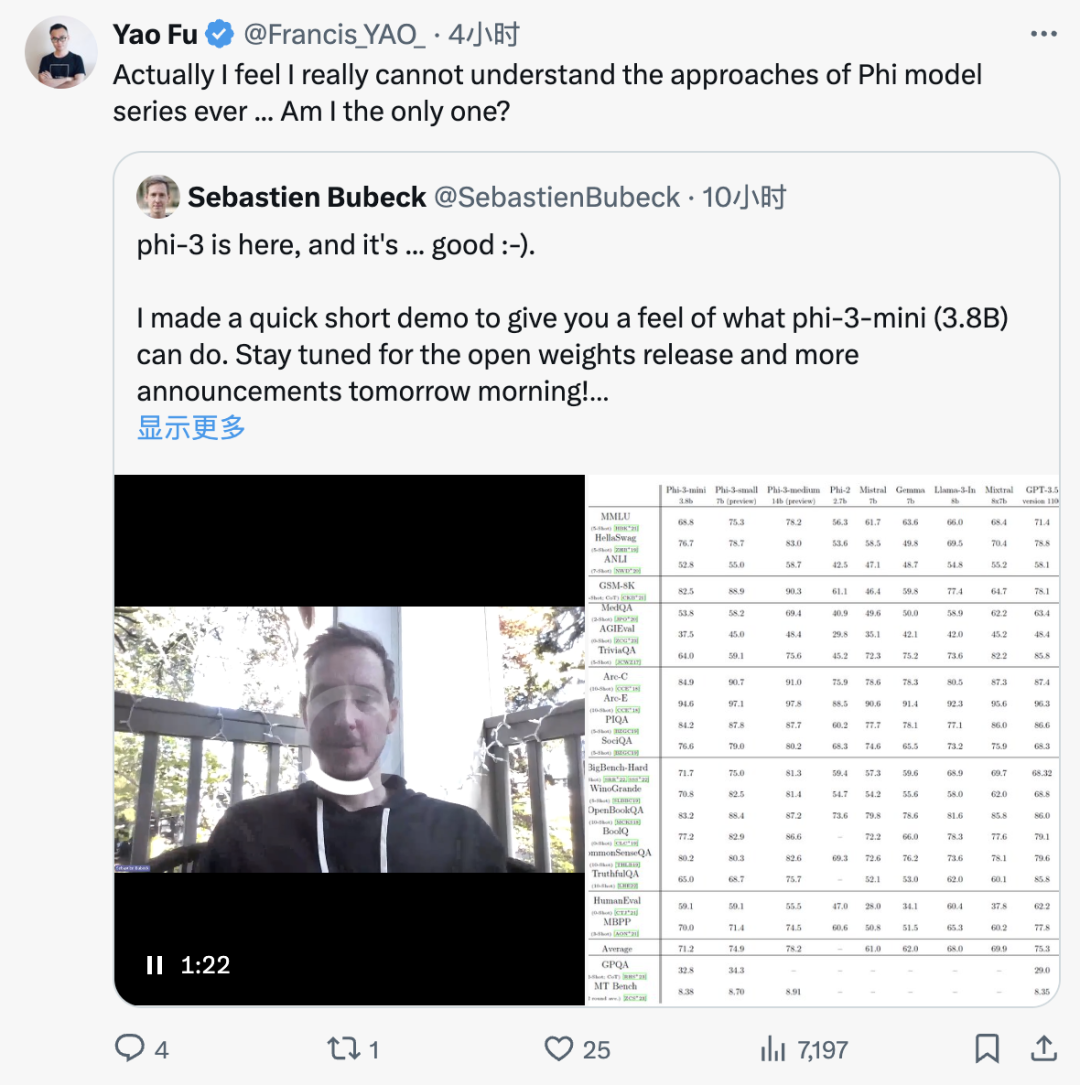
在reddit上有个有趣的帖子,Phi-3 仅用 4B大小在 香蕉逻辑问题🍌中击败了GPT 3.5 Turbo。
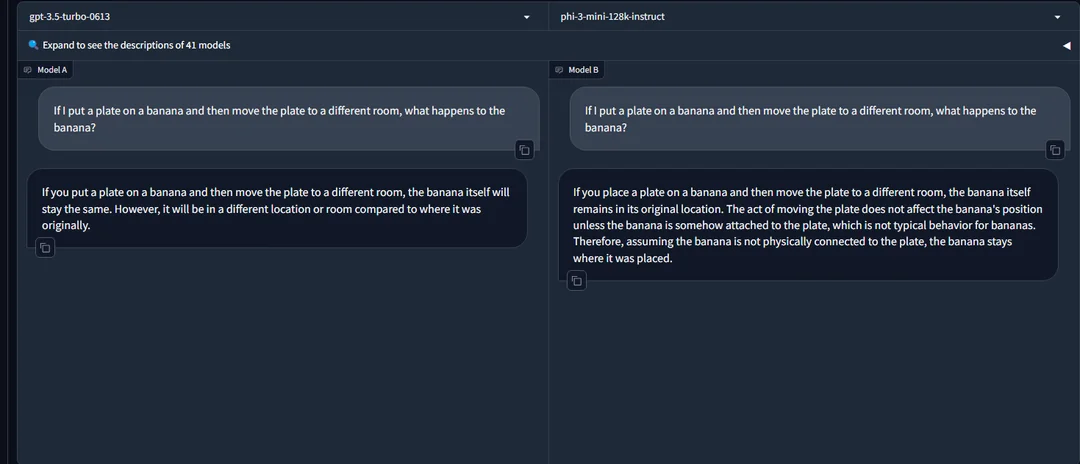
翻一下,类似弱智吧的问题: 一个香蕉上放了一个盘子,然后把盘子挪到另一个屋,香蕉会怎么样?
GPT3.5:香蕉完好无损,但是会挪动位置。
Phi-3:屁事没有,除非香蕉粘在了盘子上,否则还在原来的位置。
能看出GPT3.5被绕进去了,Phi-3在这个环节胜出。
能看出来,Phi-3确实用更小的参数实现了不错的效果。
Phi-3是微软Phi系列的第4个版本:
我们先回顾下4代的Phi发展路线。
23年6月的Phi-1[1],Phi1 模型参数规模 1.3B,仅需用8个 A100 训练 4 天即可完成。这个模型只能写代码,训练数据由 6B token的来自网络,经过严格清洗,另外有1B预训练+180M的指令微调数据,都由GPT-3.5 生成的合成数据组成。
洗数据的思路和我们之前提过的方法类似,用监督学习的质量打分模型筛选的方式,只不过这个模型用的是GPT4做的数据标注。具体是:从The Stack和StackOverflow中筛选的6B token训练数据,利用GPT-3.5生成的1B token合成数据(用于预训练),利用GPT-3.5生成的180M token合成数据(用于SFT)。
Phi-1模型在180M数据上SFT后,代码指标大幅提升。Phi-1-small模型Pass@1达到45%(SFT前为20%),Phi-1模型Pass@1达到51%(SFT前为29%)。
23年9月的Phi-1.5[2],Phi-1.5的训练数据包括两部分:来自Phi-1的7B训练数据,和新收集的20B合成数据。新收集的20B合成数据的主题从Phi-1的仅代码数据,扩展到了通用的世界知识和常识推理。作者构造了2万个主题作为种子,使用gpt生成数据。
Phi1.5还做了这样的实验,即只用网络数据训练,网络数据从Falcon 的数据集上过滤得到,简称过滤数据。还有原始的7B训练,20B生成的实验。
结论:过滤数据+合成+原始训练数据>合成+原始训练数据>过滤数据
证明了合成数据和代码数据对效果有提升作用。
23年12月的Phi-2[3],Phi-2有用的信息就更少了,只给出了一个技术博客。报告指出了Phi-2继续扩充了web过滤类的数据量,但最终的训练数据集大小没说。Phi-2将模型大小从1.3B提升到2.7B,并类似Phi-1.5-web在扩充后的混合数据集上一共训练了共1.4T token。
24年4月的 Phi-3[4],在Phi-3这一代,微软继续探索了和llama3一样的合成数据实验(在Phi-1时候已经使用),有所区别的是,llama3用了15T的token,Phi-3最多测试了4.5T的token。
能看出来微软是特别卷的,在这个事儿上的迭代速度保持了平均3个月一个版本。
总结Phi-3的关键信息:
1.Phi-3-mini是一个3.8亿参数的语言模型,尽管规模较小,但其性能与一些大型模型如Mixtral 8x7B和GPT-3.5相当。
2.Phi-3-mini的量化后部署在手机上,量化后1.8G 在 iPhone16 上每秒可以出 20 个 token。
3.Phi-3-mini的训练数据集是Phi-2所用数据集的扩展版,包含了大量过滤的网络数据和合成数据。基础版本3.3T token 训练,更大的模型用了4.5T,要比llama3。
4.长上下文支持:通过LongRope技术,Phi-3-mini还引入了长上下文版本,将上下文长度从默认的4K扩展到128K。
5.使用了pipeline的数据训练方式,第一阶段用高质量网络数据,第二阶段用更强力过滤后的一阶段子集加 GPT 合成数据。第一阶段学语言能力和常识,第二阶段主要学逻辑推理能力。
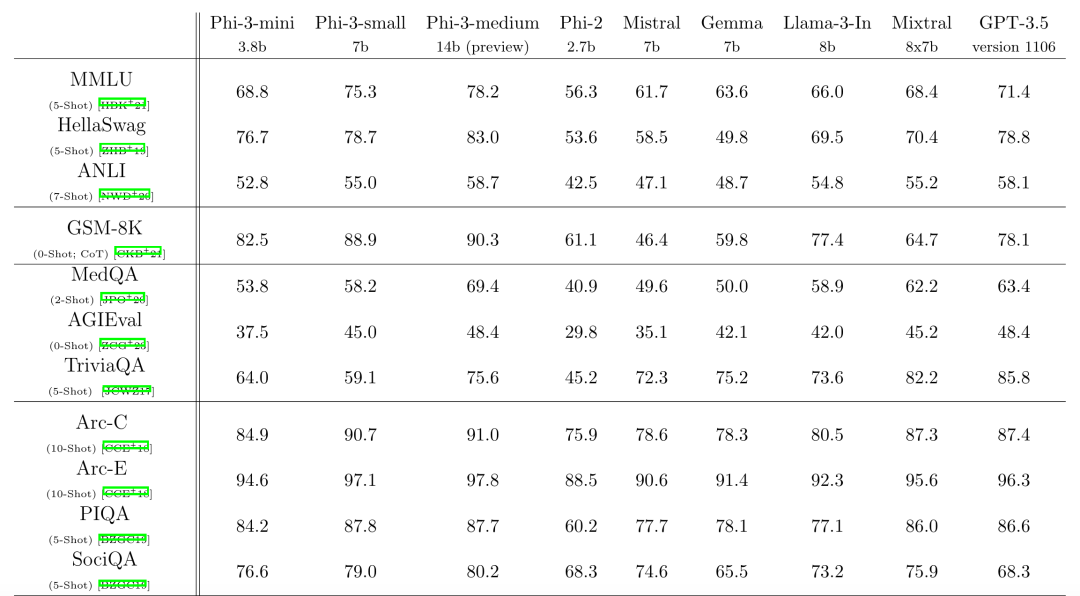
横向比较一下Phi从1到3代的关键信息,如下表所示:
| 模型 | 参数量 | 训练成本 (A100*小时) | 模型训练token数 | MMLU分数 |
|---|---|---|---|---|
| Phi-1 | 1.3B | 768 | 50B | - |
| Phi-1.5-web | 1.3B | 3000 | 300B | 37.9 |
| Phi-2 | 2.7B | 32,256 | 1.4T | 56.3 |
| Phi-3 | 14B | - | 4.5T | 68.8 |
从表格可以看出,除了微软一直强调的数据质量,数据量的增长和模型尺寸的扩大也是相当关键的。
数据,一直是目前大模型的核心秘密,各种号称开源的大模型,数据都几乎不开源。除了几个特定的瞄准“全开源”的模型,但是他们因为效果的原因没有得到特别高的关注度。
数据的来源,配比,多样性,质量方面的实践方法,成为各家大模型最深的“护城河”
另外作者也强调了一些局限性:
虽然 phi-3-mini 模型达到了与大型模型相似的语言理解和推理能力水平,但模型根本没有能力存储太多「事实知识」,这可以从 TriviaQA 上的低评分中看出,这个可能是参数大小的原因,对于知识类储备的拟合不是特别充分。但作者表示,这个可以用RAG来弥补,所以Phi-3有可能是最适合做RAG的高效率的小模型。
参考资料
[1] Textbooks Are All You Need : http://arxiv.org/abs/2306.11644
[2] Textbooks Are All You Need II: Phi-1.5 technical report: http://arxiv.org/abs/2309.05463
[3] Phi-2: https://huggingface.co/microsoft/Phi-2
[4] Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone: http://arxiv.org/abs/2404.14219
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









