







作者:苏肇辰
标题:Living in the Moment: Can Large Language Models Grasp Co-Temporal Reasoning?
录取:ACL2024 Main
论文链接:https://arxiv.org/abs/2406.09072
代码链接:https://github.com/zhaochen0110/Cotempqa
单位:苏州大学、上海人工智能实验室

🔍 背景与现有工作:
时间推理的重要性:时间推理对于语言模型理解世界至关重要。当前的时间推理数据集(如TIMEQA、TEMPLAMA和TEMPREASON)主要关注单一或孤立事件,未能充分反映现实世界中共时事件的复杂性。这些数据集的问题集中在单个时间点或孤立的事件上,而现实中事件往往是同时发生并相互交织的。
现有数据集:
TIMEQA:基于时间演变的事实构建问题,要求模型在特定时间点回答问题。
TEMPLAMA:从Wikidata知识库中提取结构化事实,用于封闭式问答。
TEMPREASON:将显式时间表达转化为隐式事件信息,提供更综合的时间问答评估框架。
🌟 我们的贡献 - COTEMPQA 数据集:
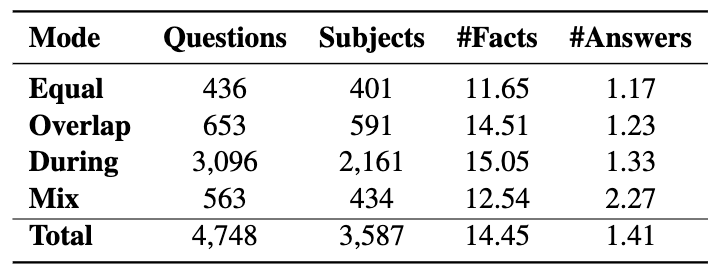

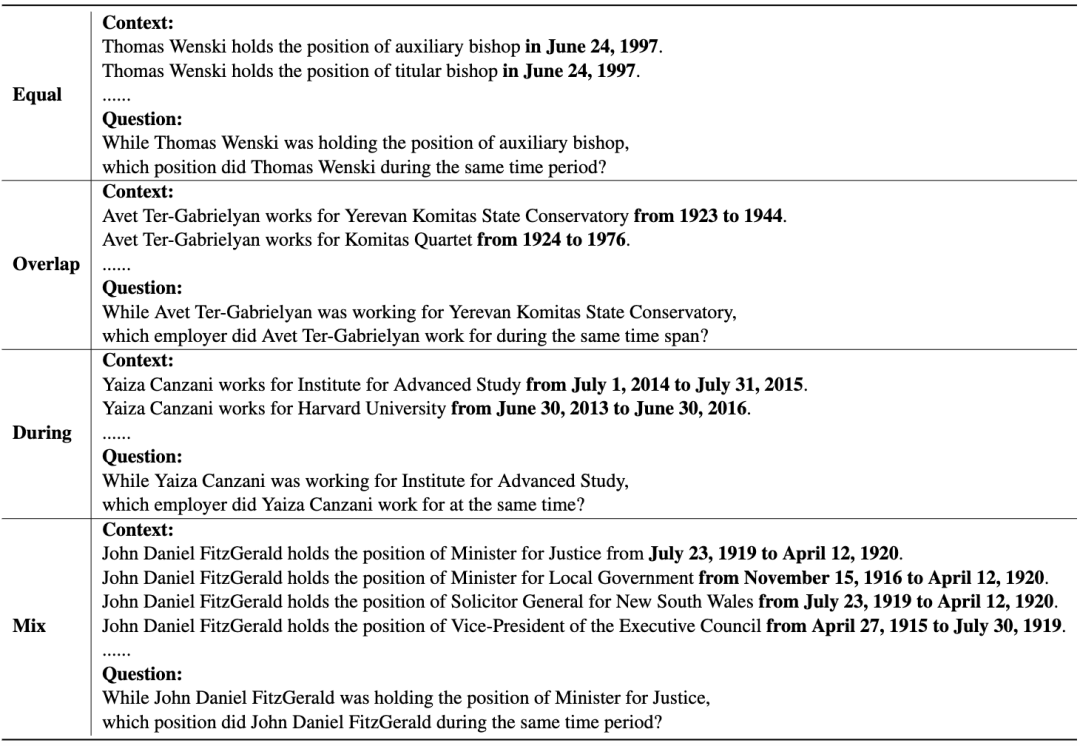
数据集简介:COTEMPQA是一个全面的共时问答基准,包含4748个样本,旨在评估大规模语言模型在四种共时场景(相等、重叠、期间、混合)中的理解和推理能力。
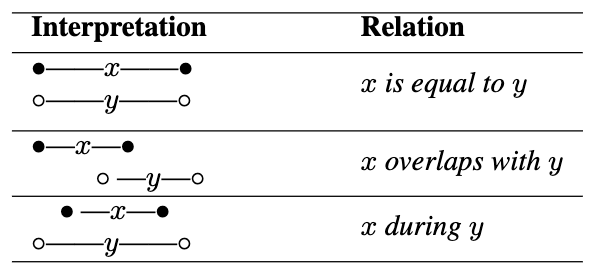
四种共时场景:
相等场景(Equal)
定义:两个事实发生在完全相同的时间范围内,没有时间差异。
特点:时间完全重叠,模型只需识别出相同的时间段。
示例问题:当A事件发生时,B事件也在同时发生。
重叠场景(Overlap)
定义:两个事实在时间上部分重叠。
特点:需要模型识别出部分重叠的时间段。
示例问题:当A事件发生时,B事件在时间段C内部分重叠。
期间场景(During)
定义:一个事实的时间范围完全包含在另一个事实的时间范围内。
特点:模型需要理解一个事件完全包含在另一个事件内的复杂时间关系。
示例问题:在A事件发生期间,B事件也在发生。
混合场景(Mix)
定义:包含相等、重叠和期间三种类型的混合情形,是最复杂的场景。
特点:需要模型处理多种时间关系的组合。
示例问题:当A事件发生时,B事件在相同时间段或部分重叠,或者一个事件包含在另一个事件中。
数据集构建过程:
从Wikidata提取时间相关事实
数据格式:将知识三元组和限定词转化为五元组格式(主体,关系,客体,开始时间,结束时间)。
分组整理:按主体分组,确保每组包含至少三个时间事实。
识别共时事实
算法设计:通过比较不同事实的时间戳来识别重叠部分,并将其分类为相等、重叠、期间或混合。
问答对构建
条件事实与查询事实:根据识别出的共时事实构建问题,选择一个事实作为条件事实,另一个作为查询事实。
预定义关系对与问题模板:为确保问题的逻辑关联性,我们预定义了17种相关关系对,并基于这些对构建问题模板。

📊 实验结果与分析:
模型表现:
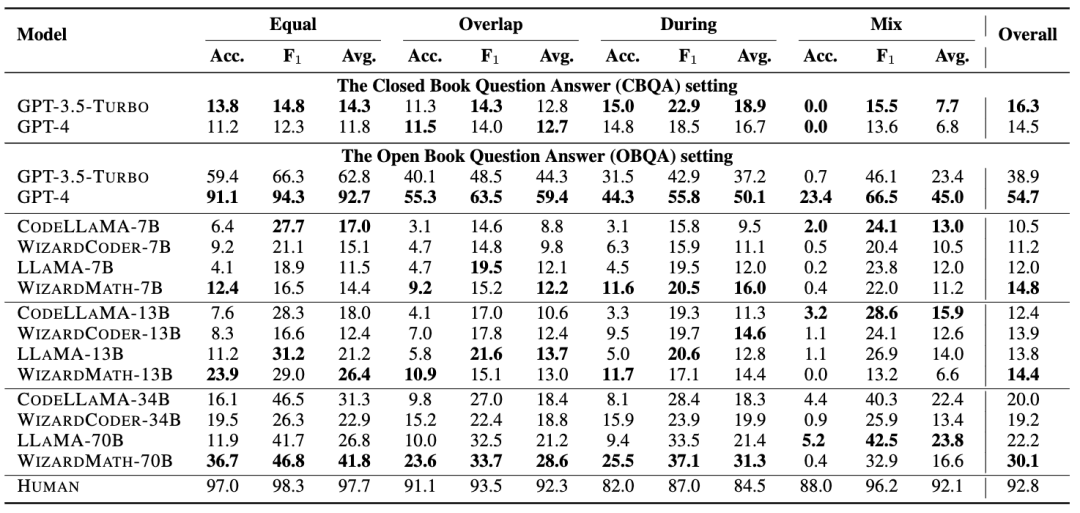
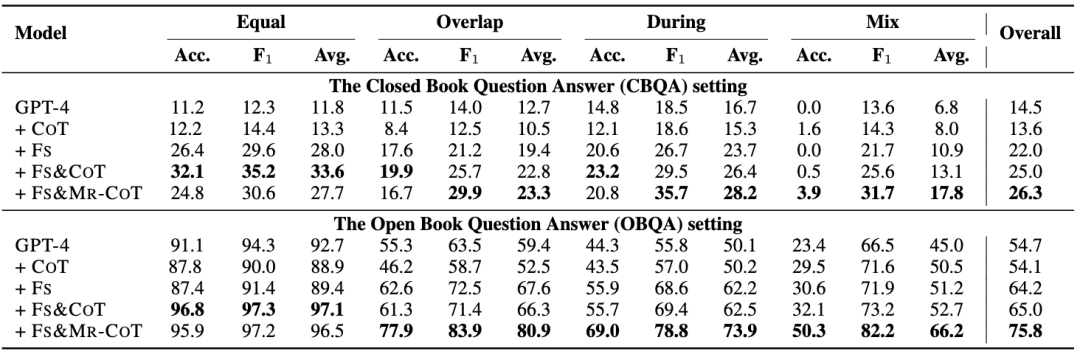
GPT-4 在共时推理中的表现:尽管GPT-4在所有模型中表现最好,但与人类水平(54.7 vs. 92.8)仍有显著差距。
不同场景的难度差异
相等场景(Equal):GPT-4表现较好(92.7)。
重叠场景(Overlap):表现显著下降(59.4)。
期间场景(During):进一步下降(50.1)。
混合场景(Mix):表现最差(45.0)。
闭卷问答(CBQA) vs. 开卷问答(OBQA)
闭卷问答:模型表现较弱,GPT-4为14.5。
开卷问答:表现提升显著,GPT-4为54.7。
错误分析:
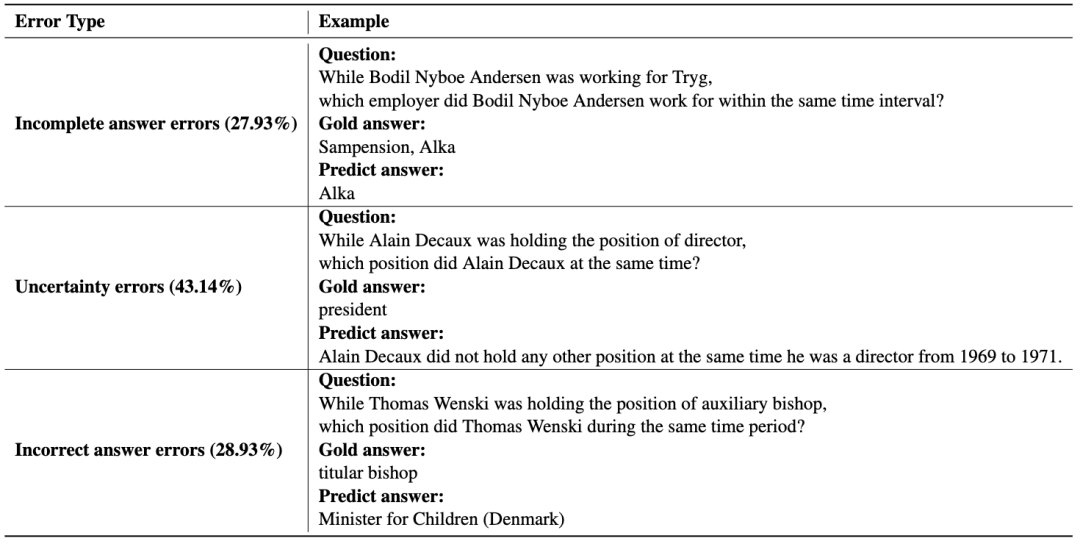
为了更好地理解模型所犯的错误,我们重点调查了GPT-4在零样本CoT下生成的回答。我们将错误分为三类:
根据案例错误分析,“不确定性错误”是最常见的错误类型,占比43.14%。我们认为GPT-4在回答时倾向于提供相对保守的回答,仅在具有一定信心时才返回答案。未来的研究需要优化模型的框架,进一步增强大规模语言模型在共时理解和推理方面的能力。
不完整答案错误:问题有多个正确答案,但模型未能返回全部正确答案。
不确定性错误:模型无法从提供的上下文中提取共时关系,并拒绝回答问题。
错误答案错误:模型返回了错误答案,表明模型在共时推理方面存在不足。
案例研究:
基本能力:现有的大规模语言模型(LLMs)能够有效地推理简单的共时事件。然而,它们在需要更深层次理解和复杂共时推理的任务中表现出困难。相等场景由于时间间隔完全重叠,对LLMs来说更容易处理。
复杂性增加:重叠和期间场景呈现出复杂的时间交叉,需要更多隐含推理来理解共时关系。相比于相等场景,确定一个时间段是否与另一个时间段相交(例如期间和重叠)更加具有挑战性。
混合场景:混合场景有多个正确答案,并包含各种共时关系,是最具挑战性的场景。模型在处理这些复杂情况时,需要更高的推理能力和准确性。
不同能力在共时推理中的作用

数学推理的作用:专门用于数学推理的模型(如WizardMath-70B)在共时推理中的表现显著提升,得分为30.1,而基础模型LLaMA-70B为22.2,CodeLLaMA-34B为20.0。这表明数学推理技能与理解和解释复杂时间关系所需的技能之间有很强的相关性。
混合场景的表现:尽管WizardMath在基准模型中表现最好,但在混合场景中的效果较低。进一步调查发现,在混合场景中,问题往往有多个答案。WizardMath倾向于返回单一答案,而不是列出所有可能的答案,这导致其精确度较高但召回率较低(与LLaMA、CodeLLaMA等模型相比)。
🔧 提升策略 - MR-COT:
数学推理的重要性:上述实验发现数学推理在处理共时事件中至关重要。以WizardMath-70B模型为例,基于数学推理的方法在共时推理任务中的表现显著优于基础模型LLaMA-70B。

提出的MR-COT策略:结合数学推理和链式思维的方法,显著提升模型在共时推理任务中的表现。具体步骤包括:
建立关键时间点:确定事件发生的具体时间。
结构化时间线:将相关事件按时间顺序排列。
数学识别重叠:通过数学方法识别事件的重叠部分。
实验结果:
MR-COT的优势:在开卷问答中重叠、期间和混合任务中分别提升14.6、11.4和13.5分,在闭卷问答中综合提升1.3分。这表明MR-COT策略在复杂共时推理任务中具有显著优势。
但同时相比较human performance (92.8) 还有很大的差距,说明模型的共时推理能力还有很大的提升空间。
💡结论
这篇论文中,我们提出了COTEMPQA数据集,并评估了现有大规模语言模型在共时推理任务中的表现。研究表明,尽管模型在简单的共时任务中表现良好,但在处理复杂的共时关系(如重叠、期间和混合场景)时仍存在显著差距。特别是数学推理能力对共时推理至关重要,专门用于数学推理的模型(如WizardMath-70B)表现最佳。通过结合数学推理和链式思维的方法(MR-COT),我们显著提升了模型在复杂共时任务中的表现。这项研究为未来改进大规模语言模型在共时推理中的能力提供了新的方向。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









