







标题
无矩阵乘法LLM - 一个来自线性Transformer的视角
时间
2024.8.17 周六 上午10:30-11:30
进群

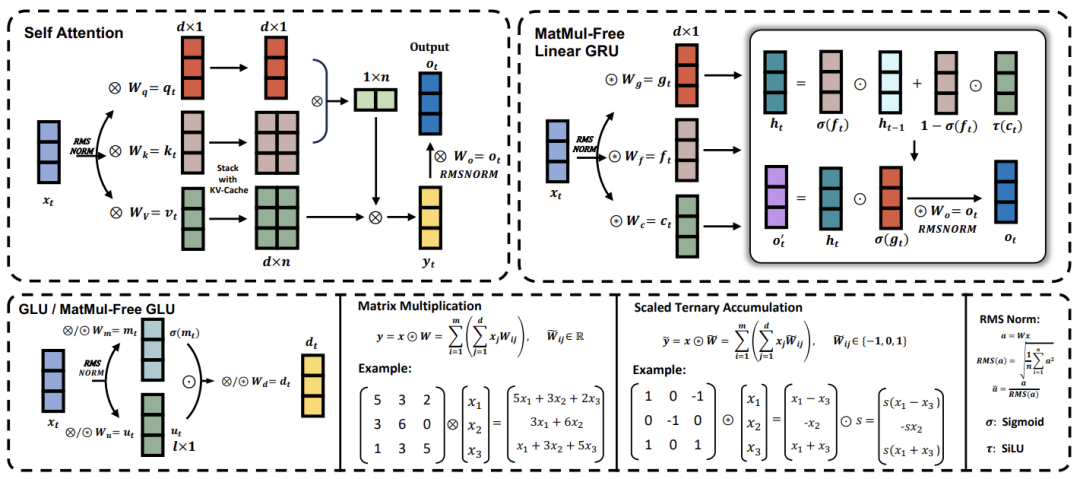
论文:Scalable MatMul-free Language Modeling
链接:https://arxiv.org/pdf/2406.02528
内容大纲
1. 背景:
- 无乘法网络
- 线性注意力机制
2. 无乘法语言模型组件介绍
- 线性无乘法token mixer
- 三值化channel mixer与fused结构
3. 深入分析无乘法token mixer
4. 实验
1. Downstream benchmark
2. Fused BitNet 的速度
引言
矩阵乘法(MatMul)通常是大型语言模型(LLMs)中计算成本最高的部分。随着LLMs的嵌入维度和上下文长度不断扩大,这一成本也在增加。本研究表明,我们可以完全消除LLMs中的MatMul运算,同时在数十亿参数规模上保持强大的性能。
我们的实验显示,所提出的无MatMul模型在至少27亿参数的规模上,其性能可以与需要更多推理内存的最先进Transformer模型相媲美。我们研究了扩展规律,发现随着模型规模增大,我们的无MatMul模型与全精度Transformer之间的性能差距在缩小。
我们还提供了这种模型的GPU高效实现,在训练过程中将内存使用减少了61%。通过在推理时使用优化的内核,我们模型的内存消耗可以比未优化的模型减少10倍以上。
为了准确量化我们架构的效率,我们在FPGA上构建了一个定制硬件解决方案,它能够利用GPU无法实现的轻量级操作。我们以13W的功耗处理了十亿参数级的模型,处理速度超过了人类可读的速度,使LLMs更接近于人脑的效率。
个人简介

朱芮捷是加州大学圣克鲁兹分校(UCSC)计算机工程专业的一年级博士生,他于2023年秋季开始在UCSC攻读博士学位,此前在中国电子科技大学获得学士学位。他的深度学习研究始于脉冲神经网络。在本科期间,他曾参与多个知名开源神经形态项目,包括snnTorch和SpikingJelly。随着研究兴趣的扩展,他将重点转向高效语言模型。他加入了RWKV(首个基于RNN的语言模型)的开发团队,并开发了SpikeGPT和Matmul-free LM。目前,他的研究主要聚焦于通过高效推理的视角来扩展模型规模。他对神经网络架构、语言模型优化以及高效计算方法等领域有兴趣。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦















 95
95

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









