







论文:Concise Thoughts: Impact of Output Length on LLM Reasoning and Cost
地址:https://arxiv.org/pdf/2407.19825
研究背景
研究问题:本文研究了大型语言模型(LLMs)在生成回答时输出长度的控制问题,特别是如何通过提示工程技术(如链式思维提示)来增强输出的解释性和正确性,同时减少生成时间。
研究难点:主要难点在于链式思维提示虽然能提高输出的正确性,但会导致输出长度增加,从而增加模型的生成时间。这在需要与用户进行交互的应用程序中是不可取的。
相关工作:现有工作主要集中在提高LLMs的准确性,但随着模型规模的增大,生成的回答往往更加冗长和复杂,导致其他问题,如幻觉和不必要的冗长解释。为了过滤掉无用的推理,已有研究提出了多跳处理技术。此外,提示工程技术如链式思维提示也被提出以提高问答任务的准确性,但其缺点是增加了输出长度。
研究方法
这篇论文提出了三种新的度量标准来评估LLMs生成的答案的正确性和简洁性,并提出了一种名为约束链式思维(CCoT)的新提示工程策略,以鼓励LLMs限制其推理长度。具体来说,
简洁正确性度量:论文提出了三个新的度量标准来评估LLMs生成的答案的正确性和简洁性。这些度量标准通过将简洁性方面整合到经典准确性度量中,重新定义了准确性度量。
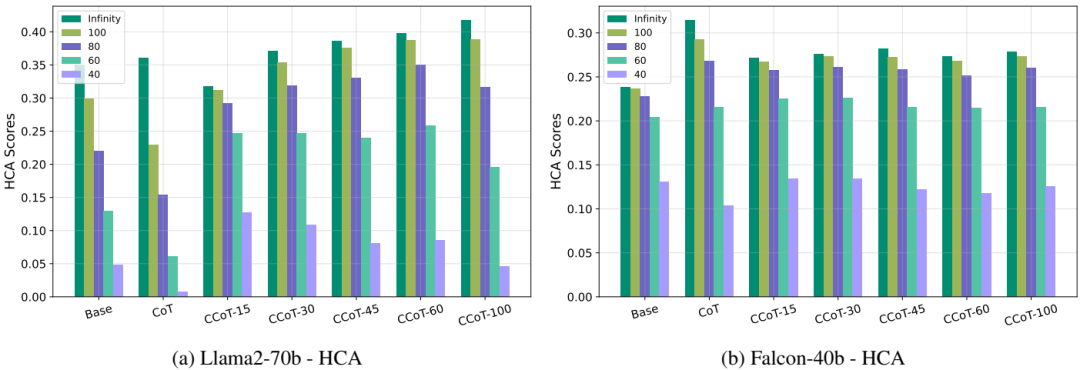
Hard-k Concise Accuracy (HCA):衡量不超过用户指定长度k的正确答案的比例。公式如下:
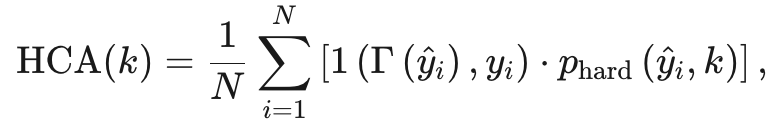
其中,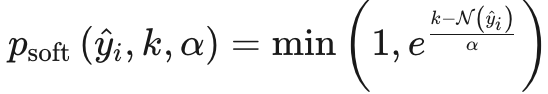
Consistent Concise Accuracy (CCA):进一步推广了前面的度量标准,还考虑了所有输出长度的一致性。公式如下:

其中,
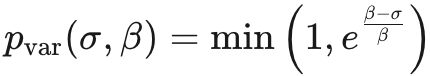
2. 约束链式思维(CCoT):为了控制CoT推理的长度,论文引入了一种约束链式思维提示,要求模型生成的输出长度小于给定的最大值。具体形式为:
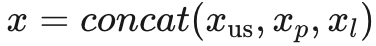
其中,x_l表示指定输出长度的句子,例如“并限制答案长度为30个单词”。
实验设计
实验在Text Generation Inference (TGI)平台上进行,使用了8个NVIDIA A100 GPU。具体设计如下:
数据集:实验在GSM8k测试集上进行,该数据集包含约1.3k个数学问题,主要用于评估模型处理数学推理和计算步骤的能力。
模型:评估了五种公开可用的预训练LLMs,包括Vicuna-13b-v1.5、指令微调模型Falcon-40b-instruct、Falcon-7b-instruct以及两个利用私有数据进行训练和增强的模型Llama2-7b-chat-hf和Llama2-70b-chat-hf。
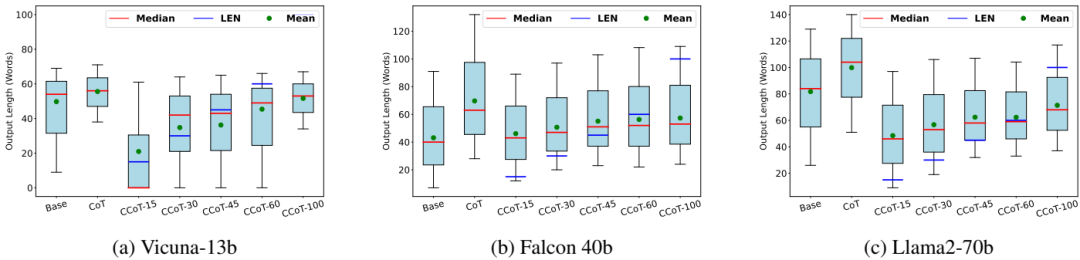
提示设置:对每个模型进行了普通提示(基础)、CoT和不同长度约束(15、30、45、60、100)的CCoT评估。
结果与分析
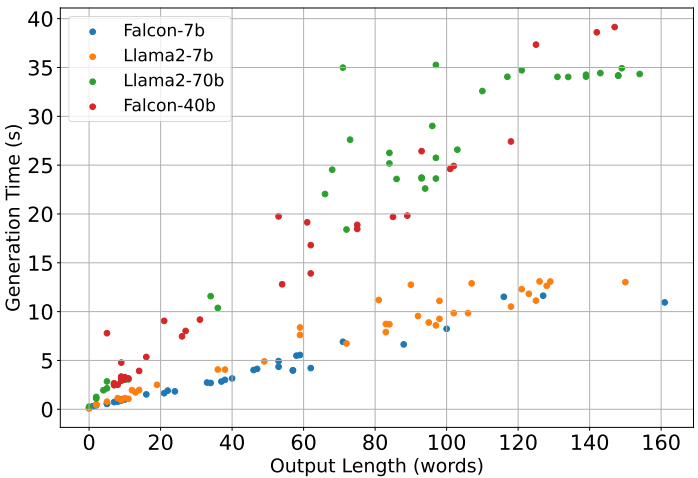
生成时间和准确性:CCoT提示能够显著减少大多数大型模型和大多数中型模型的生成时间,同时在许多情况下也优于普通提示。例如,对于Llama2-70b模型,经典CoT的平均生成时间为30.09秒,而长度约束为100的CCoT生成时间几乎减半,达到23.86秒。
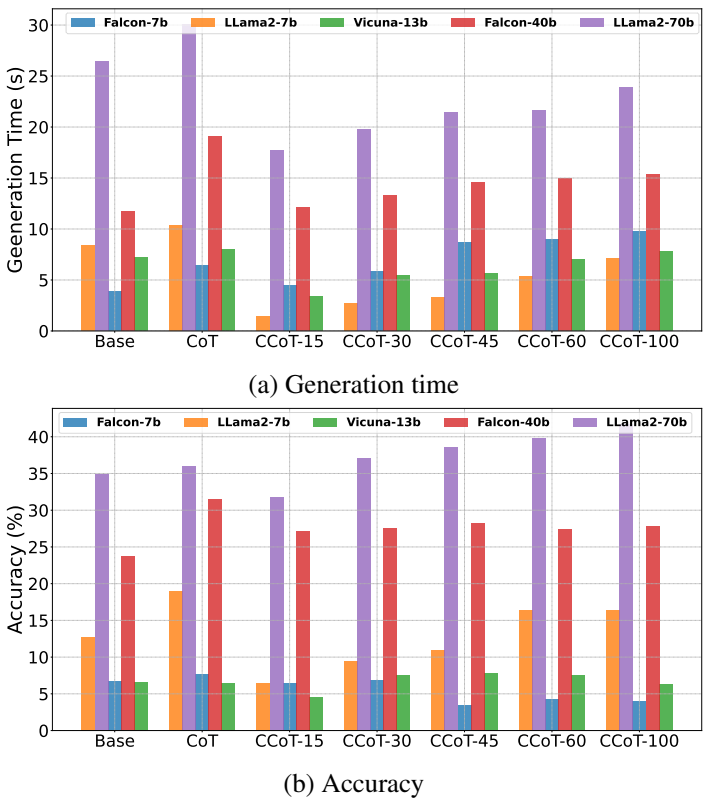
模型差异:较大的模型(如Falcon-40b和Llama2-70b)从CCoT中受益,能够在减少生成时间的同时提高准确性。而较小的模型(如Falcon-7b和Llama2-7b)则难以有效处理CCoT提示条件,导致生成时间增加或答案不准确。
输出长度控制:CCoT提示显著影响了输出长度,尽管在实践中LLMs并不总是能够严格遵守给定的长度限制,特别是对于较小的值(如15、30或40),这些值对小模型来说更具挑战性。
简洁正确性度量:HCA、SCA和CCA度量表明,CCoT提示在保持较高准确性的同时,能够有效控制输出长度。例如,对于Llama2-70b模型,使用CCoT-30的准确性为37.07%,而使用CCoT-100的准确性提高到41.77%。
总体结论
本文强调了LLMs生成的答案简洁性的重要性,并提出了三种新的性能指标来评估输出的正确性和简洁性。提出的约束链式思维(CCoT)提示策略能够在不牺牲准确性的前提下,有效控制输出长度,提高模型的时间可预测性。实验结果表明,CCoT在大模型中效果显著,但在小模型中效果有限。未来的研究方向包括深入理解小模型在处理CCoT提示时的困难,并将所提出的指标整合到微调过程中。
优点与创新
提出了三个新颖的指标,用于评估LLM输出的正确性和简洁性,强调了简洁和效率的重要性。
提出了约束链式思维(CCoT)提示策略,鼓励LLMs限制其推理长度,从而提高其时间可预测性。
在不同的预训练LLMs上进行了多项实验,展示了CCoT在提高大型模型的准确性和响应时间方面的有效性,同时指出了不同模型大小的局限性。
通过实验验证了所提出的度量标准在评估简洁正确性方面的益处,并展示了CCoT提示策略的效果。
提供了详细的实验结果和分析,展示了CCoT在不同模型和任务上的表现,为进一步研究提供了基础。
不足与反思
并非所有模型都能有效控制其输出长度,特别是小型模型(如Falcon-7b、Llama2-7b和Vicuna-13b)在遵守CCoT提示的长度约束方面存在困难。这些困难可能受到训练数据、模型参数数量等多种因素的影响,需要进一步研究和评估。
对于大型模型(如Falcon-40b和Llama2-70b),CCoT能够提高准确性和效率,但对于其他模型(如Falcon-7b),CCoT并未显著提高准确性。未来的研究可以分析简洁性对潜在幻觉现象或错误推理的影响。
提出的度量标准虽然能够评估输出的简洁性和正确性,但在实际应用中可能需要进一步调整和优化,以适应不同的任务和模型。
未来工作可以将所提出的度量标准整合到微调过程中,以更好地评估和改进LLMs的性能。
本文由元宝辅助人工完成。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦















 2271
2271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









