







论文:Disentangling Logic: The Role of Context in Large Language Model Reasoning Capabilities
地址:https://arxiv.org/pdf/2406.02787
研究背景
研究问题:这篇文章旨在系统地解耦纯逻辑推理和文本理解,通过研究来自多个领域的抽象和情境化逻辑问题的对比,探讨大型语言模型(LLMs)在不同领域中的真正推理能力。具体来说,研究提出了两个主要问题:(1)抽象逻辑问题能否准确评估LLMs在现实场景中的推理能力,解耦实际设置中的情境支持?(2)在抽象逻辑问题上微调LLMs是否能推广到情境化逻辑问题,反之亦然?
研究难点:该问题的研究难点包括:如何在不依赖实际情境的情况下准确评估LLMs的推理能力,以及如何在微调过程中平衡抽象逻辑和情境化逻辑数据的有效性。
相关工作:已有的研究主要集中在LLMs在特定任务上的表现,但这些任务往往缺乏对逻辑推理能力的全面评估。此外,现有的基准测试(如DyVal)虽然能够生成形式逻辑模板,但未能充分考虑到情境对推理能力的影响。
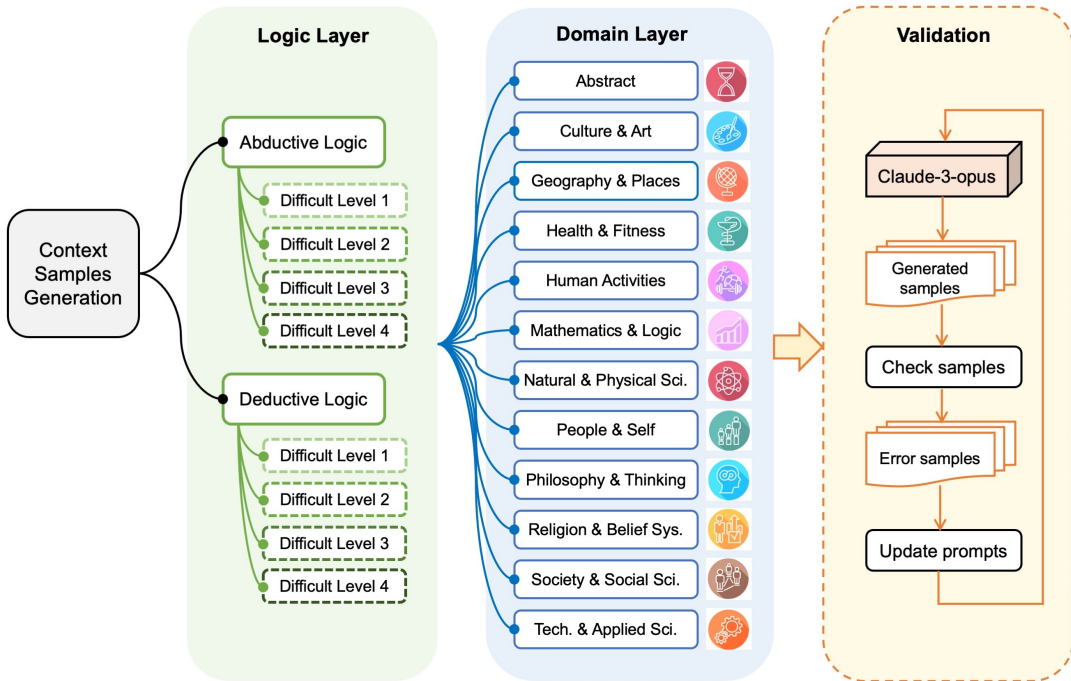
研究方法
这篇论文提出了ContextHub基准,用于评估LLMs的核心推理能力,并解耦情境信息的影响。具体来说,
创建形式逻辑推理问题模板:首先,利用DyVal动态生成四种难度的形式逻辑模板。DyVal使用树结构来动态构建逻辑问题,树结构的叶节点表示前提,中间节点表示中间推理步骤,最终结果由根节点表示。公式如下:
 2. 情境化实例化:将生成的逻辑模板在每个领域进行实例化。具体步骤包括:
2. 情境化实例化:将生成的逻辑模板在每个领域进行实例化。具体步骤包括:
变量替换:将逻辑模板中的每个变量替换为相关领域中的具体实例。
模板替换:根据替换后的变量生成连贯的自然语言描述。
抽象实例化:为了增加数据点的数量,创建一个“抽象”领域,其中使用启发式规则将命题变量替换为不同长度的任意字符序列。
质量控制:通过Claude 3 Opus和5个人类专家的双重检查确保实例化评估样本的正确性。检查包括常识检查、合理性和恒等性检查。
实验设计
数据收集:使用DyVal生成四种难度的形式逻辑模板,并在12个领域进行情境化实例化。每个领域随机选择一个子类别进行实例化,确保多样性和具体性。
实验设计:实验分为基准测试和微调两部分。基准测试部分评估模型在不同领域和抽象与情境化逻辑问题上的表现。微调部分探索了使用抽象逻辑实例化和情境化逻辑实例化进行模型微调的效果。
样本选择:每个领域的实例化数据包括5个不同难度级别的样本,总共18,240个数据点。
参数配置:微调过程中使用QLora进行开源模型的微调,其他相关超参数包括:epochs=3,warmup proportion=0.01,learning rate=3e-4,weight decay=0.01,lora rank=64,lora dropout=0.05,lora alpha=16,batch size=4,accumulate gradient steps=8。
结果与分析
基准测试结果:模型在抽象逻辑和情境化逻辑问题上的表现因模型大小和领域而异。较大的模型在抽象逻辑问题上表现更好,而较小的模型更依赖情境线索。领域对模型性能有显著影响,数学和哲学领域最具挑战性,而人类活动领域表现最佳。
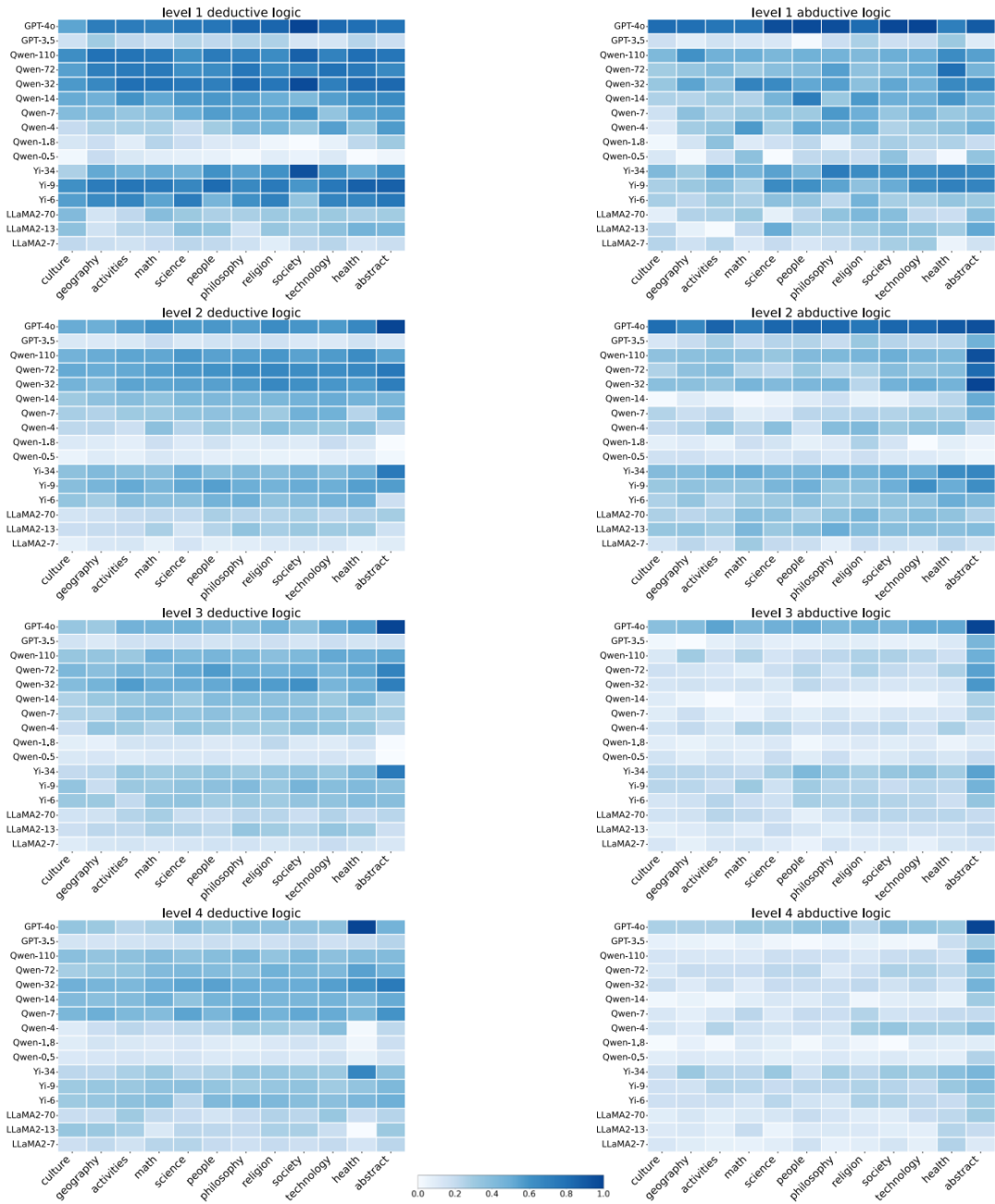
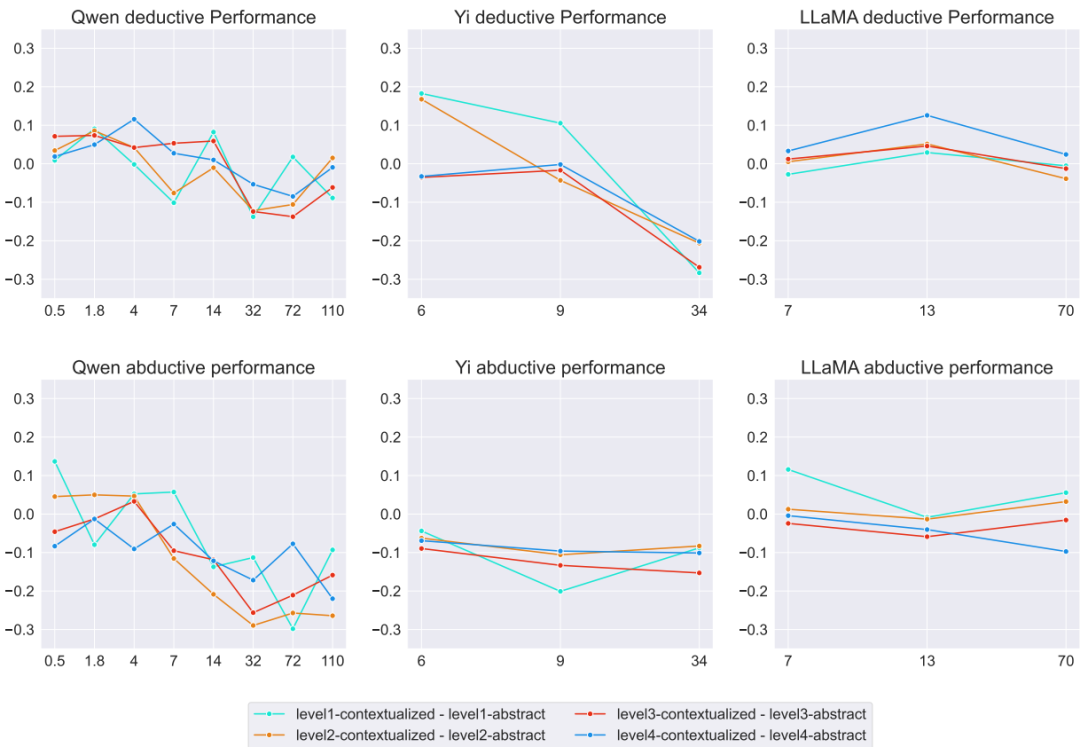
微调结果:
抽象数据与情境化数据的对比:仅在抽象数据上微调的模型在抽象逻辑问题上表现良好,但在情境化数据上表现较差。相反,在情境化数据上微调的模型在所有问题上均表现出色,尤其是在较低难度级别上。
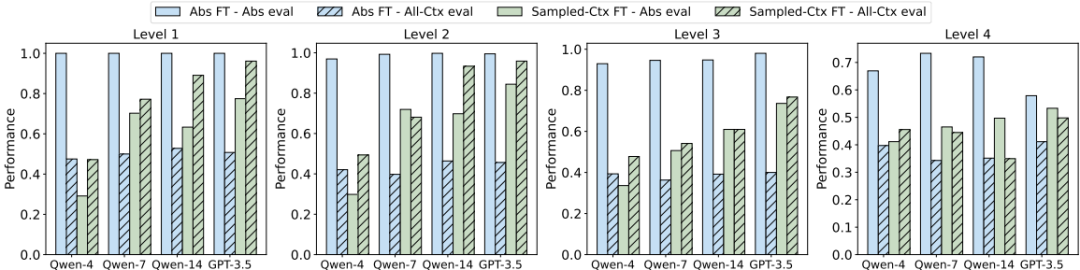
模型规模对泛化能力的影响:在情境化数据上微调时,较大模型的性能提升更显著,表明情境化数据具有更好的泛化潜力。
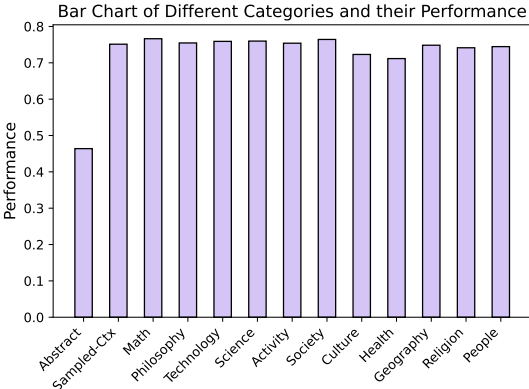
单领域与多领域微调的比较:单领域微调的数据在泛化能力上与多领域微调的数据相似,甚至有时表现更好,表明领域多样性对泛化能力的影响有限。
总体结论
这篇论文通过ContextHub基准深入探讨了LLMs的逻辑推理能力,发现模型在特定任务上的表现受情境或领域的影响显著。实例化数据在微调过程中表现出更好的泛化能力,表明其在训练模型以应对各种推理任务方面更为有效。未来工作可以探索使用实例化数据进行更复杂推理任务的模型微调,以及开发更能捕捉现实世界推理场景细微差别的基准测试。
AI辅助人工完成。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









