






论文:Planning In Natural Language Improves LLM Search For Code Generation
链接:https://arxiv.org/pdf/2409.03733

研究背景
研究问题
本文研究了如何在大语言模型(LLMs)的推理计算中进行有效的搜索,以提高代码生成的性能。具体来说,作者发现当前LLMs在推理时缺乏多样性,导致搜索效率低下。
研究难点
该问题的研究难点包括:
如何在推理时增加LLMs输出的多样性
如何有效地利用这种多样性来提高搜索效果
相关工作
经典的搜索算法如广度优先搜索、深度优先搜索和A*搜索在路径规划、规划和优化中有广泛应用。近年来,蒙特卡罗树搜索(MCTS)在游戏领域取得了显著成功。在语言模型搜索方面,Beam搜索显著提高了翻译系统的性能,repeated sampling方法通过多次生成候选代码来提高性能,但这些方法主要关注输出空间的搜索,而非潜在的想法空间。
研究方法
本文提出了PLANSEARCH算法,用于解决LLMs在推理时缺乏多样性导致搜索效率低下的问题。具体步骤如下:
生成多样化观察:从自然语言描述的问题出发,生成多个关于问题的观察(observations),这些观察可以是提示、线索或初始想法。
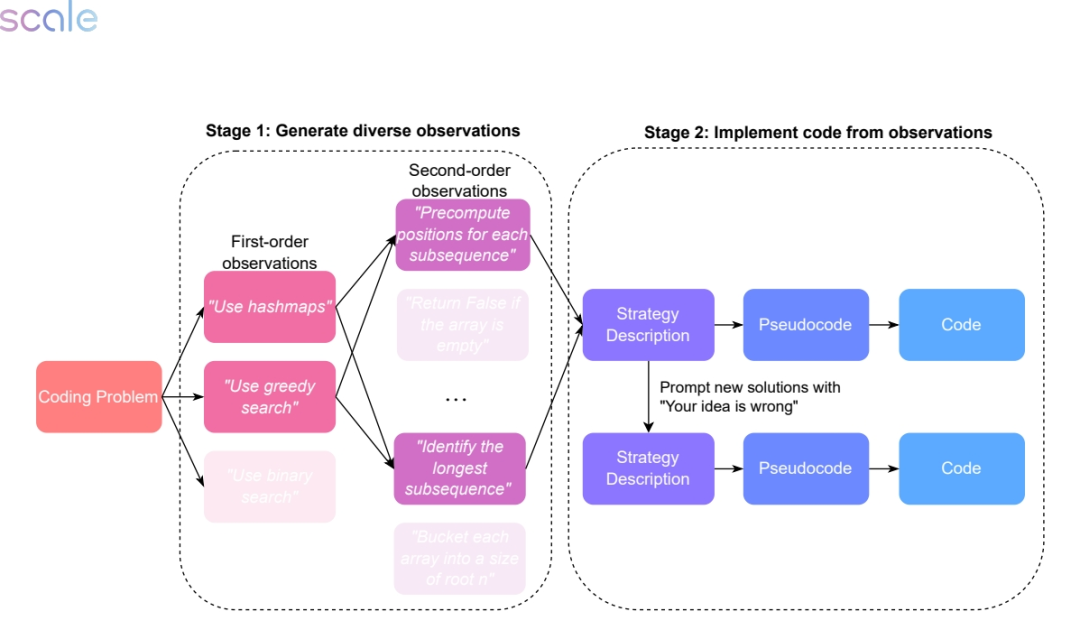
组合观察:将生成的观察组合成候选计划(plan),每个计划是一组有助于解决问题的观察和草图。通过组合所有可能的观察子集,最大化在想法空间中的探索。
实现代码:将每个候选计划转换为自然语言描述的策略,然后进一步转换为伪代码和实际Python代码。为了减少翻译错误,采用了更细粒度的提示方法。
评估多样性:使用LLM作为评委,通过成对匹配策略测量生成的代码在想法空间中的多样性。多样性得分定义为两个随机选择的代码实现不同想法的概率。
公式:
其中, 是一个函数,表示两个代码 和 是否实现相同的想法,是生成的代码总数。
实验设计
数据集
实验在三个基准上进行:MBPP+、HumanEval+和LiveCodeBench。MBPP+和HumanEval+是广泛使用的代码基准,LiveCodeBench是一个包含竞争编程问题的基准,通常需要高级推理能力。
实验细节
所有搜索算法的输出代码必须符合指定的格式,并通过运行所有测试来标记正确性。所有模型使用温度0.9和top-p 0.95进行生成。为了计算pass@k,使用无偏估计器:
其中,是在k次提交中至少一次解决概率。
结果与分析
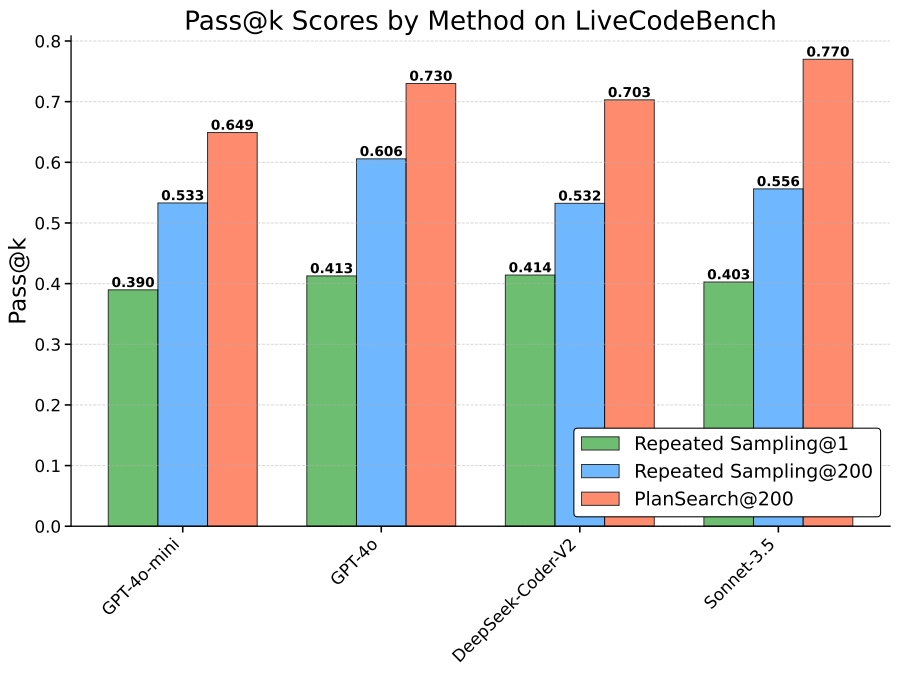
LiveCodeBench
在LiveCodeBench上,使用PLANSEARCH的Claude 3.5 Sonnet模型达到了state-of-the-art的pass@200为77.0%,显著优于未使用搜索的最佳得分(pass@1=41.4%)和标准重复采样得分(pass@200=60.6%)。
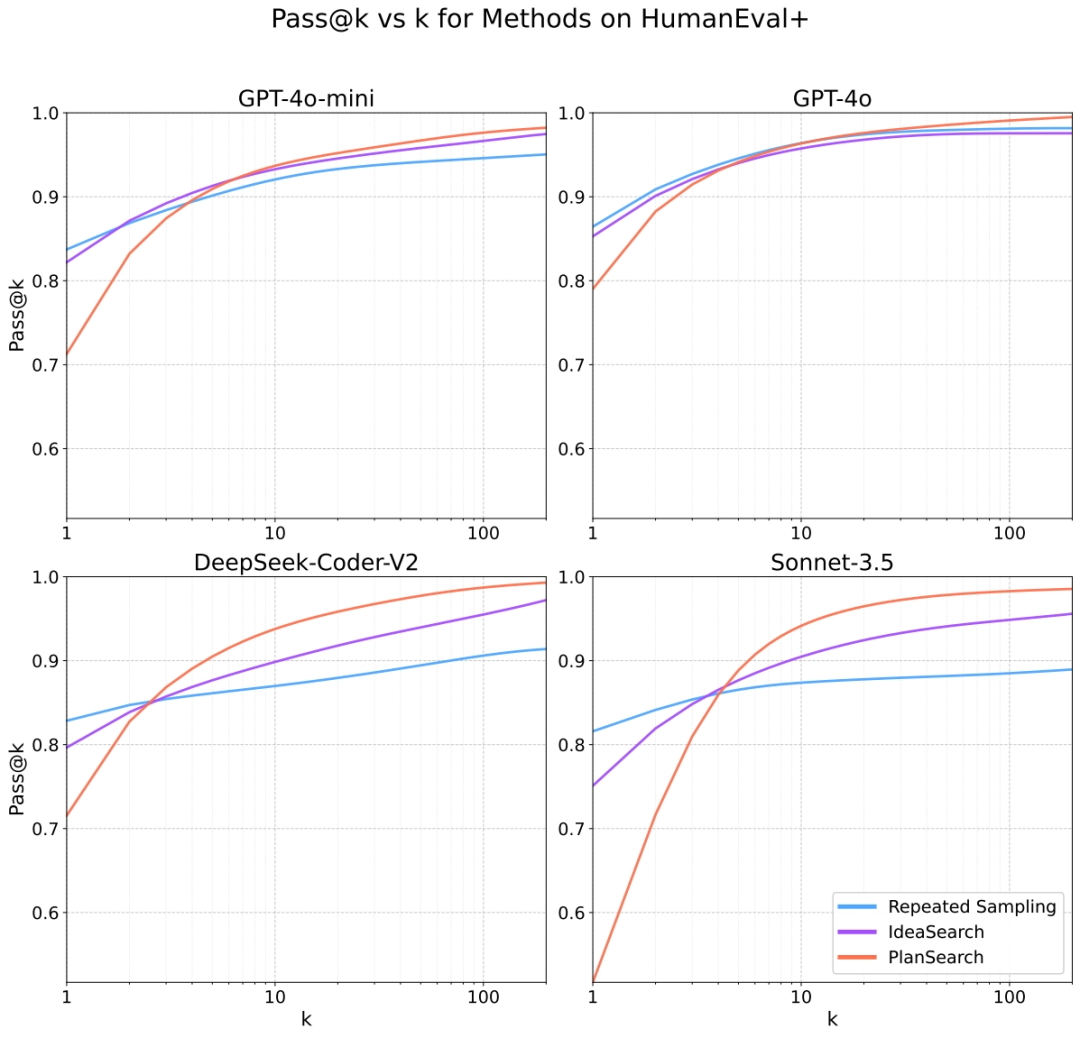
HumanEval+
在HumanEval+上,PLANSEARCH也表现出色,pass@200得分为86.4%,优于未搜索的最佳得分(pass@1=81.6%)。
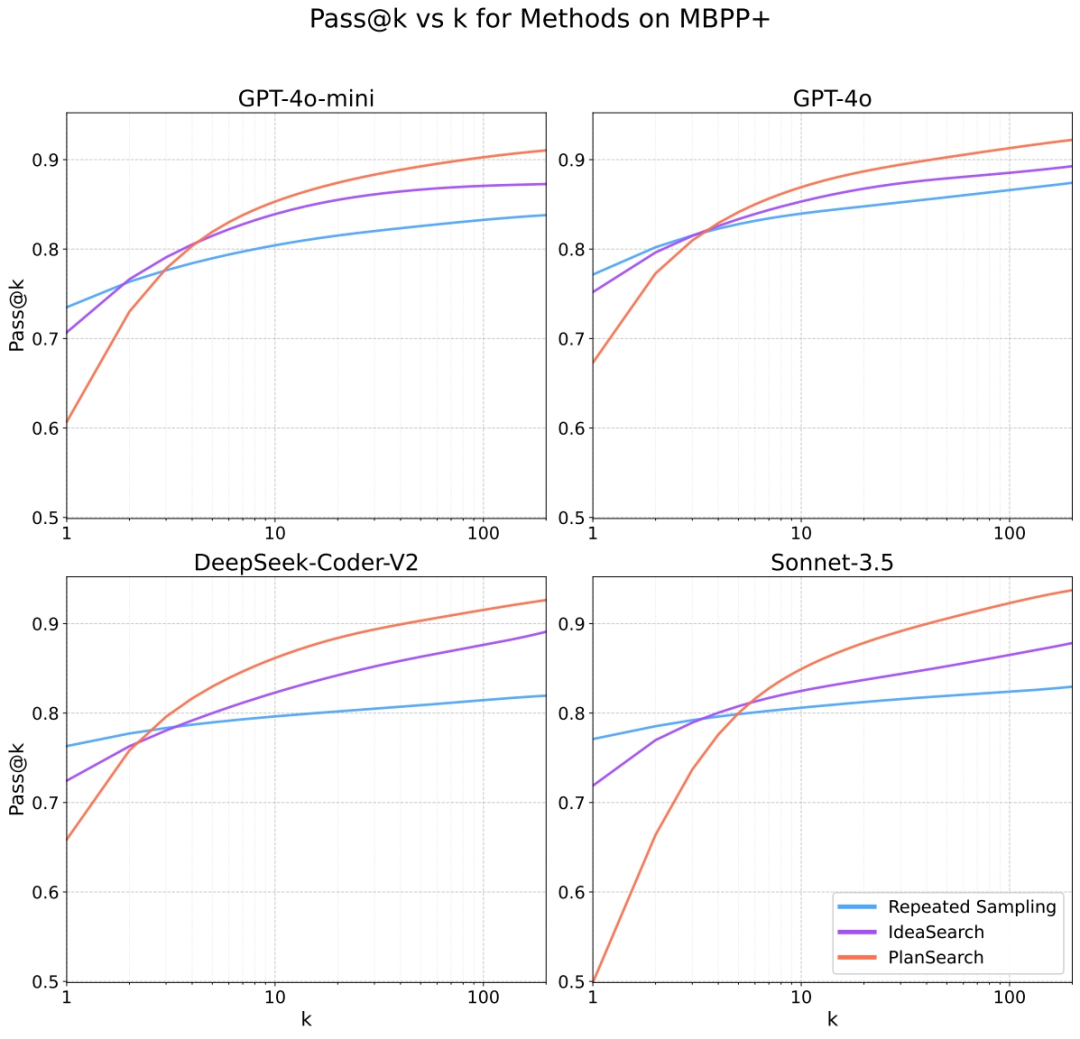
MBPP+
在MBPP+上,PLANSEARCH的pass@200得分为89.3%,同样优于未搜索的最佳得分(pass@1=73.5%)。
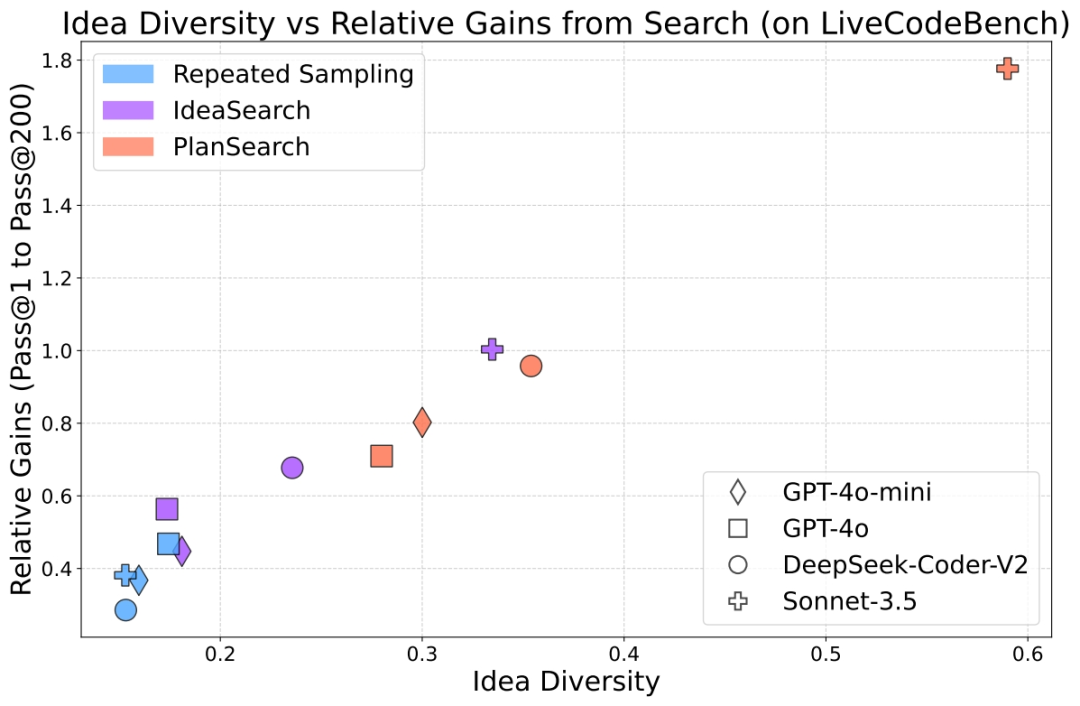
多样性分析
通过测量想法空间中的多样性得分,发现多样性得分与搜索性能的相对改进高度相关。这表明在想法空间中有效探索多样性是提高LLMs搜索效果的关键。
总体结论
本文提出的PLANSEARCH算法通过在自然语言中搜索可能的计划来增加LLMs输出的多样性,从而显著提高了代码生成的性能。实验结果表明,PLANSEARCH在多个基准上均优于现有的搜索方法,特别是在使用较小的模型时,PLANSEARCH的效果更佳。未来的工作可以进一步优化后训练目标,以最大化质量和多样性,并探索更高层次的抽象搜索。
本文由AI辅助人工完成。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注















 881
881

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









