






论文:MagicDec-part2: Breaking the Latency-Throughput Tradeoff for Long Contexts with Speculative Decoding
链接:https://infini-ai-lab.github.io/MagicDec-part2

研究背景
研究问题
本文旨在解决大型语言模型(LLMs)在长上下文应用中,如何在低延迟和高吞吐量之间取得平衡的问题。具体来说,传统的投机解码(Speculative Decoding, SD)技术在小批量下效果显著,但在大批量下表现有限。
研究难点
该问题的研究难点包括:
如何在中等到长序列长度下,通过投机解码技术提升吞吐量。
保持解码过程中低延迟和高准确性的平衡。
相关工作
相关领域已有多项研究,主要包括:
Flash-decoding、Flash-decoding++、FasterTransformers 等通过系统优化技术来降低解码延迟。
vLLM 和 ORCA 等方法通过增加请求数量来提高吞吐量。
量化和剪枝技术通过模型压缩同时提升吞吐量和降低延迟。
研究方法
本文提出了一种新的方法 MagicDec,用于解决 LLMs 在长上下文应用中吞吐量与延迟之间的权衡问题。
1. 理论分析
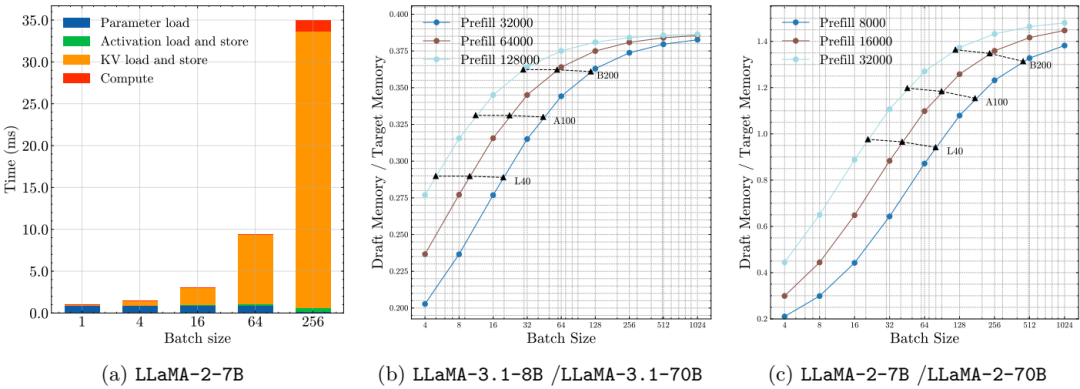
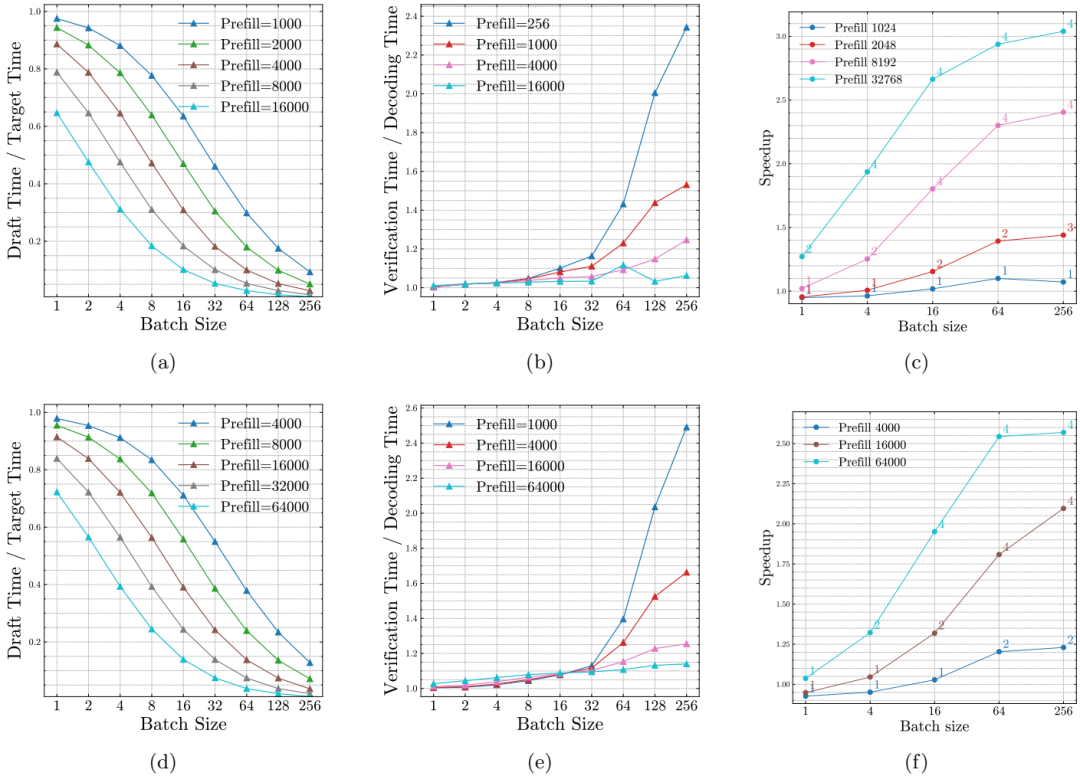
首先,本文对 LLM 推理性能进行了理论分析,发现随着批量大小和序列长度的增加,LLM 解码受内存限制,特别是 KV 缓存 成为主导瓶颈,并且这种瓶颈随批量大小线性增长。
2. 数学建模
推导了投机解码加速的数学公式,考虑了草稿模型与目标模型的解码时间比、验证时间与目标解码时间的比以及预期生成长度。公式如下:
其中, 表示一次验证步骤中预期的生成令牌数, 为接受率, 为投机长度。
3. 关键因素分析
通过公式分析了影响投机解码加速的三大关键因素:
草稿模型与目标模型的解码时间比
验证时间与目标解码时间的比
预期生成长度
特别地,发现对于长序列和大批量,KV 缓存大小是决定性的因素。
实验设计
数据集
实验在 PG-19 数据集上进行,每个样本生成 64 个令牌。
草稿模型选择
实验使用了两种类型的草稿模型:
自投机模型:使用 LLaMA-2-7B-32K 和 LLaMA-3.1-8B-128K 模型,测试不同的 StreamingLLM 缓存预算。
独立 GQA 模型:使用 LLaMA-2-7B-32K 作为目标模型,TinyLLaMA-1.1B 作为草稿模型。
系统实现
实验基于 GPT-Fast 构建投机解码系统,使用 FlashAttention 加速注意力计算。针对 GQA 模型的多令牌验证问题,修改了 FlashAttention 的实现。
优化
使用 Pytorch CUDA 图减少 CPU 侧内核启动开销。
针对 GQA 模型进行了优化,以提高验证速度。
结果与分析
吞吐量与延迟
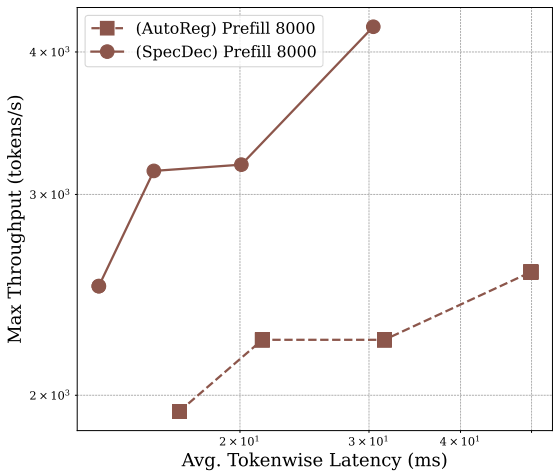
实验表明,投机解码在不同批量大小和序列长度下的吞吐量显著优于自回归解码。例如,LLaMA-2-7B-32K 在序列长度为 32k、批量大小为 32 时,投机解码比自回归解码快 2 倍。
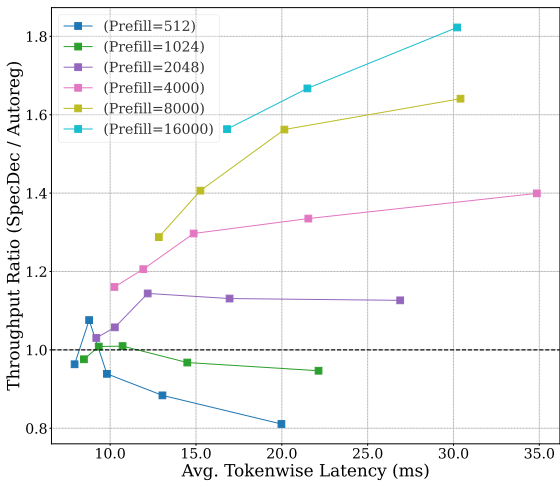
关键序列长度
理论分析和实验验证显示存在一个临界序列长度 ,当序列长度超过该值时,投机解码的加速效果随着批量大小的增加而增加。
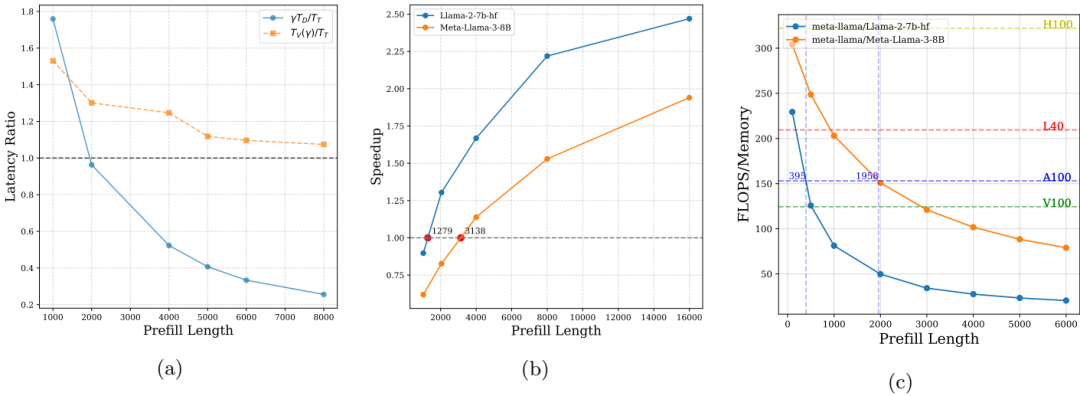
设备差异
在 8 A100 GPU 上的实验结果显示,随着序列长度和批量大小的增加,投机解码的加速效果更加显著。例如,LLaMA-3.1-8B 在序列长度为 100k,批量大小为 32 时,投机解码比自回归解码快 1.84 倍。
总体结论
本文重新评估了长上下文场景下的吞吐量与延迟的权衡问题,证明了投机解码可以显著提高吞吐量、减少延迟并保持较高的准确性。通过理论和实证分析,揭示了随着序列长度和批量大小的增加,瓶颈从计算限制转向内存限制,使得投机解码在长序列和大批量情况下同样有效。这些结果强调了将投机解码集成到吞吐量优化系统中的必要性,以应对长上下文工作负载的普及。
本文由AI辅助人工完成。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









