







作者: 丁誉洋
项目链接: https://scalequest.github.io/
复杂任务的推理能力已成为当前大语言模型的核心竞争力,也是各大厂商争相角逐的关键领域。OpenAI将其 o1 模型定位为"解决复杂问题的推理模型",幻方、千问等团队也相继推出了专注于数学和编程的领域大模型。
高质量的训练数据是提升大语言模型推理能力的基础。然而,由于人工标注成本高昂,大规模的高质量数据难以获取。现有研究表明,合成数据可以作为一种高效的替代方案。但目前开源合成数据在数据质量和数据多样性上仍存在不足,进而导致随着训练数据规模的扩大,模型的训练效果难以持续稳定提升。
我们提出了一种新的数据生成方法ScaleQuest,生成的数据有以下优势:
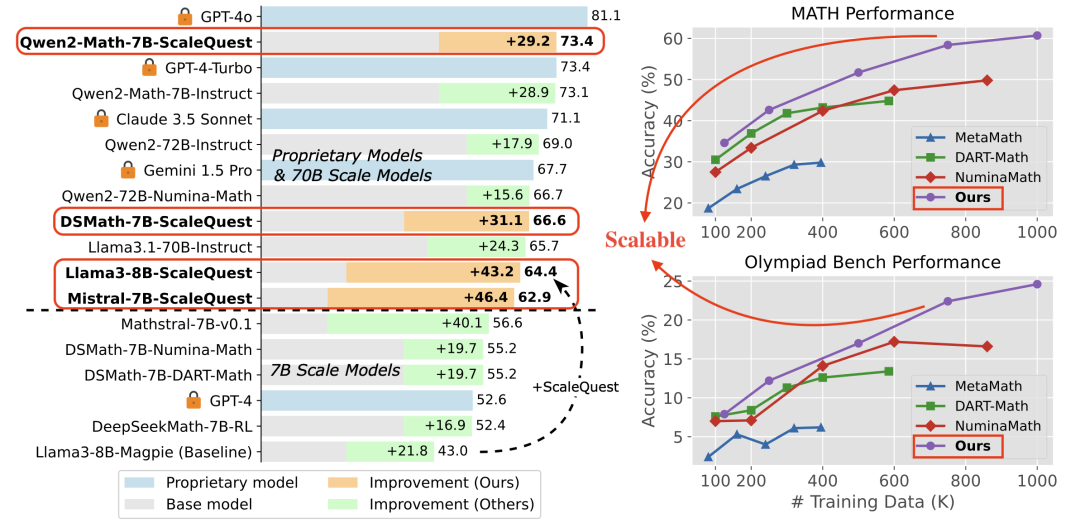
可扩展性强:如图1右图所示,随着训练数据的扩大,模型性能持续提升。和现有的开源数据集相比,突破了合成数据scaling瓶颈。并且随着数据规模继续scaling,模型效果有望达到GPT-4o同等效果甚至有超越的潜力。
经济高效:解锁了小模型进行数据合成的潜力。整个数据合成过程只使用了开源7B小模型和少量问题样本,整套流程约522.9GPU hours (A100-40G-PCIe,8卡服务器约3天),以非常小的成本合成了高质量的数据。
数据质量高:我们7B规模的模型超过了GPT-4和很多70B规模的模型,达到GPT-4-Turbo的水平(如图1左图所示)。值得一提的是,我们的开源训练数据比闭源数据达到的效果更好。
合成数据的scaling瓶颈
一个高质量的问题对模型的提升至关重要,也是很多数据合成工作的着力点(比如MetaMathQA[1], MAmmoTH[2])。现有的合成数据方法通常基于有限的预设问题和知识生成新问题。然而,随着数据规模的扩大,这种生成方式逐渐暴露出局限性,导致生成的问题趋于重复和同质化,降低了数据的多样性。结果是,随着训练数据的不断扩展,模型性能难以持续提升,形成了扩展瓶颈(scaling bottleneck)。
这些限制成为模型生成的束缚。为了解决这一问题,我们尝试去除模型生成过程中的限制,鼓励模型开放式地生成问题。实现上,我们发现仅仅给模型提供一个“<bos>”词元就可以让模型逐词生成一个问题(做法上和Magpie[3]类似)。进一步的,我们认为现有模型具备丰富的专业知识来解决问题,因此也可以利用这些内在知识提出新问题。然而模型自身尚不具备这一能力,于是我们提出了一套方案来激发模型的问题自生成能力。
数据合成方法ScaleQuest
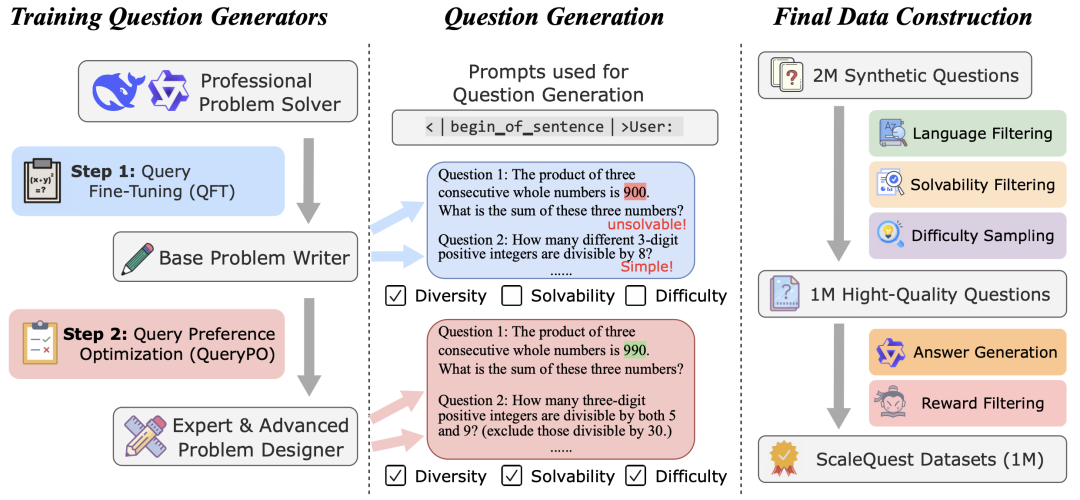
ScaleQuest首先通过QFT和QPO训练出一个问题生成器,然后利用这些生成器进行开放式问题采样,并对生成的问题进行进一步筛选,最终基于筛选出的高质量问题生成相应的解答。
问题微调 (Question Fine-Tuning, QFT)
为了激活模型的问题生成能力,我们首先进行问题微调(QFT),即使用一小部分问题对现有模型进行训练。基于DeepSeekMath-7B-RL和Qwen2-Math-7B-Instruct,我们训练了两个问题生成器,使用了来自GSM8K和MATH训练集的约15,000道问题。在此过程中,我们验证了模型是激发其问题生成能力,而非简单记忆训练中的问题。具体来说,我们用两个差异很大的问题集来分别训练相同的模型,发现无论使用哪个子集进行训练,模型最终生成的问题都趋于同一个难度分布。
问题偏好优化(Question Preference Optimization, QPO)
我们进一步通过偏好微调(QPO)优化了这两个问题生成器,重点关注问题的可解性(solvability)和难度(difficulty)。ScaleQuest使用经过QFT训练后的模型生成问题集合,并通过GPT-4o-mini对问题的可解性和难度进行进一步优化。优化后的问题作为,源问题作为,构建偏好对。我们去掉DPO[4]的损失中的conditional的部分,得到QPO的优化目标为:
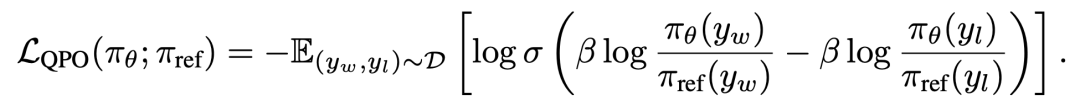
问题筛选
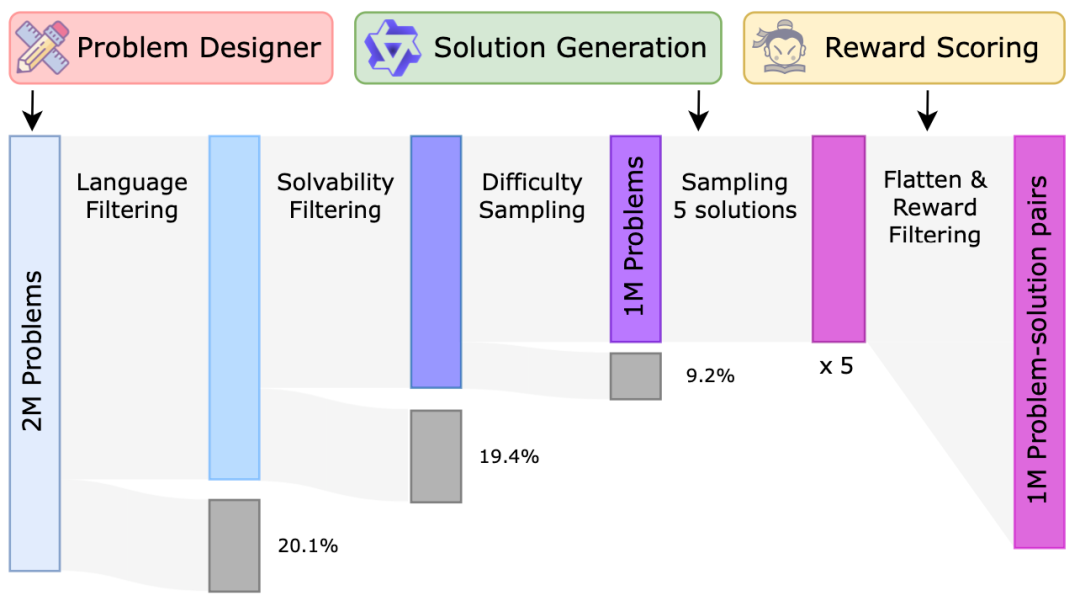
在完成QFT和QPO阶段后,我们得到了两个问题生成器:DeepSeekMath-QGen 和 Qwen2-Math-QGen。然而,生成的问题仍存在一些小问题,因此我们采用了筛选方法进行处理,包括语言筛选、可解性筛选和难度采样。
语言筛选: 问题生成模型仍然会生成大量其他语言的数学问题,约占 20%。由于我们的重点是英文数学问题,因此我们通过识别包含非英文字符的问题并筛除这些样本,来去除非英文问题。
可解性筛选: 尽管 QPO 有效地提升了生成问题的可解性,但仍有一些问题不合逻辑。主要原因包括:(1) 问题约束不完善,出现缺失条件、冗余条件或逻辑不一致的情况,(2) 问题没有产生有意义的结果(例如,涉及人数的问题应得到非负整数作为答案)。为筛除此类样本,我们使用 Qwen2-Math-7B-Instruct 评估问题是否有意义以及条件是否充分。
难度采样: 我们基于DeepSeekMath-7B训练了一个难度打分器模型,然后去除生成数据中难度很低的一些样本。
回答生成与奖励筛选
我们使用Qwen2-Math-7B-Instruct生成回答,并将奖励模型的评分作为评估回答质量的指标。从5个候选回答中选择奖励评分最高的回答,作为最终的回答。
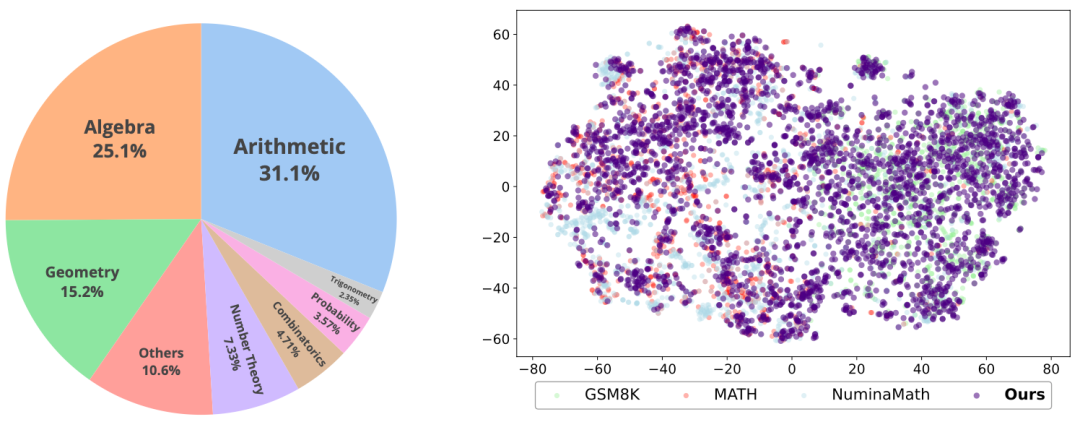
如图4所示,我们展示了整个数据构建流程的示意图。最终,ScaleQuest生成了约一百万条训练数据。经过分析(见图5),我们发现数学问题在各类别间分布广泛且较为均衡。与现实标注数据集如GSM8K和MATH相比,ScaleQuest的覆盖面也很全面。
实验结果
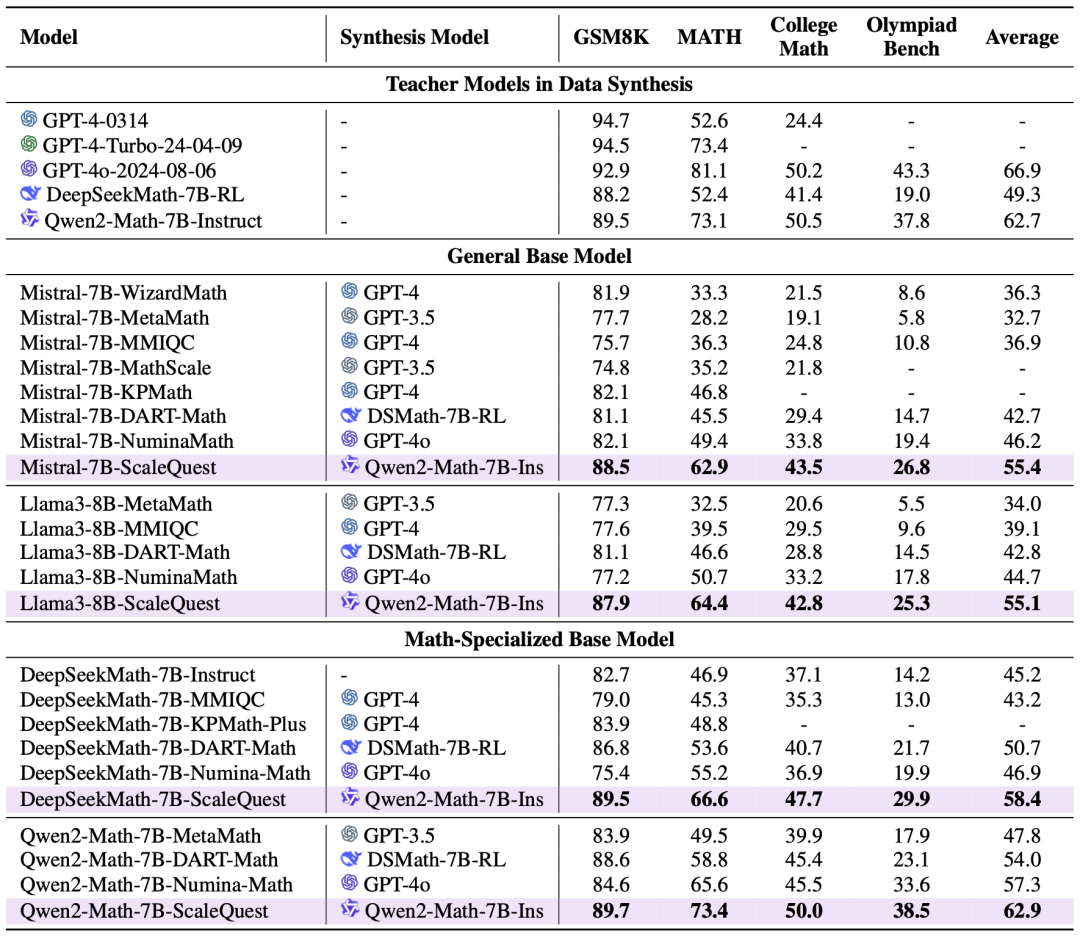
我们的评测涵盖了两个通用大模型(Mistral-7B和Llama3-8B)以及两个数学专用模型(DeepSeekMath-7B和Qwen2-Math-7B)。评估过程涉及从基础到高级的多个难度层次,包括广泛使用的GSM8K(小学水平)和MATH(竞赛水平),以及更具挑战性的College Math(大学水平)和Olympiad Bench(奥林匹克水平)基准测试。所有列出的结果均基于0-shot pass@1 CoT设置。
结果如图6所示。ScaleQuest显著优于以往的合成方法,在通用基础模型和数学专用基础模型上,平均性能提升范围为5.6%至11.5%。Qwen2-Math-7B-ScaleQuest在MATH基准测试中实现了73.4的准确率,与GPT-4-Turbo的表现相当。在域外任务中,Qwen2-Math-7B-ScaleQuest超越了其教师模型 Qwen2-Math-7B-Instruct,展现出了自增强(self-improvement)能力。值得注意的是,Qwen2-Math-7B-Instruct 使用了Qwen2-Math-RM-72B进行群体相对策略优化(Group Relative Policy Optimization, GRPO),而我们的模型仅是一个指令微调版本。
分析
消融实验
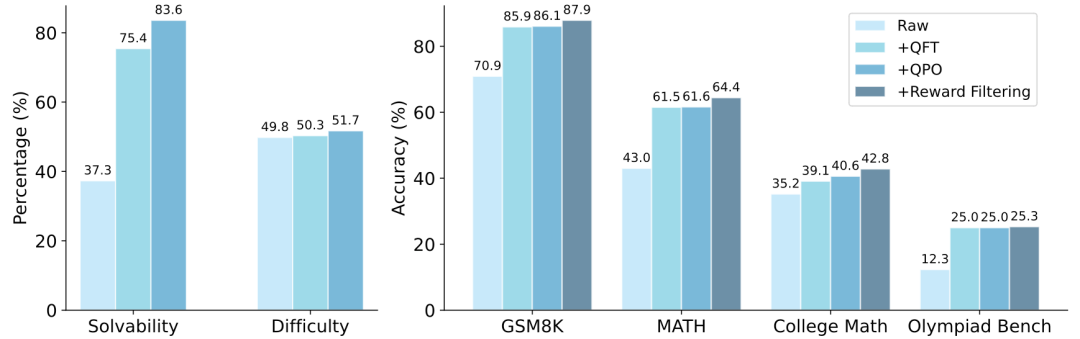
首先,为了验证我们各个子方法(包括QFT、QPO和奖励筛选)的有效性,我们进行了消融实验。我们从三个维度评估了模型生成问题的质量:可解性、难度以及在指令微调中的表现。结果如图7所示,在三个评估维度上,我们的方法都有有效的提升。
多个问题生成器有助于提高合成数据的多样性
为了探讨使用多个问题生成器的影响,我们对比了单一生成器生成的数据与两者混合生成的数据的效果。我们将数据集总规模固定为40万,并使用这些数据对Mistral-7B进行微调。正如图8所示,混合数据的表现优于单个生成器生成的数据。可能的解释是混合数据增加了数据的多样性。事实上,我们观察到DSMath-QGen倾向于生成较为简单、贴近现实的问题,而Qwen2-Math-QGen则更偏向生成具有挑战性、理论驱动的问题。

成本分析
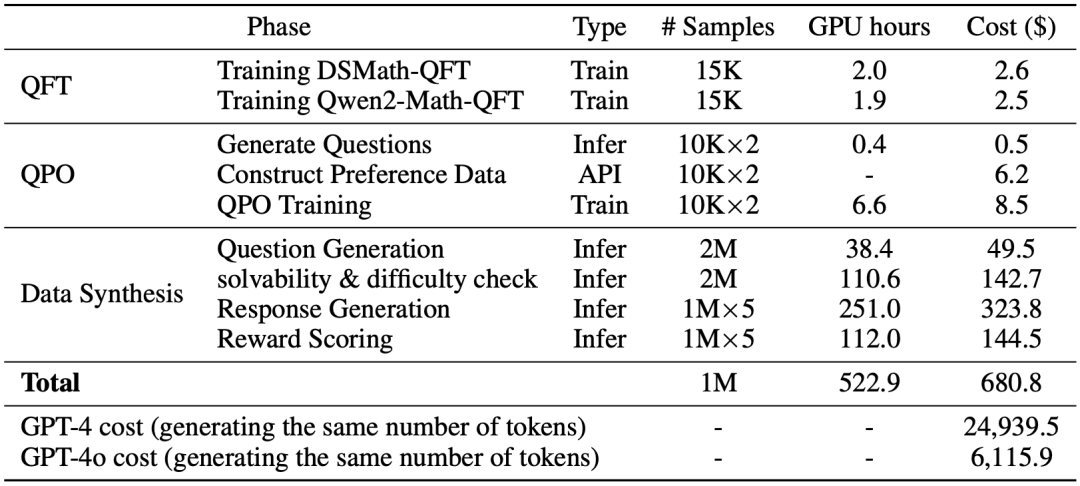
数据合成过程是在配备8块A100-40G-PCIe GPU的服务器上进行的。我们在图9中总结了整体成本。生成100万个数据样本仅耗费了522.9个GPU小时(约合8 GPU服务器上的 2.7天),预计云服务器租赁费用为680.8美元。这仅为使用 GPT-4o生成相同数据成本的约10%。这表明,我们的数据生成方法在成本效益上显著优于其他方法。
未来展望
大规模且多样化的高质量数据:我们选择了数学推理作为案例研究,来展示我们方法的有效性。未来,我们将关注更广泛且更复杂的任务,例如编程竞赛和科学问题。此外,我们未来的研究还将致力于不断扩展数据合成的规模,以进一步探索合成数据的扩展规律,并寻求一种更高效的数据生成扩展方法。
自我提升能力:我们的实验表明模型具有自我提升的能力,即模型能够生成比其原始训练集质量更高的数据。这一点在Qwen2-Math-7B-ScaleQuest略微优于Qwen2-Math-7B-Instruct中有所体现。为了进一步探索自我提升的上限,未来的研究将重点在于合成偏好微调数据,以更好地对齐大型语言模型(LLMs)。
参考资料
[1]
MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models: https://arxiv.org/abs/2309.12284,
[2]MAmmoTH: Building Math Generalist Models through Hybrid Instruction Tuning: https://arxiv.org/abs/2309.05653,
[3]Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing: https://arxiv.org/abs/2406.08464,
[4]Direct Preference Optimization: Your Language Model is Secretly a Reward Model: https://arxiv.org/abs/2305.18290,
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦

















 1425
1425

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









