






腾讯AI Lab和上交发现在面对一个基本的算术问题“2+3=?”时,o1类LLMs为何会表现出过度思考的现象。这个问题虽然简单,但它揭示了当在处理复杂任务时,这些模型是否真正高效和智能。下面一起深入剖析下这篇文章的内容吧,很有意思的。
论文:Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs
链接:https://arxiv.org/abs/2412.21187
作者:Wzl
来自:深度学习自然语言处理
动机
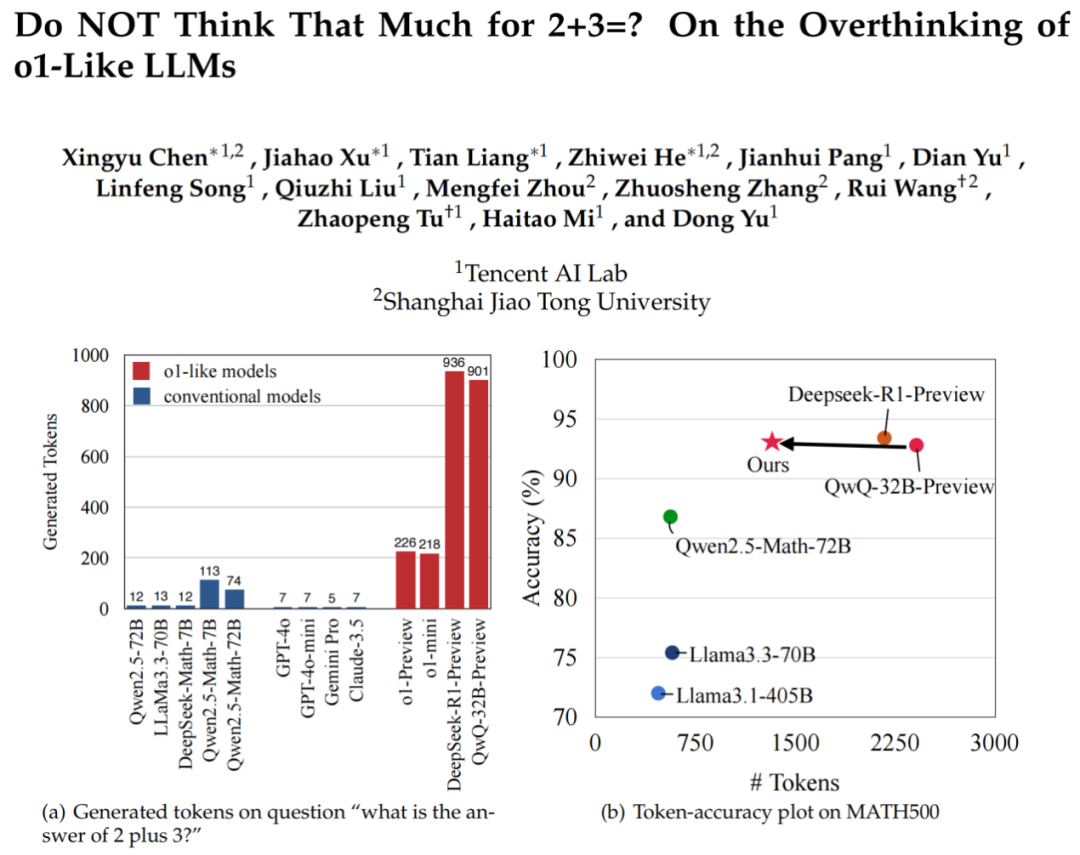
目前o1类的LLM会探索多种策略,分解复杂的步骤等去增强处理复杂推理任务的能力,这些对问题的探索和拆解会生成比较长的思维链。这依赖于scaling test-time compute,也就是分配了更多的资源在推理阶段以提高任务的准确率。但是,目前的scaling test-time compute是否是高效并且智能呢? 并不是。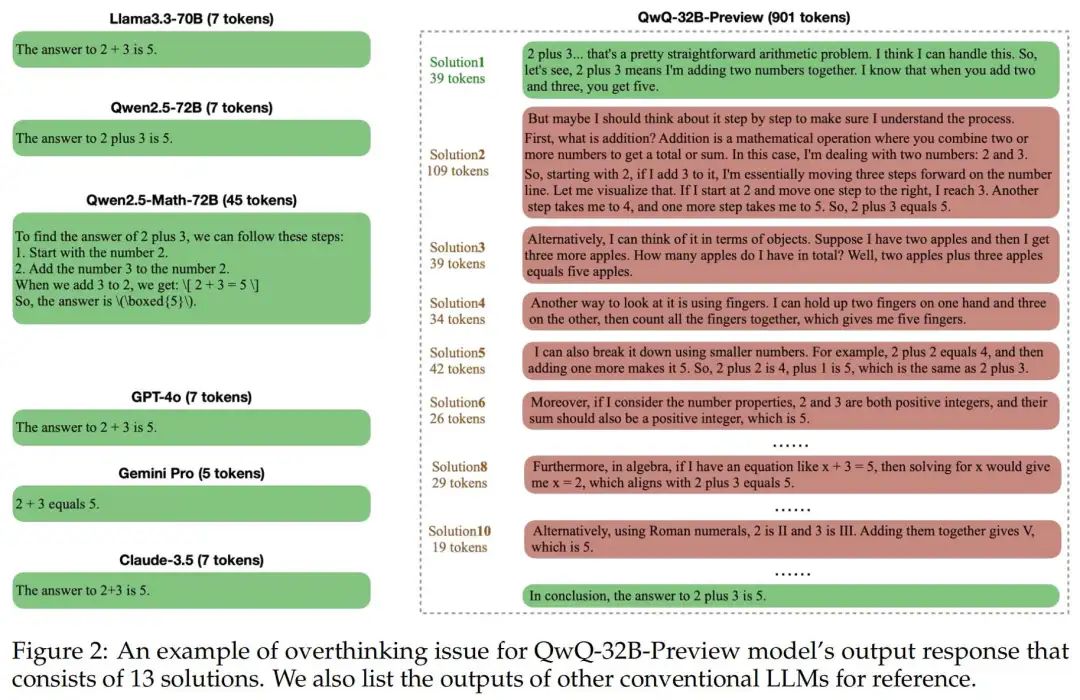 作者观察到o1类模型存在明显的“过度思考”的问题,对简单的2+3=?o1类模型相比基础模型的token消耗是1,953%, 因此作者希望通过self-training的范式去缓解这个问题。
作者观察到o1类模型存在明显的“过度思考”的问题,对简单的2+3=?o1类模型相比基础模型的token消耗是1,953%, 因此作者希望通过self-training的范式去缓解这个问题。
关于“过度思考”的观察
1)o1 类模型往往会对更简单的数学问题生成更多轮的solution(但其实很多轮的solution中都包含了最终的答案,往往不需要那么多轮的solution)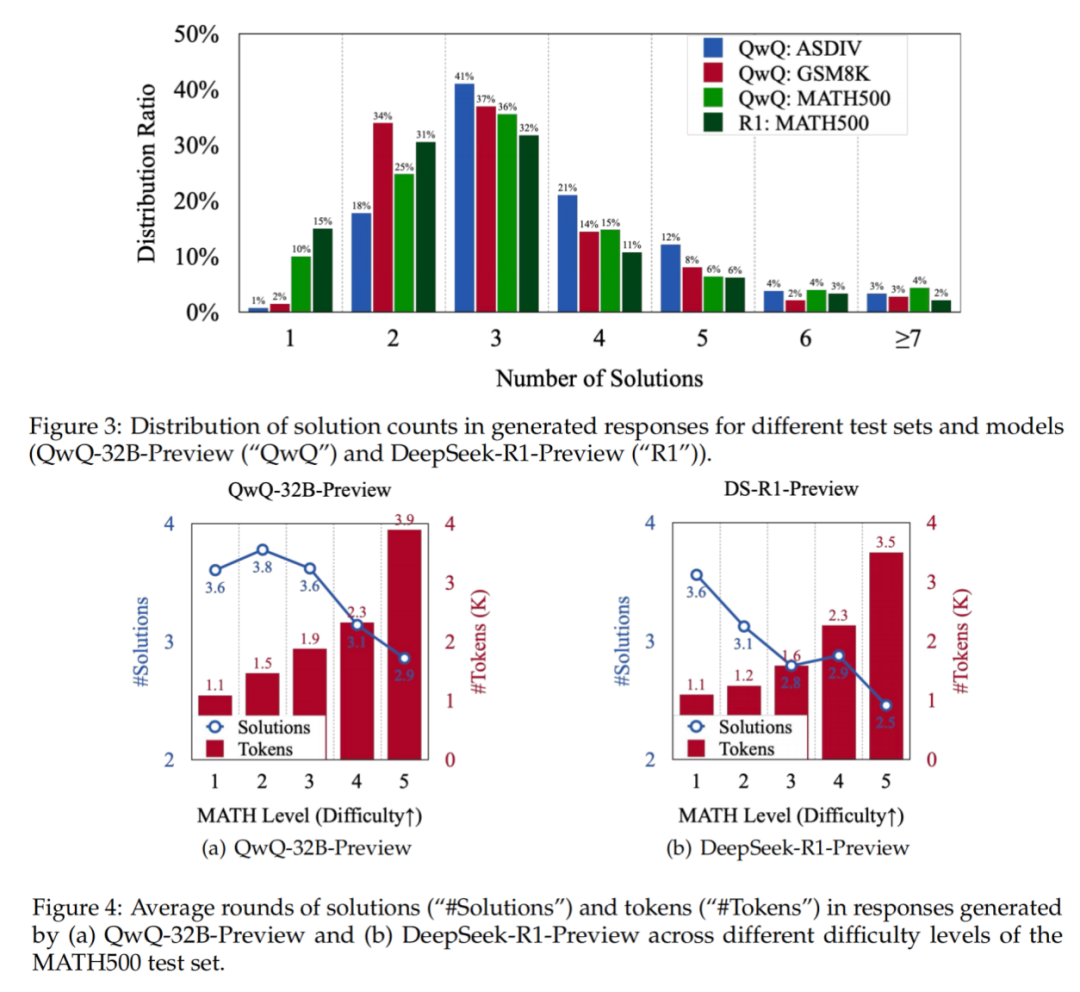 2)越后面的solution对准确率的提升微弱。
2)越后面的solution对准确率的提升微弱。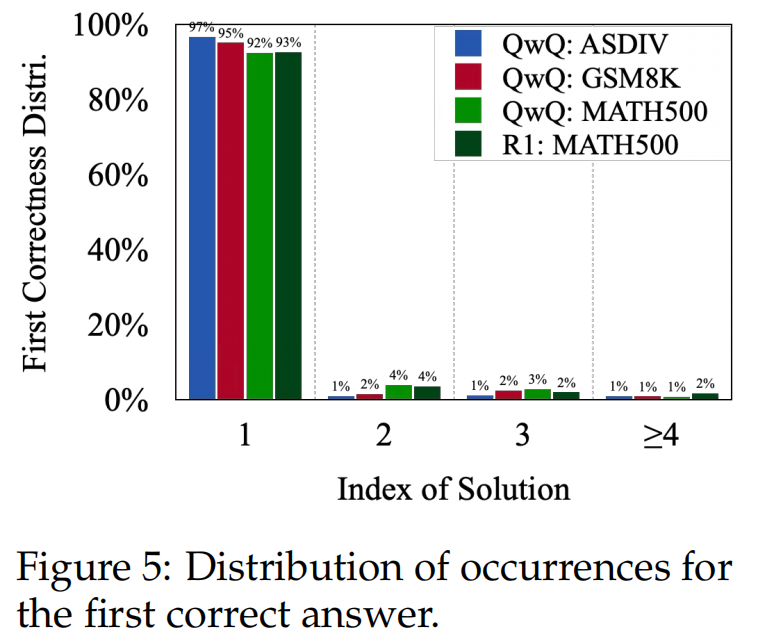 3)后面的solution经常重复前面的(多样性不高)。
3)后面的solution经常重复前面的(多样性不高)。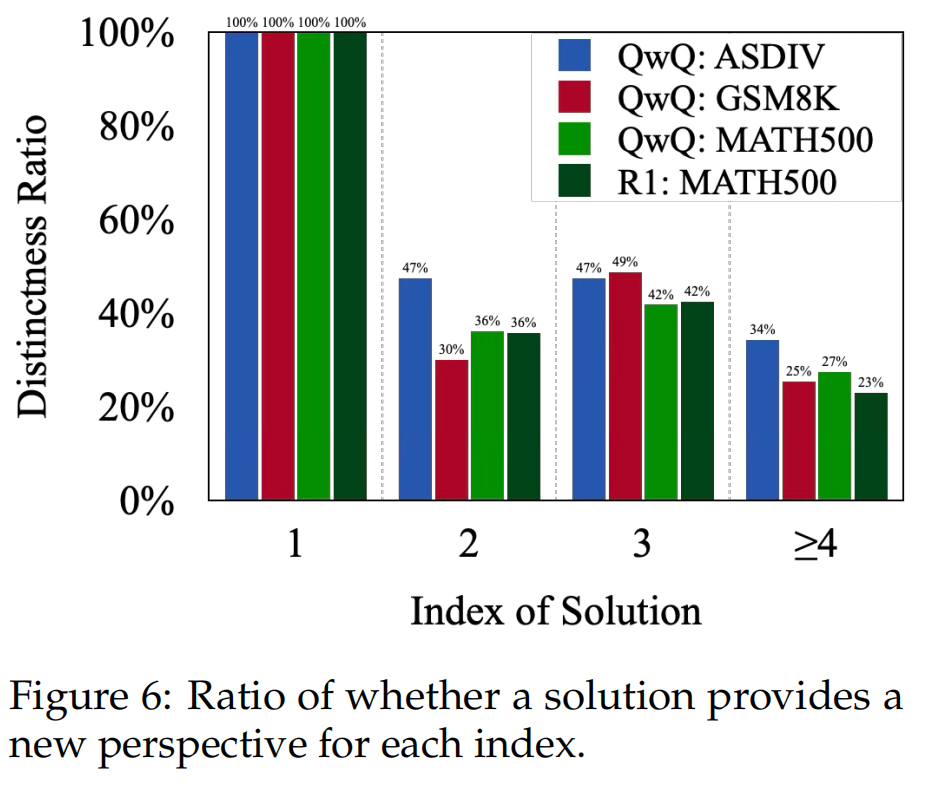 由2)3)观察,作者提出两个评估指标:
由2)3)观察,作者提出两个评估指标:
Outcome Efficiency Metric:第一个回答对的solution对应token数/总token。
Process Efficiency Metric:每个solution中有效增加多样性(不同角度)的token数之和/总token。

 在三个数据集上,测试了o1类模型(QWQ-32B-preview、DeepSeek-R1-preview)与非o1类模型(Llama-3.3-70B-Instruct、Qwen2.5-Math-72B-Instruct)在这两个指标上的表现。
在三个数据集上,测试了o1类模型(QWQ-32B-preview、DeepSeek-R1-preview)与非o1类模型(Llama-3.3-70B-Instruct、Qwen2.5-Math-72B-Instruct)在这两个指标上的表现。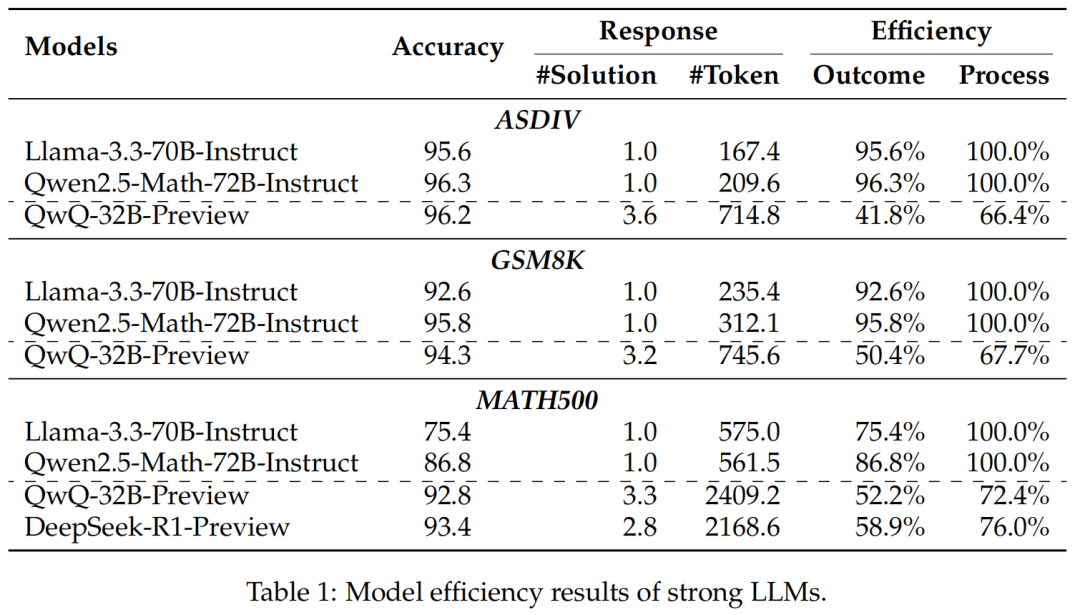 对MATH-500结果在不同难度段的Outcome Efficiency和Process Efficiency分析,发现o1类模型对于更简单的数学问题“过度思考问题”尤其明显。
对MATH-500结果在不同难度段的Outcome Efficiency和Process Efficiency分析,发现o1类模型对于更简单的数学问题“过度思考问题”尤其明显。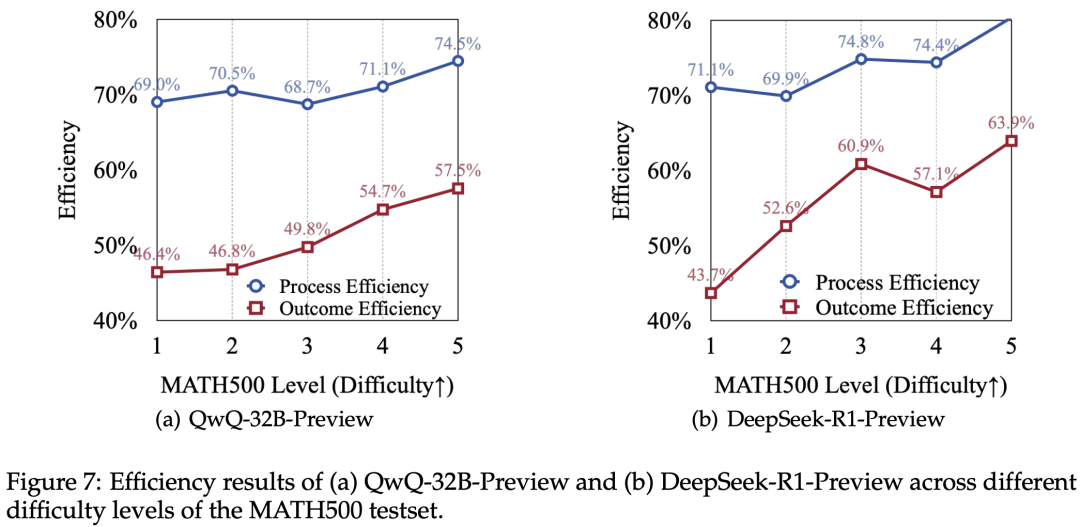
缓解“过度思考”的方法
作者使用PRM12K数据让模型自己生成训练数据,探究了:1)分别用SFT、DPO、RPO、SimDPO进行post-training 2)First-Correct Solutions (FCS)、FCS + Reflection、Greedily Diverse Solutions (GDS)去进一步简化回复。通过实验证明有效缓解了“过度思考”。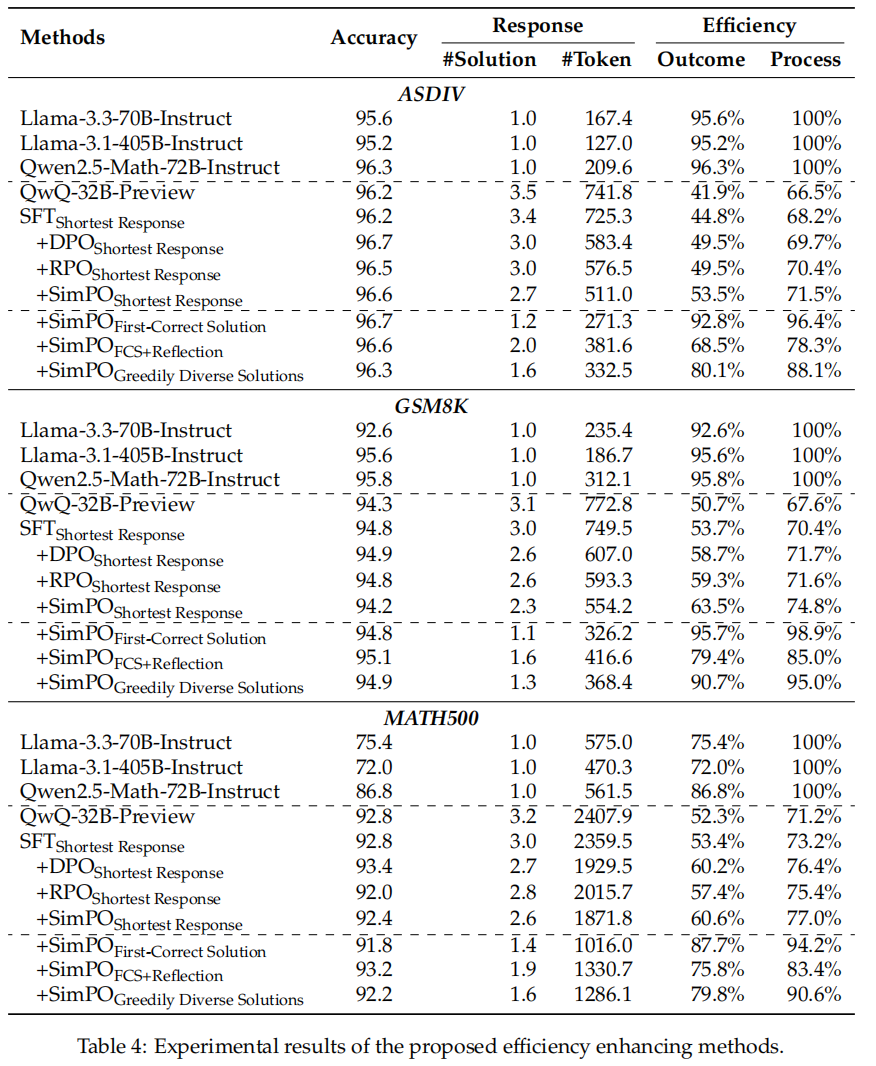
思考
文章重点在观察和发现“过度思考”的现象,很自然的提出两个评估指标,并通过现有的方法,以及提出几个进一步的优化策略去解决。
论文读起来很清晰,挺有意思的,值得一读。
还有很多点可以继续探究,如何找到scaling test-time compute在efficiency和performance的最佳平衡。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦

















 931
931

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









