







终于Kimi又更新了!期待已久
说是已经在灰度了: 但是我的界面还是这样,再等等吧,一会试试~
但是我的界面还是这样,再等等吧,一会试试~
我们先一起读读论文看看技术细节有啥变化吧。
地址:https://github.com/MoonshotAI/Kimi-k1.5/blob/main/Kimi_k1.5.pdf
大语言模型(LLM)的预训练方法已经证明了其在扩展计算上的有效性,但受限于可用训练数据的量。
强化学习(RL)为AI的持续改进提供了新方向,能让LLM通过奖励机制探索更多数据,但此前的研究成果并不理想。
Kimi k1.5团队另辟蹊径,提出了一个简洁有效的RL框架,不依赖复杂的蒙特卡洛树搜索、价值函数和过程奖励模型等技术。
通过长文本上下文扩展、改进的策略优化方法,Kimi k1.5在多个基准测试中达到了与OpenAI的o1相当的推理性能,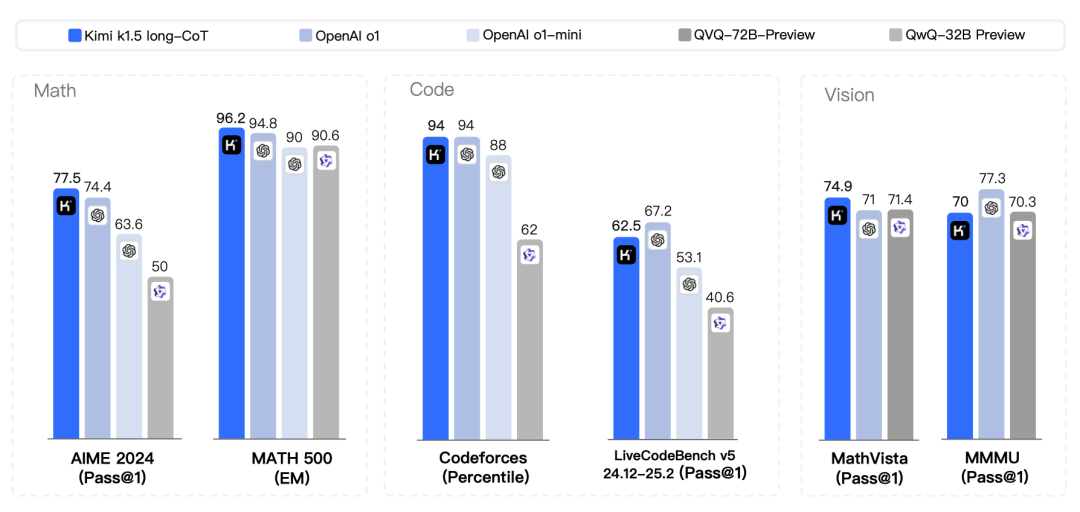 还通过“长转短”方法提升了短文本推理模型的性能,最高超出现有模型550%。
还通过“长转短”方法提升了短文本推理模型的性能,最高超出现有模型550%。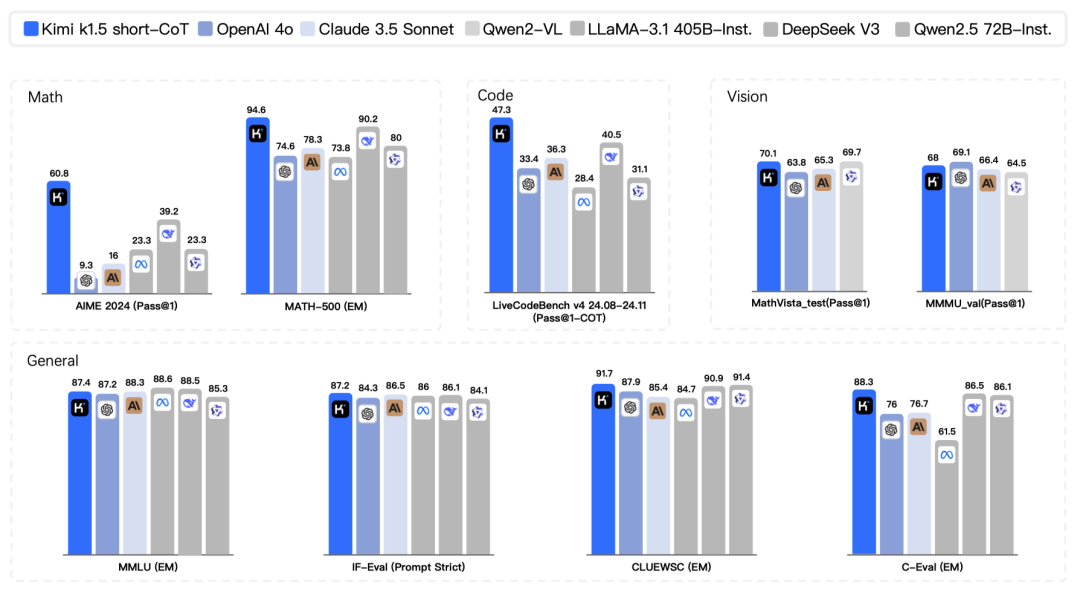
方法细节
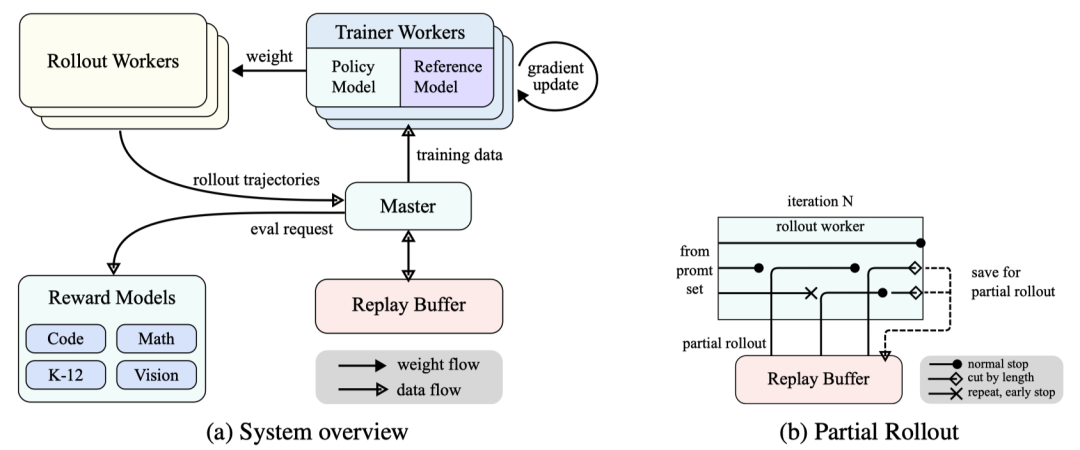
长上下文扩展
Kimi k1.5将强化学习的上下文窗口扩展到128k,发现随着上下文长度增加,性能持续提升。团队采用了部分轨迹回放技术,通过重用之前轨迹的大块内容来生成新轨迹,避免从头开始生成新轨迹的成本,有效提高了训练效率。这种长上下文扩展让模型能够更好地规划、反思和纠正推理过程,就像给模型装上了“千里眼”,让它能看到更远的“未来”,从而做出更合理的决策。
改进的策略优化
团队提出了一个基于在线镜像下降的变体算法,用于鲁棒的策略优化。这个算法通过有效的采样策略、长度惩罚和数据配方优化来进一步提升性能。简单来说,就是让模型在训练过程中更加“聪明”,知道哪些地方需要重点学习,哪些地方可以稍微“偷懒”,同时避免生成过于冗长的推理过程,提高了模型的效率和准确性。
多模态训练
Kimi k1.5是一个多模态模型,能够同时处理文本和视觉数据。这种多模态训练方式让模型在处理问题时可以综合考虑多种信息,比如在解答一道包含图表的数学题时,模型不仅能理解文字描述,还能“看懂”图表,从而更准确地给出答案。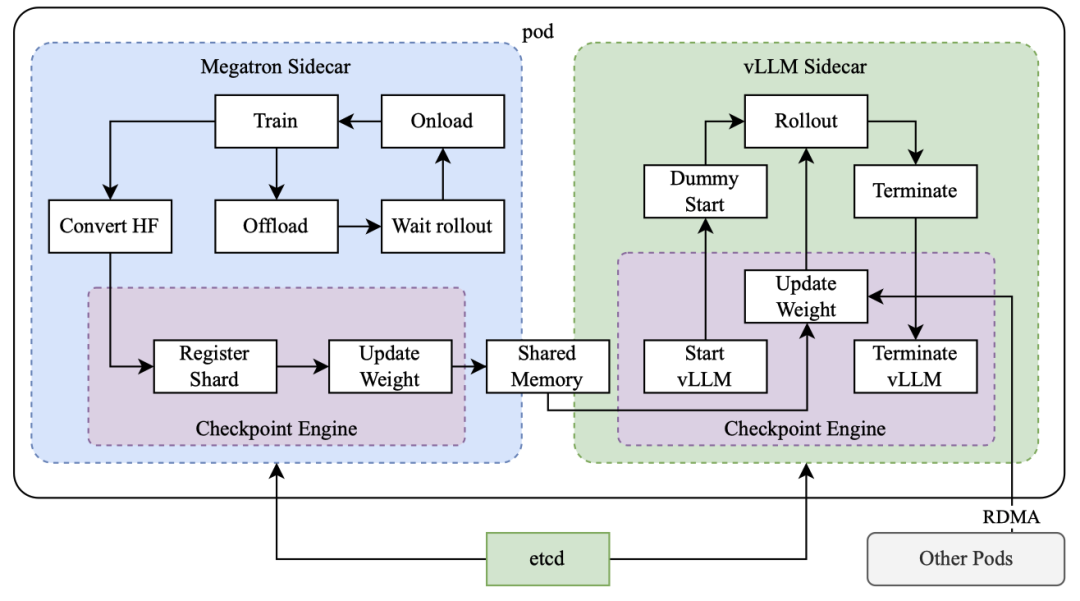
实验结果
长文本推理性能
Kimi k1.5的长文本推理版本在多个基准测试中表现出色,例如在AIME 2024中达到了77.5的通过率,在MATH 500中达到了96.2的准确率,在Codeforces中达到了94百分位,与OpenAI的o1相当,甚至在某些任务上超过了现有的其他模型。这说明Kimi k1.5在处理复杂推理任务时已经达到了顶尖水平。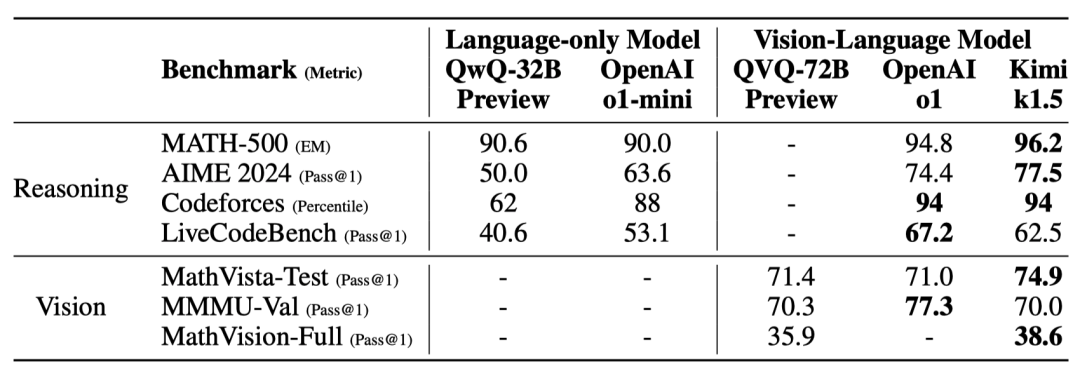
短文本推理性能
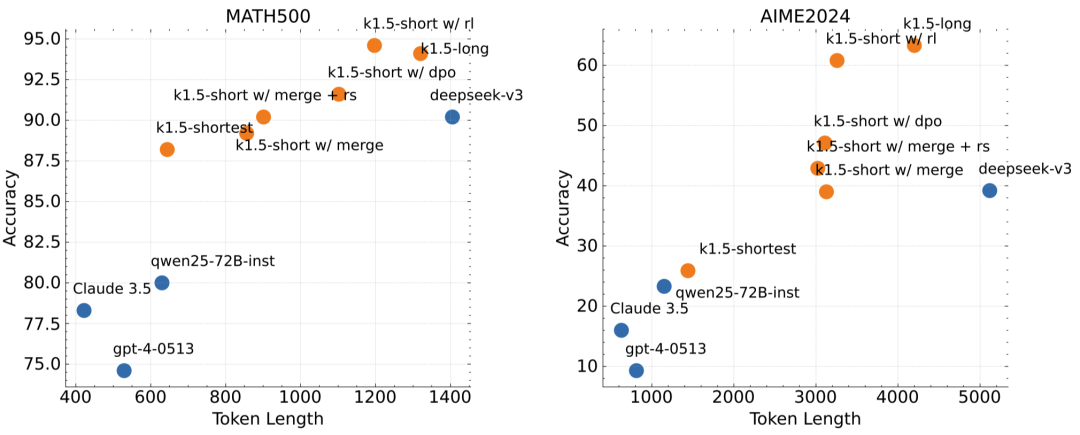 通过“长转短”方法,Kimi k1.5的短文本推理版本也取得了显著的性能提升。例如在AIME 2024中达到了60.8的通过率,在MATH 500中达到了94.6的准确率,在LiveCodeBench中达到了47.3的通过率,大幅领先于GPT-4o和Claude Sonnet 3.5等现有短文本推理模型。这表明Kimi k1.5不仅在长文本推理上表现出色,还能通过技术手段将这种优势转化为短文本推理能力,让模型在不同场景下都能发挥强大的推理能力。
通过“长转短”方法,Kimi k1.5的短文本推理版本也取得了显著的性能提升。例如在AIME 2024中达到了60.8的通过率,在MATH 500中达到了94.6的准确率,在LiveCodeBench中达到了47.3的通过率,大幅领先于GPT-4o和Claude Sonnet 3.5等现有短文本推理模型。这表明Kimi k1.5不仅在长文本推理上表现出色,还能通过技术手段将这种优势转化为短文本推理能力,让模型在不同场景下都能发挥强大的推理能力。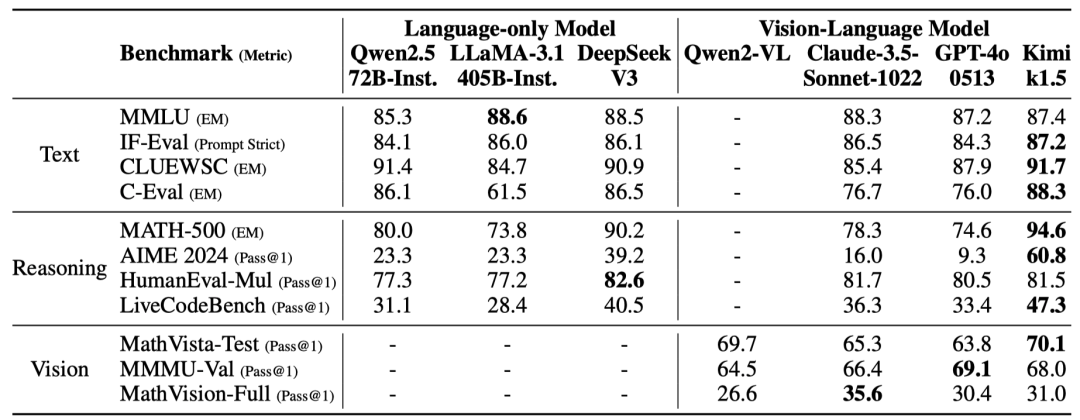
结论
Kimi k1.5通过长上下文扩展和改进的策略优化方法,在强化学习框架下实现了高效的训练,并且在多模态推理任务中取得了与OpenAI的o1相当甚至更优的性能。未来,团队将继续探索如何进一步提高长上下文强化学习训练的效率和可扩展性,同时研究如何更好地将长文本推理能力转化为短文本推理能力,让模型在更多场景下都能发挥出强大的性能。
一会定要试一试~ 嘿嘿~
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









